LS-Net:单双目视觉的非线性最小二乘学习算法
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货

在本文中,我们提出了最小二乘网络,一种神经非线性最小二乘优化算法,即使在逆境中也能有效地优化这些代价函数.与传统方法不同,所提出的求解器不需要hand-crafted的正则化或先验,因为这些都是从数据中隐式学习的.我们把我们的方法应用于运动立体问题。从单目序列的图像对联合估计运动和场景几何形状.我们表明,我们学习的优化器能够有效地解决这个具有挑战性的优化问题.
计算机视觉中的大多数算法使用某种形式的优化来获得最能满足手头问题的某些目标函数的解.优化方法本身可以被视为一种简单的智能方法,用于搜索答案的解空间,可能利用目标函数的特定结构来指导搜索.
目标函数的一种特别有趣的形式是由许多平方剩余项的和组成的.
在大多数情况下,剩余项是优化变量的非线性函数,这类目标函数的问题称为非线性最小二乘(NLLS)问题。使用二阶方法可以有效地求解非线性规划问题[13]。
然而,能否成功找到一个好的解决方案也取决于问题本身的特点。剩余函数集可以比作一个方程组,其解为零, .如果这个系统中变量的数目大于方程的数目,那么这个系统是欠定的,如果它们相等,那么它是确定的.如果方程多于变量,那么它是超定的.适定问题需要满足三个条件:1)解必须存在2)必须有唯一的解,以及3)解必须作为其参数的函数是连续的[21].
待定问题是不适定的,因为它们有无限多的解,因此不存在唯一的解。为了解决这个问题,传统的优化器使用手工的正则化和先验来使不适定问题适定。
在本文中,我们旨在利用来自传统非线性最小二乘解算器的强大而成熟的思想,并将这些思想与有前途的基于学习的新方法相结合。在这样做的过程中,我们寻求利用基于神经网络的方法来学习稳健的数据驱动的先验的能力,以及传统的基于优化的方法来获得高精度的精确解。特别地,我们建议学习如何基于当前残差和雅可比(以及一些额外的参数)来计算更新,以使NLLS优化算法更有效并且对高噪声更鲁棒
我们将优化器应用于从单目图像序列估计帧对的姿态和深度的问题,该单目图像序列被称为单目立体,如图1所示。
综上所述,本文的贡献如下:
-
我们提出了一种端到端的可训练优化方法,它建立在对NLLS问题的强大的近似基于Hessian的优化方法的基础上 -
直接从数据中隐式学习最小二乘问题的先验和正则. -
第一个采用机器学习来优化光度误差的算法
典型的非线性最小二乘问题如下:
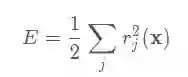
其中 代表第j项的误差,x是优化变量,E代表目标函数.遇到这些情况,我们通常使用GN、LM等.
将误差进行一阶展开:
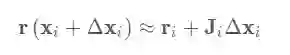
其中:
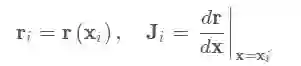
则最优迭代值为
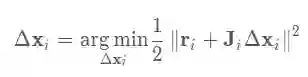
在Gauss-Newton (GN) 法中迭代步长通过下述方程求解:
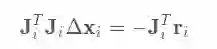
而与GN算法不同,Levenberg-Marquadt(LM)算法引入p改善收敛性,其迭代步长为:
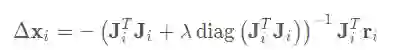
三维空间中的变换矩阵可以通过SE(3)李群中的指数映射得到,其中 是对应的李代数
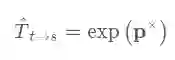
其投影映射关系如下(极线约束),其中 代表source图中的点坐标, 代表target图中的对应点坐标:
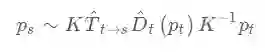
通过映射获得光度误差为:
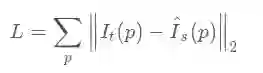
其中 通过双线性插值得到.通过建立光度误差:
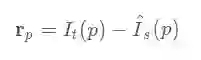
其雅克比很容易通过各种框架的autodiff自动求导得到(导数包含了双线性差值部分),例如Tensorflow里面可以用tf.gradients(res[i],x)),这里无需给出.
