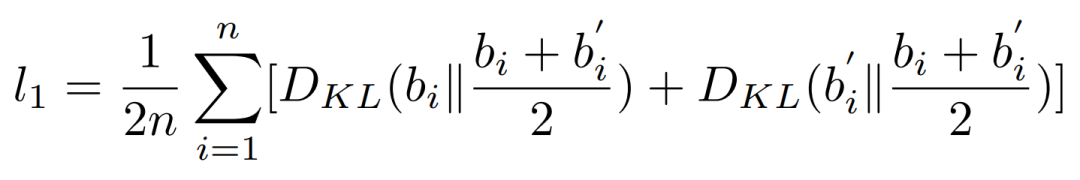大家都说深度神经网络能力很强,那么从函数注释生成函数代码,以及从函数代码总结函数注释这种最基础的代码任务到底能不能行?像 Python、Java 这样的通用高级语言,到底在代码生成上能达到什么水平?本文介绍的就是这样一篇北大前沿研究。
开发者写代码,和数学家写公式一样是非常自然的一件事。开发者将完成某个任务的步骤和逻辑,一行行写成代码,并期待达到预定的效果。数学家从某个事实出发,将思考过程一行行写成表达式,并期待找到复杂逻辑背后的简单关系。
这两者经常会有交叉,也会有融合。数学推导结果可以大量简化代码,并提供新的解决路径;而代码可以快速验证推导过程,并用于实际的生活中。代码和表达式都是一种形式化语言,而另一种必不可少的是用来描述它的自然语言,也就是注释或文档。
通过注释,我们能知道这段代码干了什么,甚至很自然地想到「
如果是我,这段代码该怎么写
」。通过阅读代码,我们能沿着开发者的思路走一遍,
总结出它到底干了什么
。这两者似乎是一种对偶关系,从代码到注释、从注释到代码,这就是代码生成与代码总结两大任务。
在这篇文章中,我们将介绍代码生成与总结的最新进展,北大 Bolin Wei、李戈等研究者提出的对偶学习在 Python 和 Java 代码生成上获得了新的 SOTA,并且被接收为 NeurIPS 2019 论文。
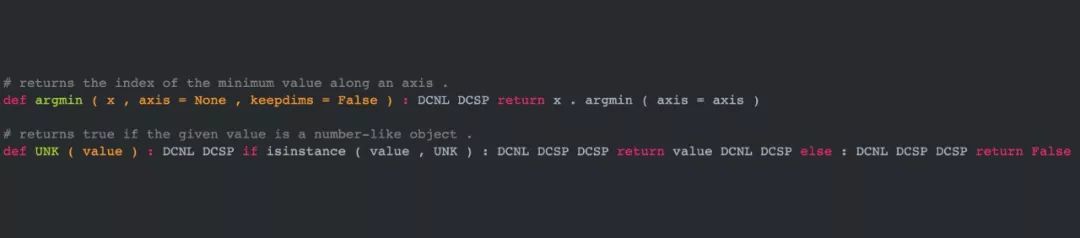
如下是北大
新研究根据注释生成的两段代码
,其中 dcsp 表示 tab 键、dcnl 表示换行符,它们控制 Python 代码的缩进结构。
![]()
值得注意的是,在 Python 语言上,根据注释这种自然语言,生成有效的代码已经达到了 51.9% 的准确率。也就是说,
生成的一半代码能通过词法分析、语法分析,并生成正确的抽象语法树
。
