7 Papers & Radios | 全球最大人脸数据集;类Transformer模型跨界视觉任务新SOTA
机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文包括 格灵深瞳等机构开源的全球最大人脸数据集,以及类 Transformer 模型跨界在视觉任务上取得了新 SOTA。
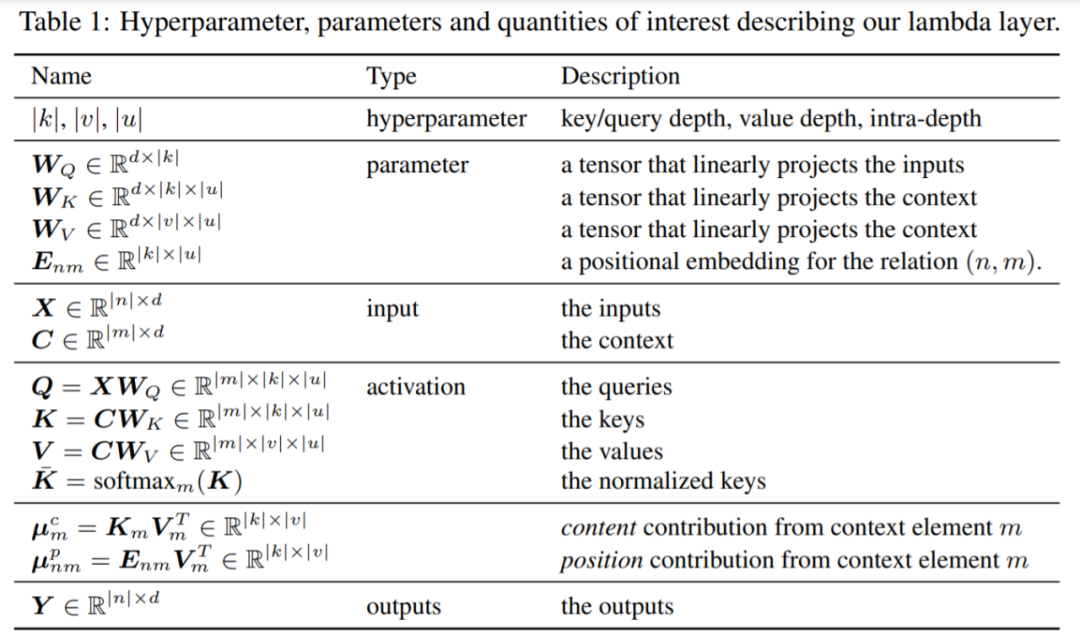
LambdaNetworks: Modeling long-range Interactions without Attention
Fourier Neural Operator for Parametric Partial Differential Equations