这一部分主要包含三个模块,分别说明如下。
这一部分主要是特征提取,作者使用了3个卷积层,stride=2,作为 backbone。最后接一个 upsample 和 conv1x1 得到一个大小为原图的1/4 的输出作为 depth 估计。另外通过 backbone 接全连接层输出一个6维向量作为 pose。这一部分没有什么特别的。
为了能够更好地描述较远的深度,实际上网络输出作者采用的是逆深度形式z=1/d
Optimizing Nonlinear Least Squares with LS-Net
这一部分就是非线性优化层了,作者称之为 LS-Net。它的算法部分流程如下:

如之前所述,我们要估计的目标函数是上述每个像素的光度误差之和,其中待估计变量分为逆深度z和姿态pose两部分x=(z,p).
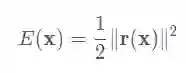
还是按照一个典型的梯度下降过程:
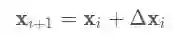
在本文中最大的不同就是将其中的步长 的估计使用一个循环神经网络(LSTM-RNN)来完成.公式如下
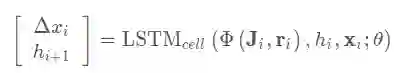
其中θ是网络的参数, 代表隐藏层.这是一个典型的LSTM Cell.其中输入部分 在下一小节介绍
在优化过程中作者遵循 GN 的优化过程,即
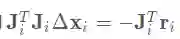
但是本文中的雅克比是通过对深度和姿态的自动求带获得(感觉这一步可能不合理,因为自动求导会当做在欧式空间完成,实际上pose是李代数上的).为了简化雅克比矩阵,作者按照下图做了进一步变换,将 压缩后作为网络的输入,具体压缩过程如下图所示:
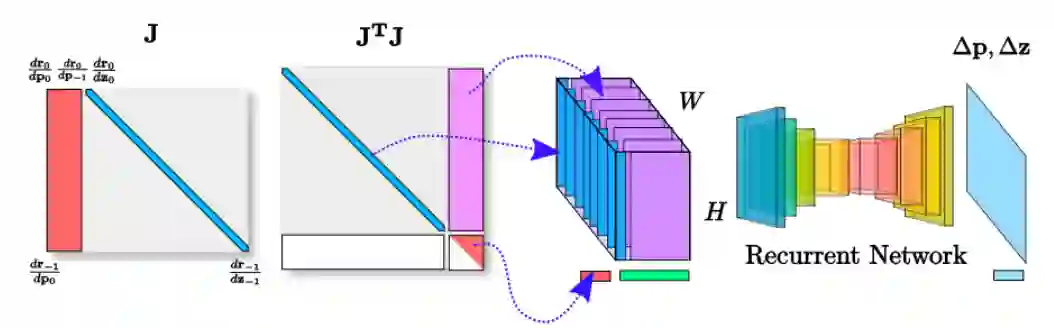
这里也利用了所谓雅克比矩阵的稀疏性,通常 pose 的数量远少于需要估计的深度的数量,所以可以这样压缩。实际上是减少了没用的参数输入,加快网络计算的速度。
压缩后的 和 对应的 合起来(concanate)作为 LSTM 的输入
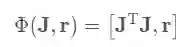
这里作者避免了使用 作为网络输入是因为这里增加了大量计算(而且事实上也没提供新的输入信息)
上一步的迭代优化网络为第一步初始化网络进行采样后的输入,因此,最后还需要一个上采样网络将优化后的深度图变成原图大小。作者采用的上采样函数就是双线性插值。
Loss
网络总计包含两个误差项,深度误差与姿态误差,两个Loss都是L1范数.