之前这两项研究大多都是独立的,代码总结会利用 Encoder-Decoder、抽象语法树和 Tree RNN 等技术生成意图,代码生成会利用 Seq2Seq、语法规则和基于语法的结构化 CNN 来生成代码,这些研究并没有深入挖掘它们之间的关系。
而北大的这一项研究从对偶学习出发,探索如何利用它们之间的关系促进提升学习效果。
具体而言,研究者考虑了
概率与注意力权重中的对偶性
,从而设计了一种正则项来约束对偶性。更直观而言,这种「对偶性」表示代码生成任务的输入"意图"同样是代码总结的输出,反之亦然。其中意图指开发者写这一段代码的目的,一般而言会通过注释的方式用自然语言表达。
![]()
利用对偶学习,研究者获得了当前最优的效果。其实这种提升也非常合理,例如当前效果最好的神经机器翻译模型 Transformer Big + BT,它就大量采用回译机制,希望根据原语与目标语之间的相互翻译,从而得到更好的最终模型。
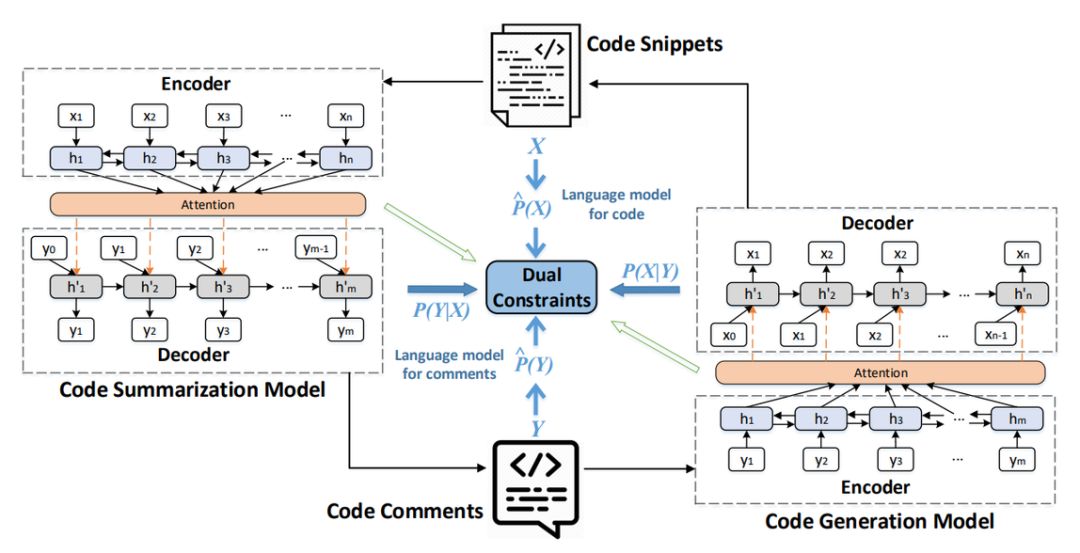
如下所示为代码生成、总结的对偶学习框架,总体上生成与总结两条路径都非常容易理解,它们都采用了常规基于注意力机制的 Seq2Seq 模型。现在重要的是理解中间的对偶约束,该约束用于给损失函数加正则项,从而令它们之间相互促进。
![]()
对偶训练的整体过程,代码生成模块与总结模块会联合训练。
上面 Seq2Seq 的过程就不再赘述了,它们采用的损失函数也是常规将所有时间步上的损失相加。不过需要注意的是,源代码的词汇量要比注释更大一些,因此代码生成模块输出层的参数量要大于代码总结的输出层参数量。
如前所述,对偶训练框架包含了非常重要的对偶约束,它由两个对偶正则项组成,分别用于约束两个模型的对偶性。这两种正则项受到了注意力权重具有对称性的启发,也受到了两种模型之间概率相关性的启发。
