【速览】NeurIPS 2021 | 双流图像表征网络(Dual-stream Network)
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
双流图像表征网络(Dual-stream Network)
*通讯作者:Baochang Zhang,Shumin Han
◆ ◆ ◆ ◆
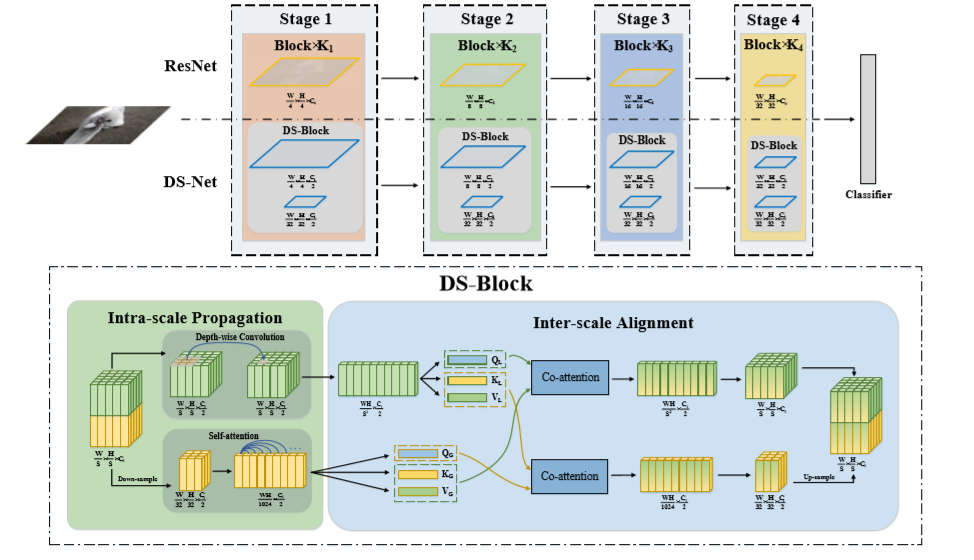
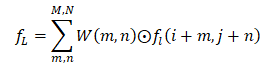
其中
自注意力分支:对于低分辨率特征
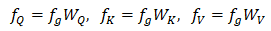
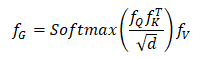
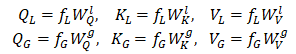
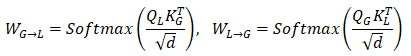
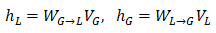
然后重新将
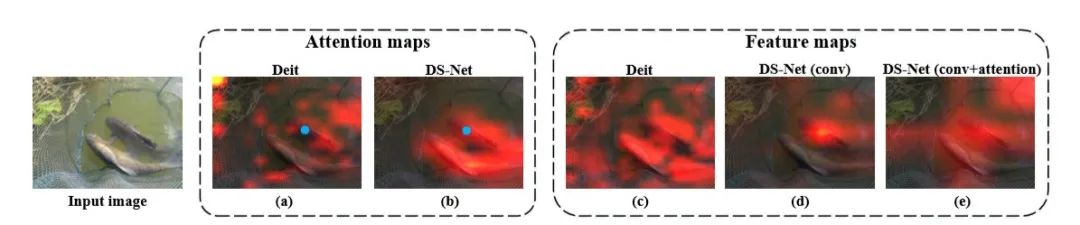
图 2 DeiT和DS-Net注意力权重图和特征图比较
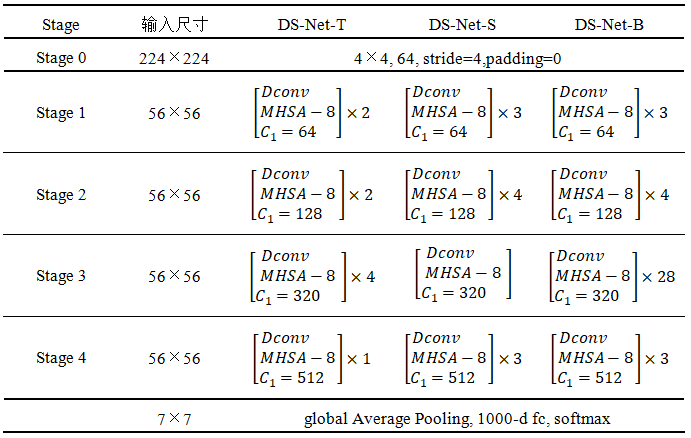
DS-Net目前提出三种大小的模型结构,即DS-Net-T、DS-Net-S和DS-Net-B:
表 1 DS-Net的参数设置
DS-Net在分类、检测和分割任务上明显优于其他算法,实验结果如下:
表 2 ImageNet-1k分类实验
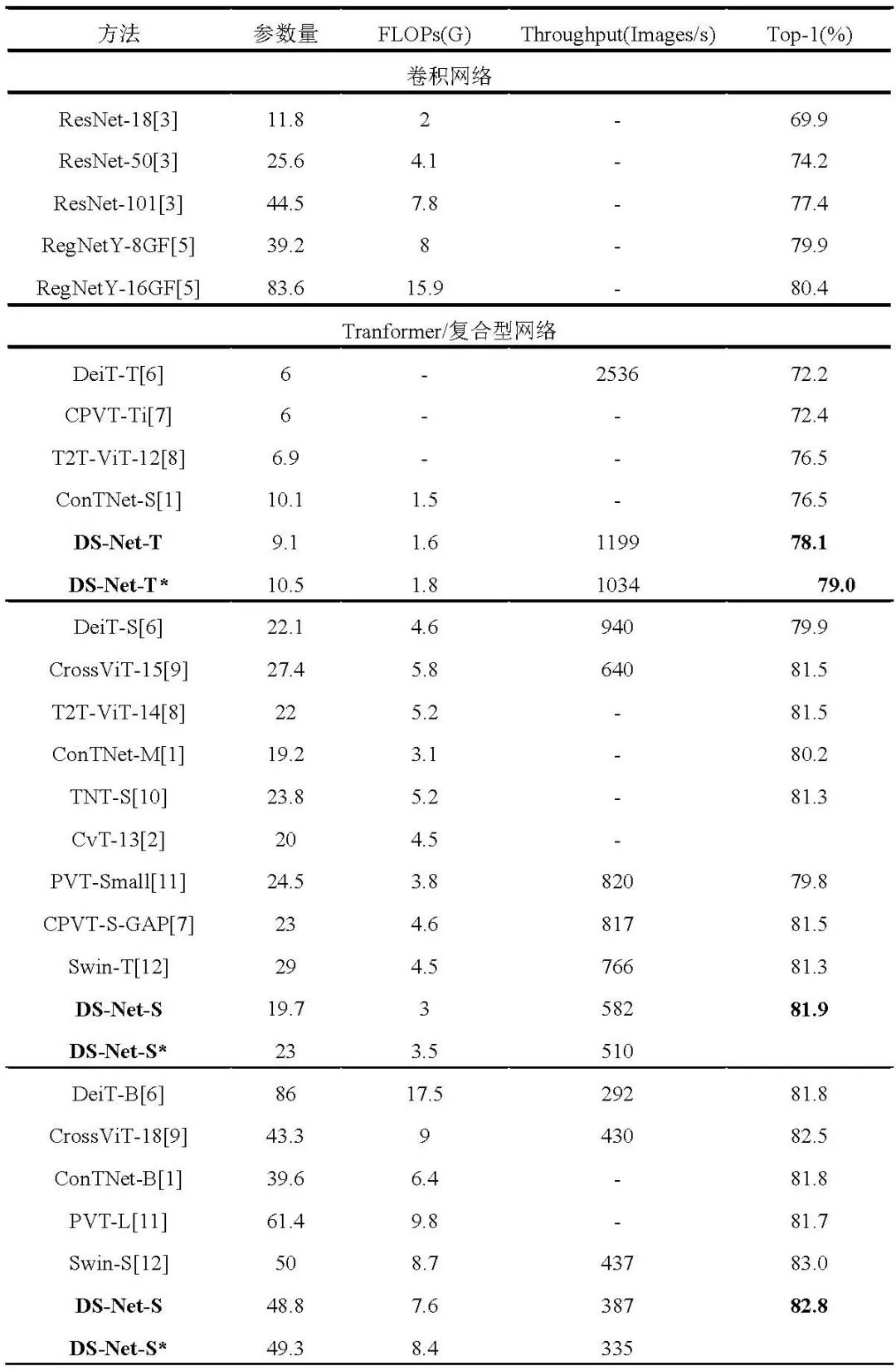
表 3 COCO数据集检测和分割实验
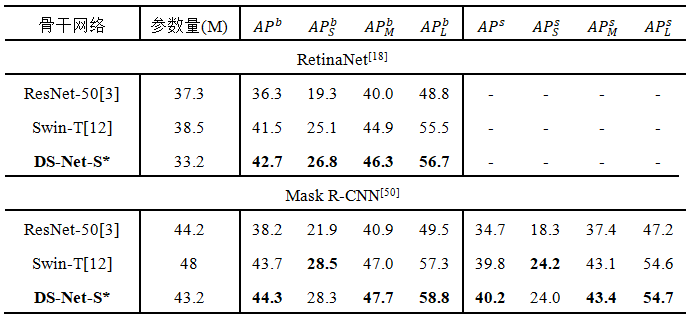