其中深度部分误差项定义为:
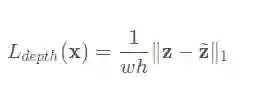
姿态部分误差项定义为:
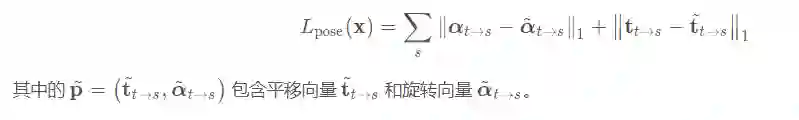
最终的误差项是二者加权求和:
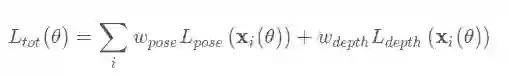
仿真部分作者做了简单的曲线拟合工作,用来和 LM 算法比较收敛速度以及误差,作者拟合的曲线包含:
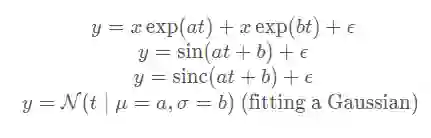
得出的实验结果如下图:
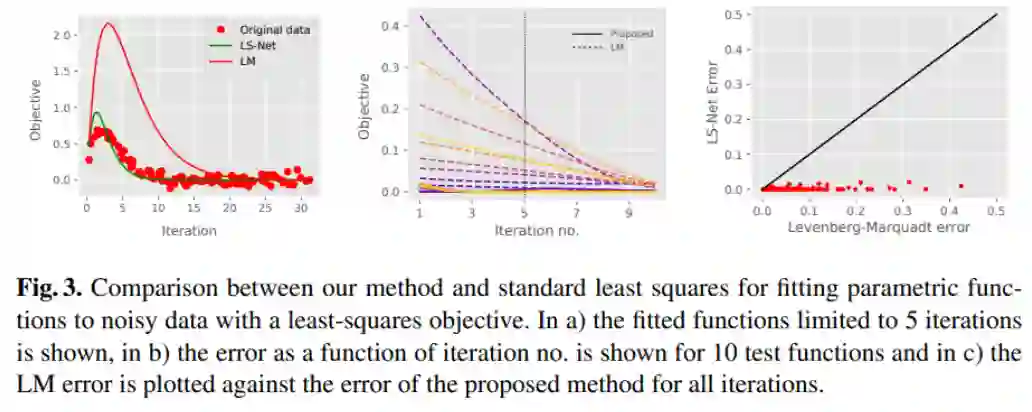
可以看到:
在图 a)中,仅经过5次迭代的话,LS-Net 拟合的曲线明显比 LM 拟合的曲线更接近真值。
在图 b)中,可以看出 LS-Net (实线)比 LM(虚线)收敛速度明显更快。
在图 c)中,将相同迭代次数的 LM 误差(x)和 LS-Net(y)做成散点图,可以看出相同迭代次数的 LM 误差均远大于 LS-Net 误差。说明 LS-Net 的收敛速度和收敛结果都更好