Beyond English-Centric Multilingual Machine Translation
A Cross-Domain Recommendation Model Based on Dual Attention Mechanism and Transfer Learning
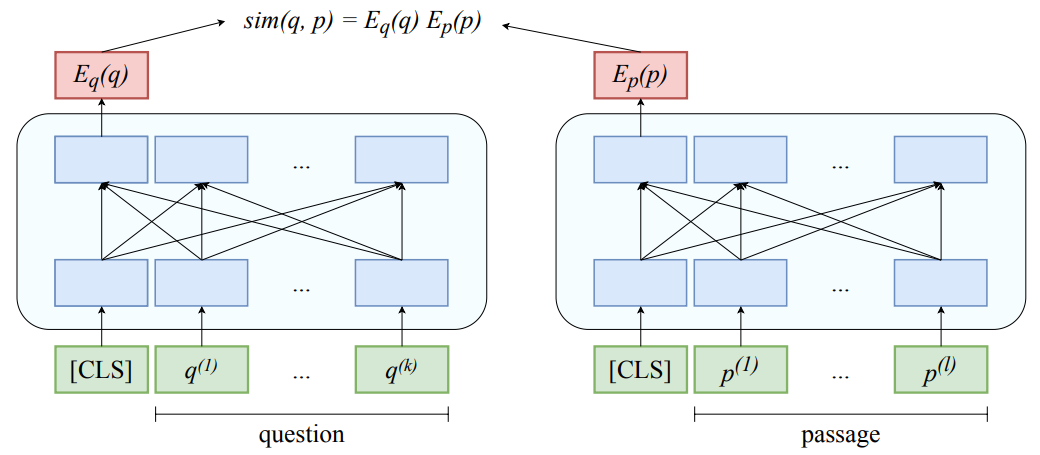
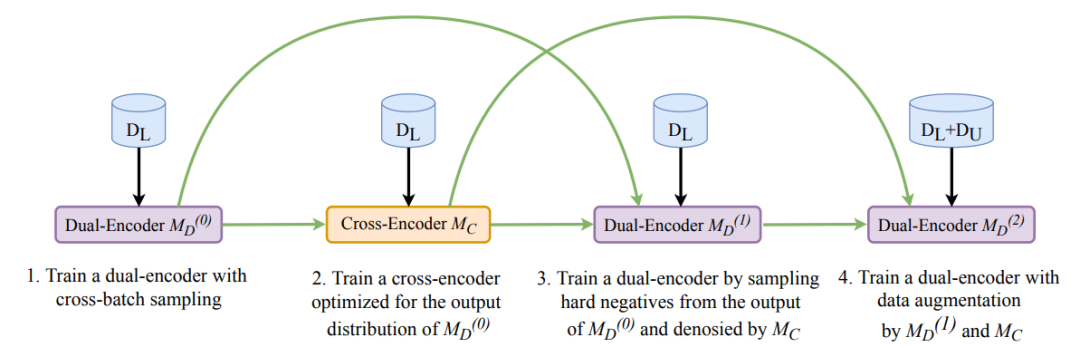
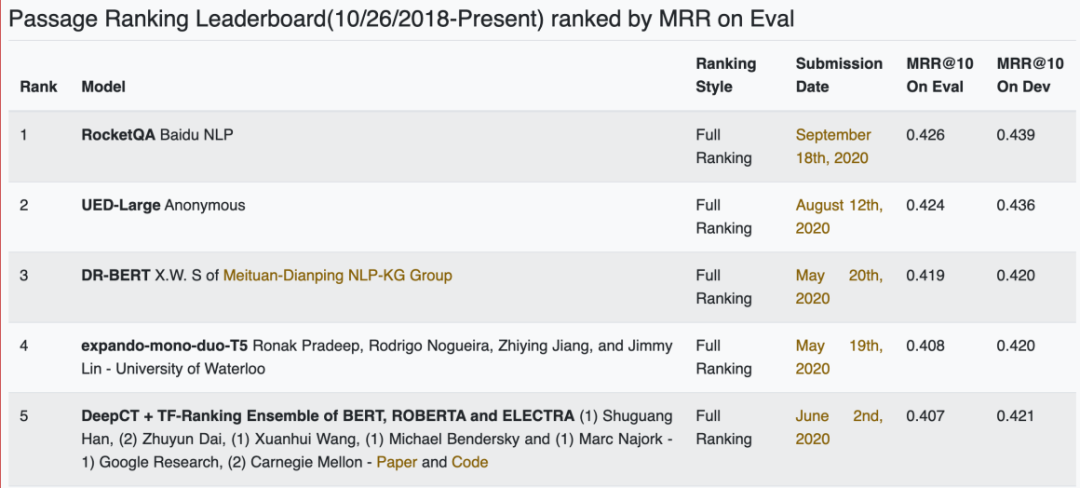
RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering
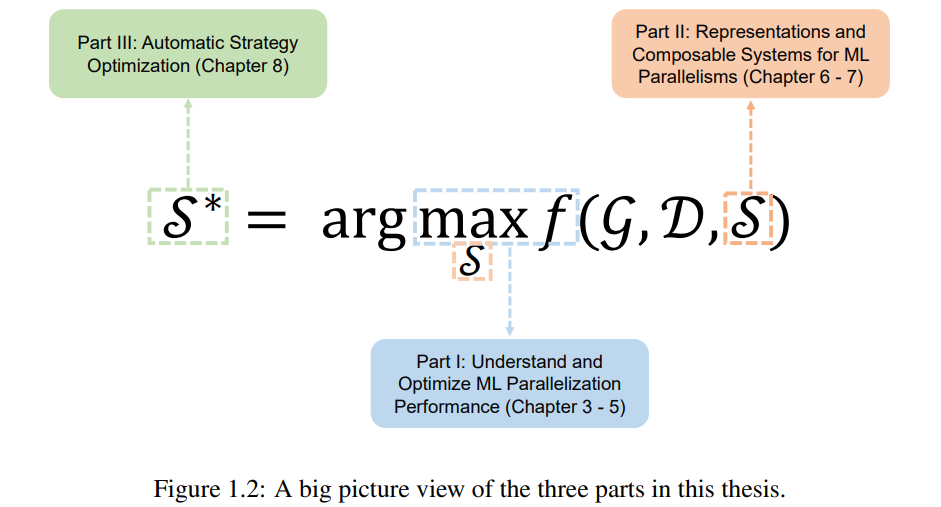