若现在给定输入样本<x, y>,其中假设 x 为代码,y 为对应的代码注释。那么代码生成可以描述为 p(x|y)、代码总结可以描述为 p(y|x)。现在如果要找到它们之间的概率相关性,那么
根据联合概率与条件概率之间的关系式
就可以快速得出:
也就是说,
logP(x) + logP(y|x) 需要等于 logP(y) + logP(x|y),这是代码生成与总结的内在联系
。如果两项差别很大,那么至少可以判定代码生成与总结都没有达到最优。所以,常规的做法就是把这个约束构建为损失函数:
其中 P(x) 和 P(y) 分别是针对代码和注释的语言模型,它们都是边缘分布。这个损失有点类似于回归模型常用的均方误差,如上所示,只要两个子模型不满足理论上的概率条件,那么肯定会产生损失,在训练中就会建立起代码生成与总结的关系。
上面是其中一个正则项,另一个正则项主要是考虑两个子模型之间的对称性。在北大的这一项研究中,他们考虑了注意力权重的对称性。研究者表明,因为注意力权重能度量源代码 Token 与注释 Token 之间的匹配关系,而这种匹配关系又是对称的,所以注意力权重也需要是对称的。
研究者举了一个例子,例如代码注释为「find the position of a character inside a string」,那么对应源代码可能为「string . find ( character )」。现在,不论是从代码到注释还是从注释到代码,
源代码中的「find」一定需要匹配到注释中的「find」
,它们之间的关系是不变的。
所以,现在最直观的思想是,
我们希望两个注意力权重矩阵 A_xy 和 A_yx,它们之间对应的元素尽可能相等
。
因为 A_xy 表示代码部分注意到注释部分的程度,所以,A_xy 矩阵的每一行表示代码的某个 Token,与注释的所有 Tokens 之间的关系。同理 A_yx 表示注释部分注意到代码部分的程度,A_yx 的每一列表示代码的某个 Token,和注释的所有 Tokens 之间的关系。
具体而言,如果
![]() ,其中 i 表示 A_xy 的第 i 行;
,其中 i 表示 A_xy 的第 i 行;
![]() ,其中 i 表示 A_yx 的第 i 列。那么很明显,我们需要令 b_i 尽可能等于 b_i'。
如果它们非常相近,那么可以表明注意力权重矩阵是对称的,源代码和代码注释之间的匹配是成功的
。因为经过 softmax 的 b_i 和 b_i'都是一种概率分布,所以北大研究者通过 JS 散度度量这两类分布之间的距离。
,其中 i 表示 A_yx 的第 i 列。那么很明显,我们需要令 b_i 尽可能等于 b_i'。
如果它们非常相近,那么可以表明注意力权重矩阵是对称的,源代码和代码注释之间的匹配是成功的
。因为经过 softmax 的 b_i 和 b_i'都是一种概率分布,所以北大研究者通过 JS 散度度量这两类分布之间的距离。
最常见的 KL 散度是不对称的,也就是说 KL(b_i || b_i') 不等于 KL(b_i' || b_i),而 JS 散度是 KL 散度的「对称版」,所以采用 JS 散度非常合理。此外,因为 JS 散度是对称的,所以代码生成模型与代码总结模型都能采用这样的距离度量作为约束条件。
最后,以注意力权重的对称性作为正则项,JS 散度可以表述为:
现在两种正则项都已经完成了,只需要联合训练两个子模型就行了。如下算法 1 所示,输入两种数据源的语言模型预计对应的数据,模型就能开始学。
如上所示,对于每一个批量数据,模型会计算两个子模型各自的预测损失,并同时计算两个公共的对偶正则项。这样的损失能算出对应的梯度,并分别更新两个子模块的权重。
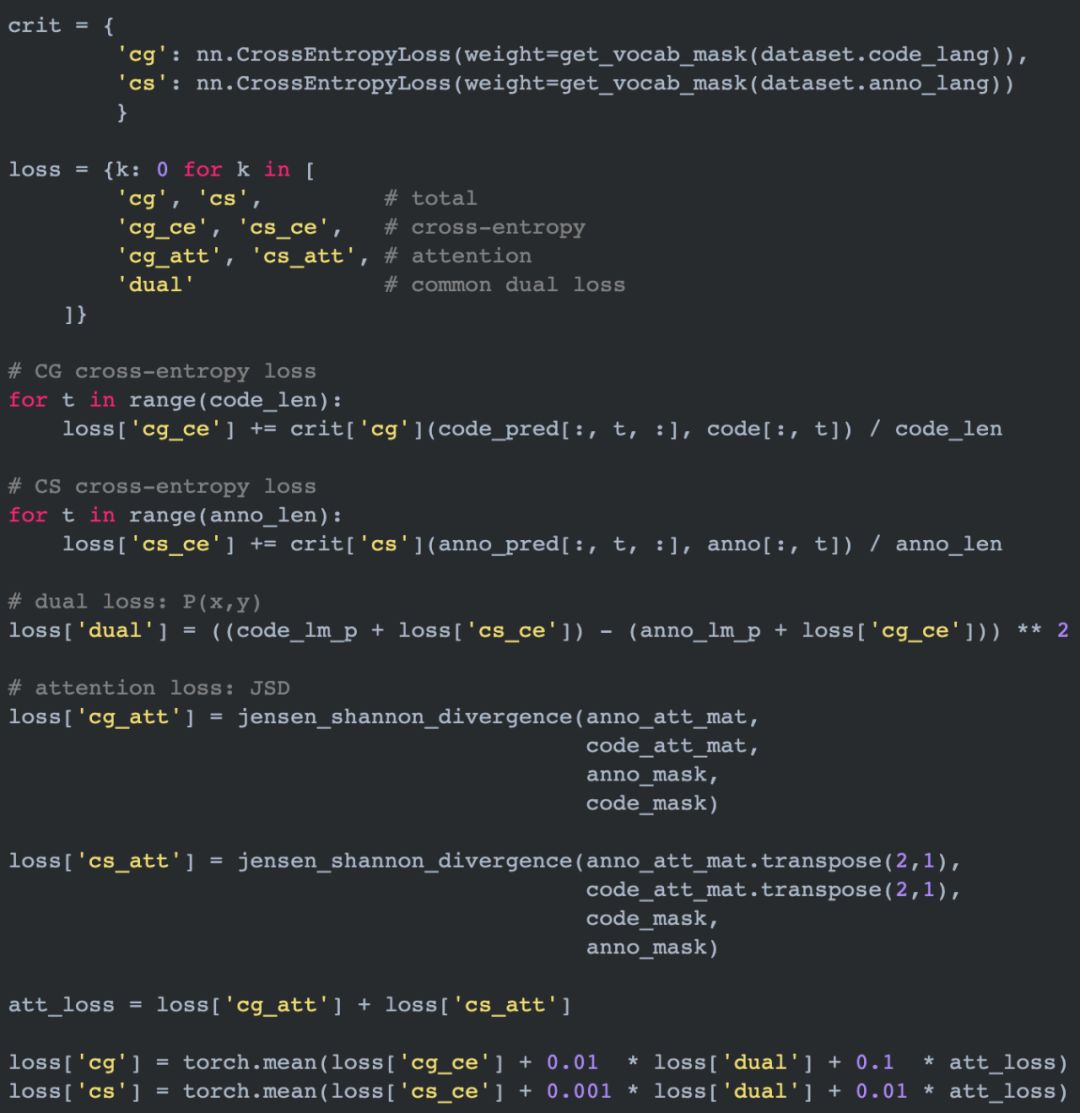
目前该研究的开源实现已经放到了 GitHub,研究者使用 PyTorch 实现了整个模型的训练过程。如上伪代码所示,模型架构方面,Seq2Seq 大家已经比较熟了,我们需要重点理解的是目标函数。