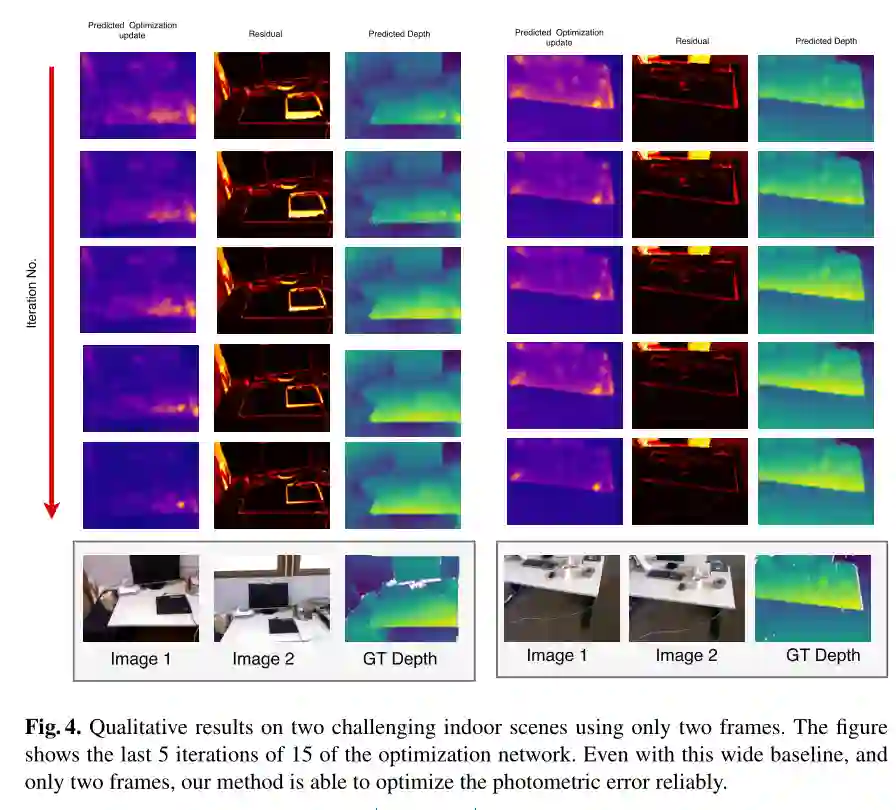
作者选取了2-view深度估计,证明即使在两幅图相距很远或者很近的极端情况,LS-Net依然能够估计出可信的深度:
与 DeMoN 的对比

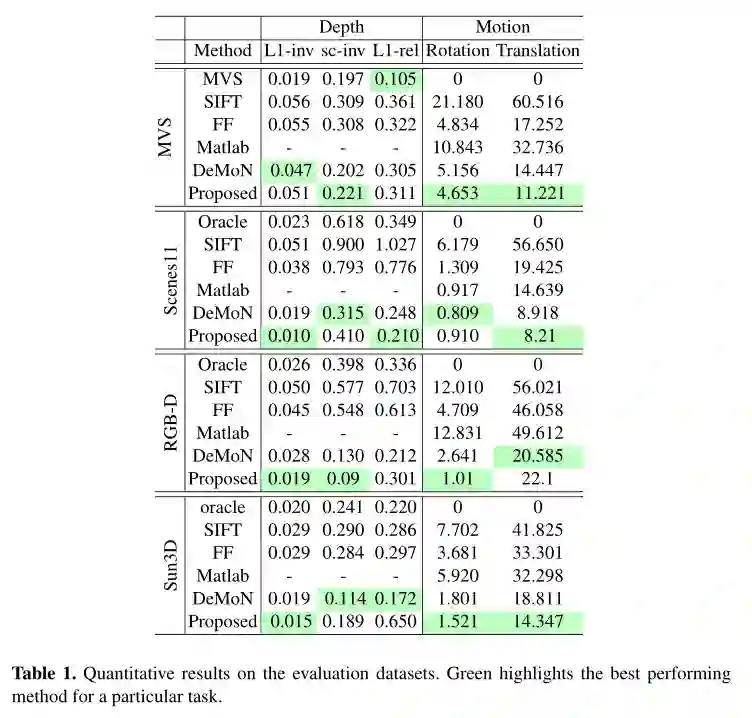
与同是深度学习方法的 DeMoN 的对比,在一些情况下显示出了更好的性能:
-
MVS : uses oracle with known poses -
SIFT : uses sparse features for correspondences -
FF : uses optical flow -
Matlab : uses KLT tracker in Matlab
http://www.liuxiao.org/https://blog.csdn.net/heiyaheiya/article/details/90754253
从0到1学习SLAM,戳↓

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓




