本文对自基于 Transformer 模型兴起以来的关系抽取(Relation Extraction, RE)研究进行了系统性综述。借助自动化框架收集与标注文献,我们分析了 2019 年至 2024 年间发表的 34 篇综述论文、64 个数据集以及 104 个模型。该综述重点梳理了方法论的进展、基准资源的演化,以及语义网技术的融合趋势。通过从多维度整合研究结果,本文揭示了当前的研究趋势、主要局限与开放挑战,为研究者与实践者全面理解关系抽取任务的发展脉络与未来方向提供了参考。 此外,我们开放发布了经过标注的 Zotero 文献库,并同步公开了所开发的软件 SciLEx,该工具为系统性文献综述提供了统一的论文收集与分析框架,具备可复用性与可扩展性。
1 引言
日常生活的日益数字化带来了海量的文本数据,组织与个人都必须对其进行有效管理。如何将这些非结构化信息转化为结构化知识,是自然语言处理(NLP)与信息系统领域面临的关键挑战之一。**关系抽取(Relation Extraction, RE)**任务正是为应对此问题而提出的:它旨在识别文本中实体之间的语义关系,生成形如 (subject, relation, object) 的三元组。这种结构化表示不仅能显著提升索引、搜索与信息检索的效果,还为知识库(Knowledge Base, KB)与知识图谱(Knowledge Graph, KG)的构建与扩展奠定了基础。 知识图谱的应用由 Google 及开放资源如 Freebase [14]、YAGO [108]、DBpedia [9] 与 Wikidata [120] 推广开来,现已成为学术界与工业界的核心基础设施之一。它们支撑了从搜索引擎、推荐系统到科学发现等多种应用。然而,维护与扩充这些资源仍是一项高度依赖人工的工作。自动化关系抽取为大规模丰富知识图谱提供了可行的机制,使得 RE 同时具有基础研究价值与现实应用必要性。 研究背景与目标:
关系抽取的研究已有三十余年历史。其重要里程碑之一是 1992 年的第四届消息理解大会(MUC-4),该会议首次引入了标准化评估指标(精确率与召回率),并提出了第一个关系抽取系统 Fastus [48]。此后,RE 的发展经历了从基于规则的方法到统计学习再到神经网络结构的演进。而基于 Transformer 的预训练语言模型[17, 28] 的出现成为决定性转折点,它显著提升了包括 RE 在内的广泛 NLP 任务的性能 [123],并重新激发了对知识获取与信息抽取领域的研究兴趣 [86, 93, 96, 157]。 与以往综述的关系:
过去十年间已出现了大量关于关系抽取的综述,但其中仅有少数采用了系统性综述(Systematic Review)的方法论。Martinez-Rodriguez 等人 [76] 提供了对该领域的出色概述,但其研究主要涵盖 2020 年以前的工作,并侧重于基于管线与规则的方法。随后的一些研究关注较窄的方面,例如将关系抽取作为子任务的语法检查 [79]、时间关系抽取 [145],或数据集构建与标注实践 [12]。更近期的研究则聚焦于知识图谱构建整体 [66, 103],但对 RE 本身的关注相对较少。尽管这些研究仍具有重要参考价值,但在研究范围或方法论上均存在局限,至今仍缺乏一项全面、系统且最新的关系抽取领域综述。 目标读者:
本综述旨在为不同层次的读者——包括研究人员、学生以及企业研发人员——提供关于 Transformer 对关系抽取任务影响的清晰全貌。它为关注 NLP 与知识图谱交叉领域的研究者与实践者提供参考,帮助理解自大规模语言模型兴起以来解决 RE 任务的主要研究方向。此外,本综述基于一个公开语料库(包含完整收集的论文集与经过精炼标注的版本),提供了可扩展的分析基础,便于未来在特定方向上进一步深入研究。 研究目的与贡献:
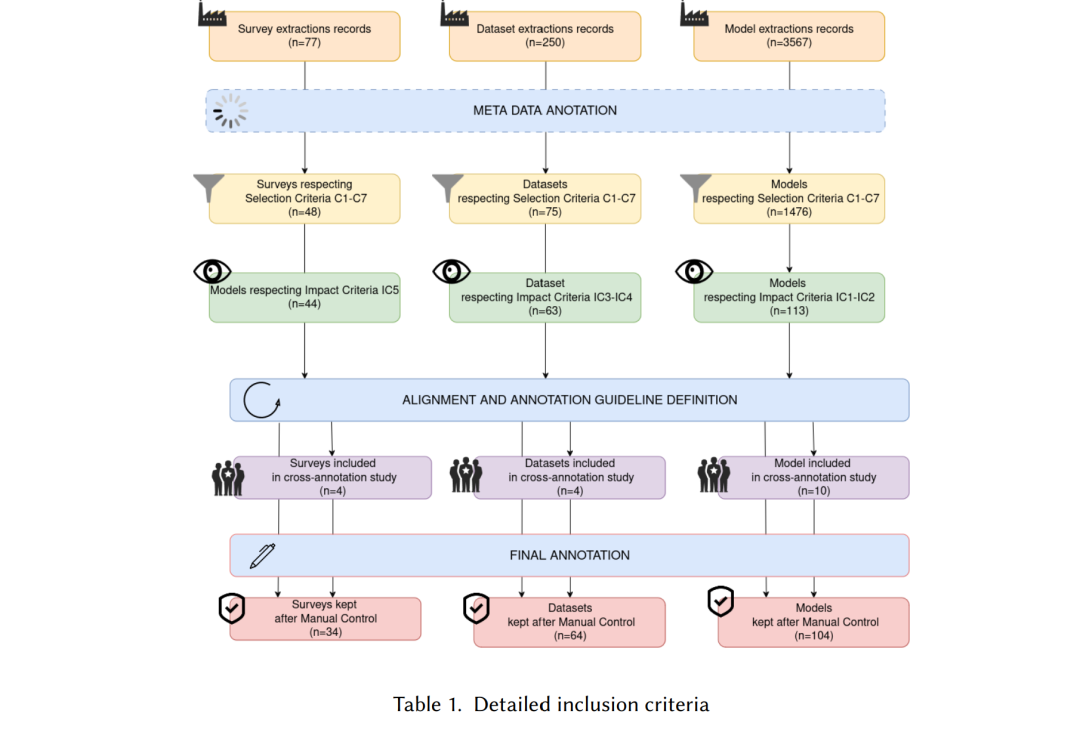
本文针对 2019–2024 年期间的文本关系抽取研究进行了系统性文献综述(Systematic Literature Review, SLR),该时期恰逢 Transformer 模型的快速崛起 [118]。本研究兼顾方法论严谨性与内容全面性,主要贡献如下: 1. 更新且细致的关系抽取研究综述,突出大规模预训练语言模型的变革性影响; 1. 应用 SciLEx 框架,该扩展型系统性综述方法确保研究过程的透明性、可复现性与开放共享性; 1. 基于三十余个分析维度的精细标注体系,涵盖资源、模型与综述三大层面,并公开发布以支持后续研究与比较分析。