![]()
如上代码片段所示,损失函数主要由三部分组成:
即常规的交叉熵损失函数,它度量生成序列与标注序列间的距离;
对偶损失函数,它度量的是代码与注释的概率相关性;
最后是注意力损失,它度量的是两组注意力权重之间的分布距离。
通过这些训练目标的约束,代码生成与总结才会真正地相辅相成。
这种最正统的代码生成与总结无疑是非常困难的,它远远不能像 UI 界面那样生成简易的代码。也许借助卷积神经网络,UI 界面的代码生成已经能用于实际的界面设计,但是对于「更正统」的纯代码生成,目前的准确度还远远不能满足我们的要求。
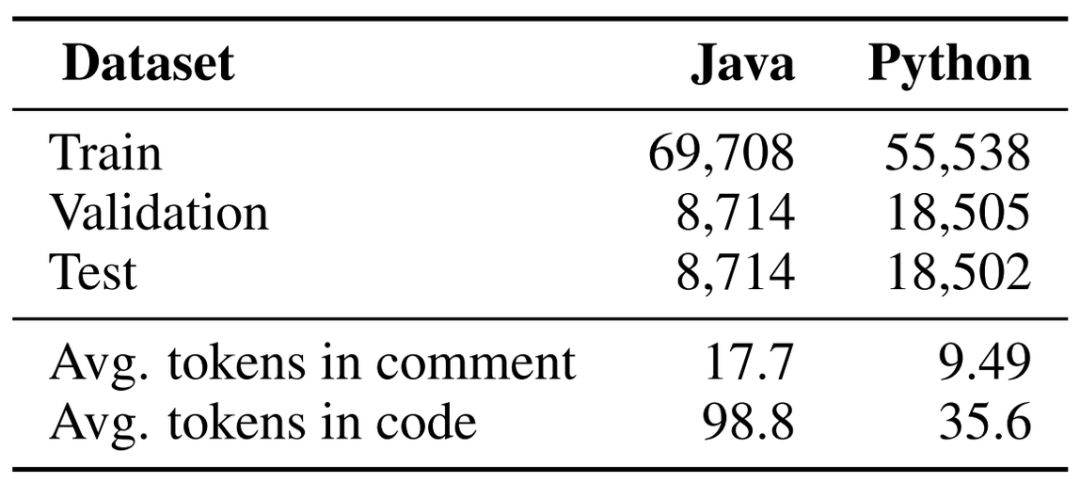
在这篇论文中,北大研究者在 Java 与 Python 两个数据集,测试了代码生成与总结的效果。其中 Java 数据集是从 GitHub Java 项目中抽取的 Java 方法,以及对应的自然语言注释,该自然语言了这个方法的用途。与 Java 类似,Python 数据集也是从 GitHub 中抽取的。两种数据集的统计信息如下所示:
![]()
论文表 1,我们可以看到,训练集有 5 万到 7 万段代码,且确实一段 Python 代码平均长度要远远少于 Java 代码。
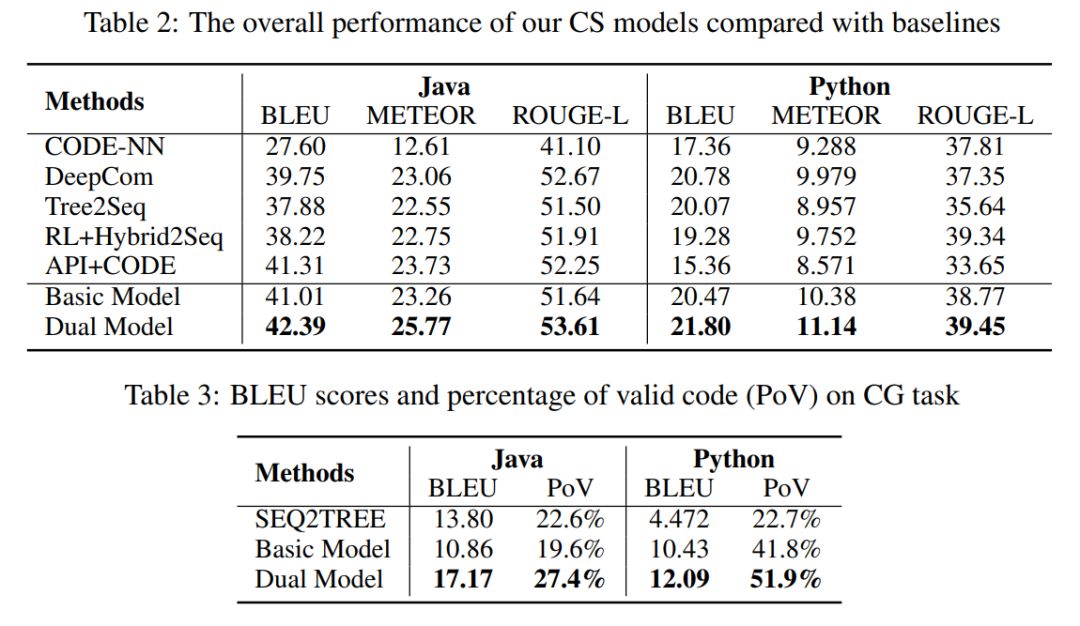
最后,我们可以看看北大研究者得出的最终效果。他们主要通过 BLEU 值、METEOR 和 ROUGE-L 三种度量方法评估模型生成的代码注释,这对于自然语言生成来说是比较常规的度量标准;此外,研究者通过 BLEU 值与有效代码率(PoV)来评估代码生成的效果,其中 PoV 指生成代码能解析为抽象语法树的比例。
如上所示为代码生成与总结的总体效果,我们可以发现对偶训练效果要超过其它方法,且相比独立训练的 Basic Model,效果也要更好一些。
