Christopher Manning:Transformer 语言模型何以取得如此突破?

早期基于概率统计、无法学习语言结构的黑暗时代(Language Models in The Dark Ages);
之后则是启蒙时代的神经语言模型(Enlightenment era neural Language Models),特点是具备一定学习语言结构的能力;
-
2018年始,基于Transformer结构的大参数量预训练模型(Big Language Models)大行其道。
语言模型:用数学给语言建模

黑暗时代:N-Gram语言模型

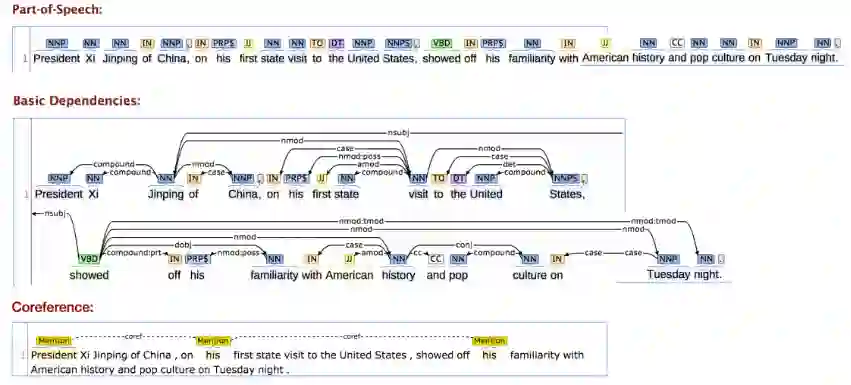
启蒙时代:
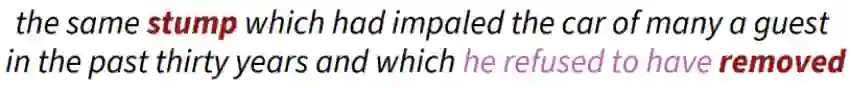
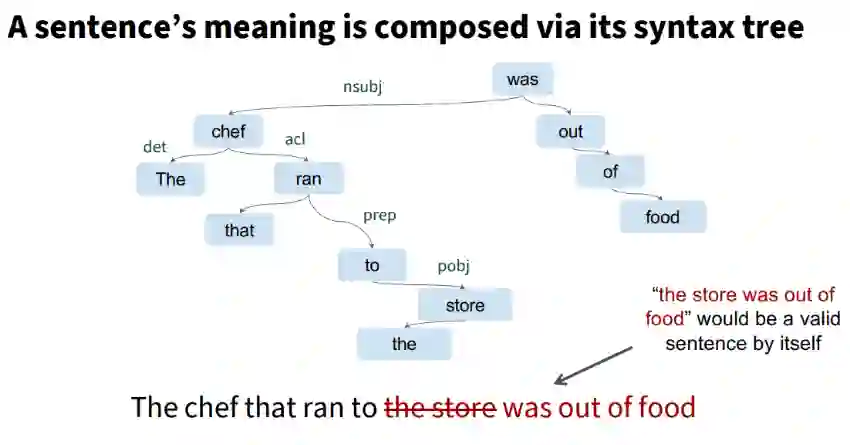
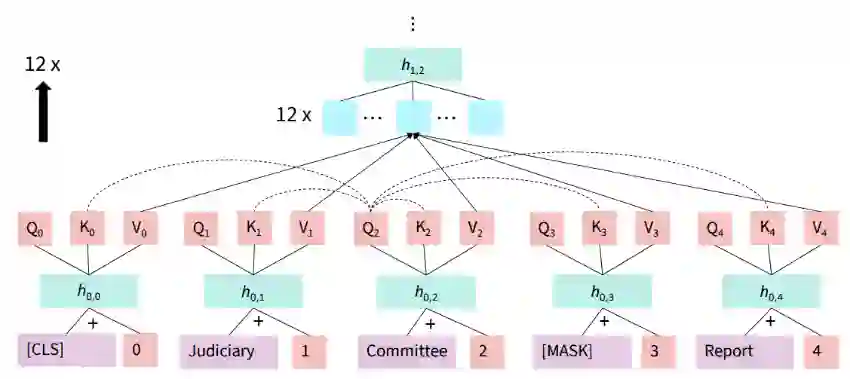
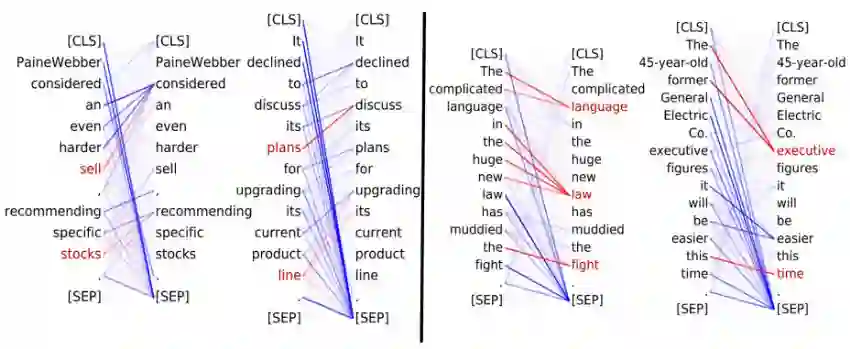
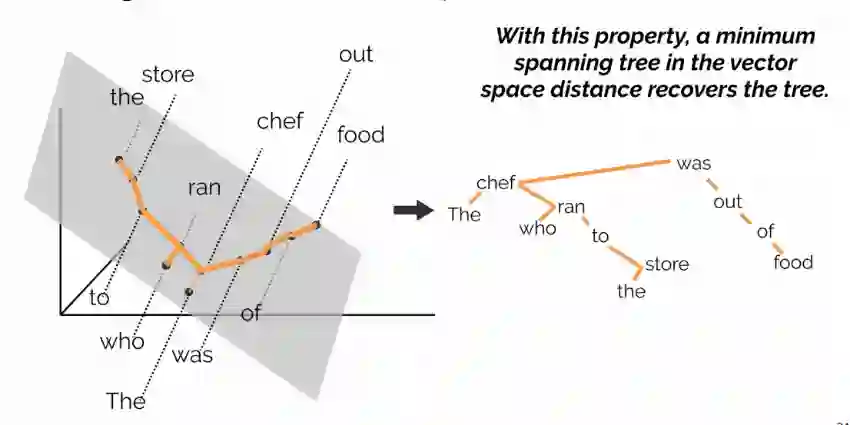
大模型时代:






登录查看更多
相关内容
专知会员服务
79+阅读 · 2019年12月29日
Arxiv
7+阅读 · 2018年5月25日




相关VIP内容
专知会员服务
79+阅读 · 2019年12月29日
相关资讯
相关论文
Arxiv
7+阅读 · 2018年5月25日