对于下游的检测和分割任务,DS-Net将双分辨率机制引入FPN,建立DS-FPN,以此引入更加丰富的局部和全局信息,实验证明DS-FPN可以有效提高检测器的性能
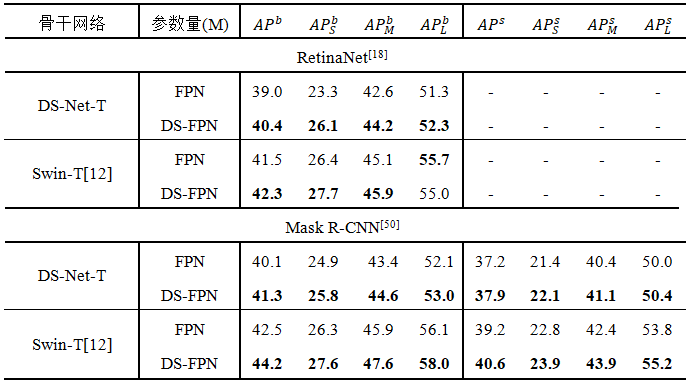
[1] Yan H, Li Z, Li W, et al. ConTNet: Why not use convolution and transformer at the same time[OL]. arXiv preprint: 2104.13497, 2021.
[2] Wu H, Xiao B, Codella N, et al. CvT: Introducing Convolutions to Vision Transformers[OL]. arXiv preprint: 2103.15808, 2021.
[3] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 770-778.
[4] Howard A. G, Zhu M, Chen B, D. et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[OL]. arXiv preprint: 1704.04861, 2017.
[5] Radosavovic I, Kosaraju R. P, Girshick R, et al. Designing Network Design Spaces[C]. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020: 10425-10433.
[6] Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention[OL]. arXiv preprint: 2012.12877, 2021.
[7] Chu X, Tian Z, Zhang B, et al. Conditional Positional Encodings for Vision Transformers[OL]. arXiv preprint: 2102.10882, 2021.
[8] Yuan L, Chen Y, Wang T, et al. Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet[OL]. arXiv preprint: 2101.11986, 2021.
[9] Chen C, Fan Q, Panda R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification[C]. In Proceedings of International Conference on Computer Vision, 2021: 357-366.
[10] Han K, Xiao A, Wu E, et al. Transformer in Transformer[OL]. arXiv preprint: 2103.00112, 2021.
[11] Wang W, Xie E, Li X, et al. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions[C]. In Proceedings of the IEEE International Conference on Computer Vision, 2021: 568-578.
[12] Liu Z, Lin Y, Cao Y, et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows[C]. In Proceedings of the IEEE International Conference on Computer Vision, 2021: 10012-10022.