值得注意的是,在代码生成中,Java 和 Python 的 PoV 分别只有 27.4 与 51.9%。也就是说,生成的代码首先不管是不是完成了自然语言描述的功能,它能通过词法分析、语法分析,最终成功地构建成抽象语法树,占比并不高。
这样的效果,也许代表着正统代码生成,最前沿的水平。它离生成合理的代码,辅助开发者完成实战开发还太远了。正如该论文作者李戈教授所说,程序的数据空间非常稀疏,而自然语言数据空间也比较稀疏,这两个稀疏空间的变换肯定会比较困难。它并不能像图像生成这种连续空间的变换,程序的生成还有很长的路要走。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

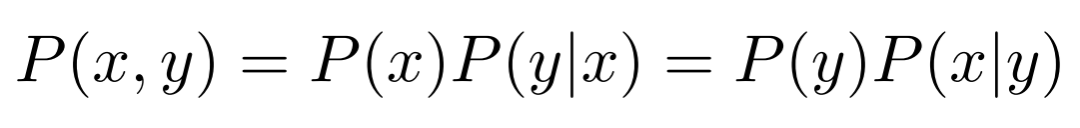
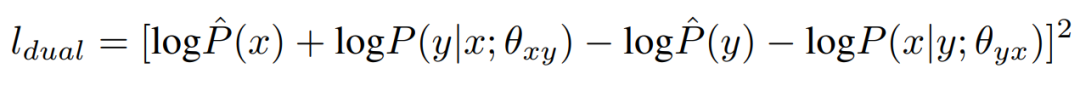
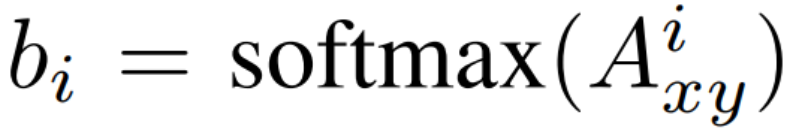 ,其中 i 表示 A_xy 的第 i 行;
,其中 i 表示 A_xy 的第 i 行;
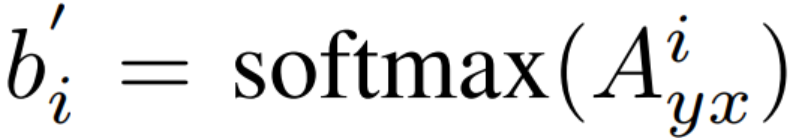 ,其中 i 表示 A_yx 的第 i 列。那么很明显,我们需要令 b_i 尽可能等于 b_i'。
如果它们非常相近,那么可以表明注意力权重矩阵是对称的,源代码和代码注释之间的匹配是成功的
。因为经过 softmax 的 b_i 和 b_i'都是一种概率分布,所以北大研究者通过 JS 散度度量这两类分布之间的距离。
,其中 i 表示 A_yx 的第 i 列。那么很明显,我们需要令 b_i 尽可能等于 b_i'。
如果它们非常相近,那么可以表明注意力权重矩阵是对称的,源代码和代码注释之间的匹配是成功的
。因为经过 softmax 的 b_i 和 b_i'都是一种概率分布,所以北大研究者通过 JS 散度度量这两类分布之间的距离。