Machine Learning Parallelism Could Be Adaptive, Composable and Automated
Partial FC: Training 10 Million Identities on a Single Machine
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
作者:未公开
论文链接:https://openreview.net/pdf?id=xTJEN-ggl1b
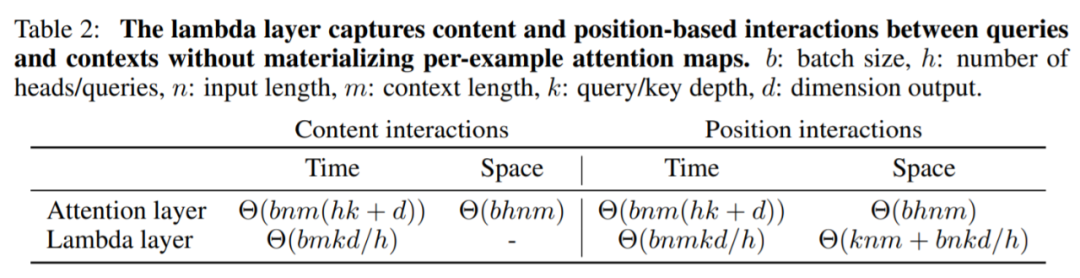
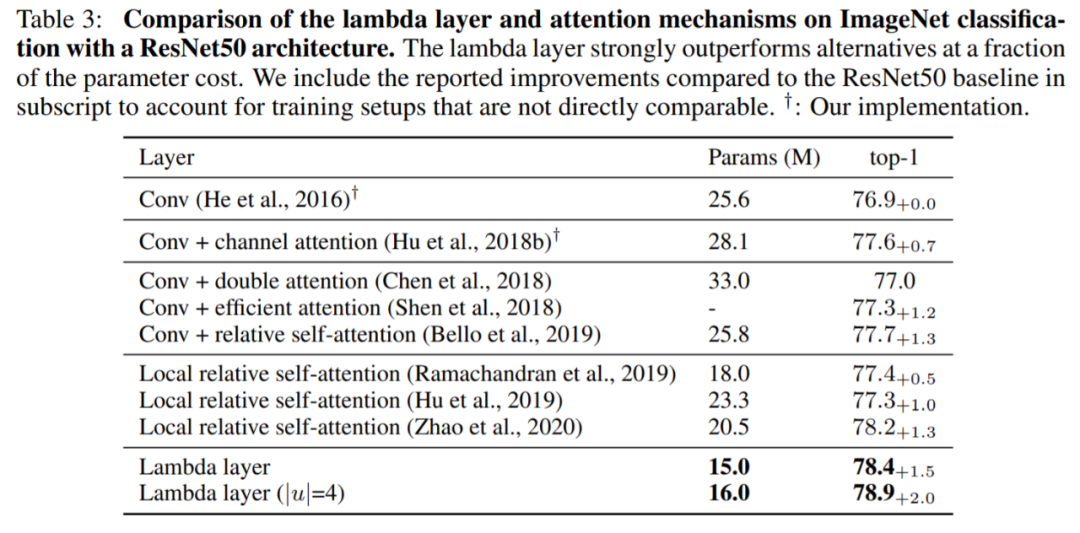
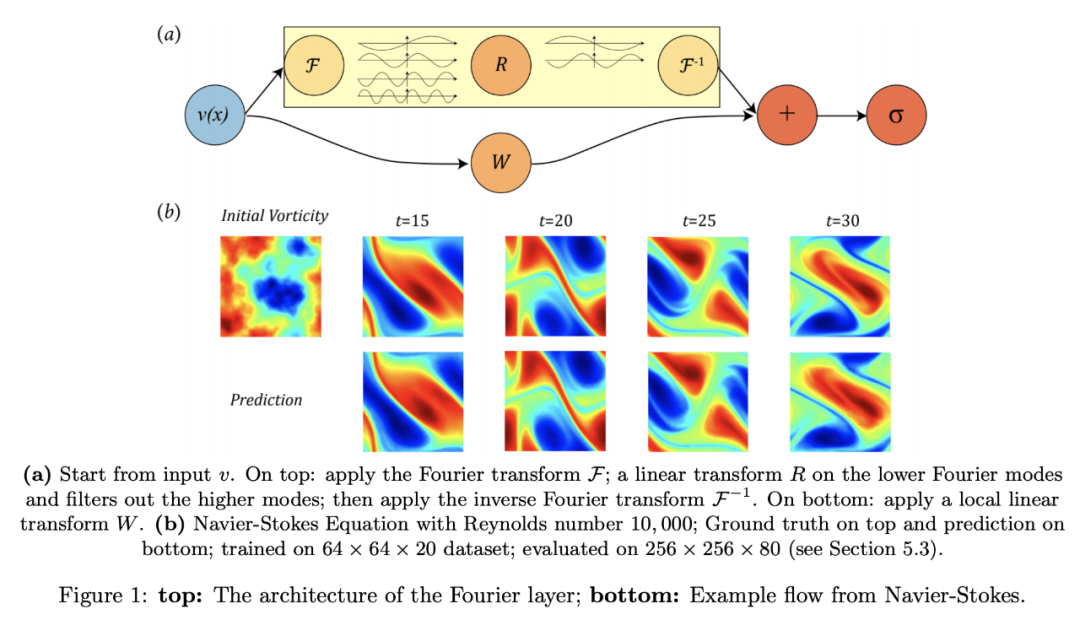
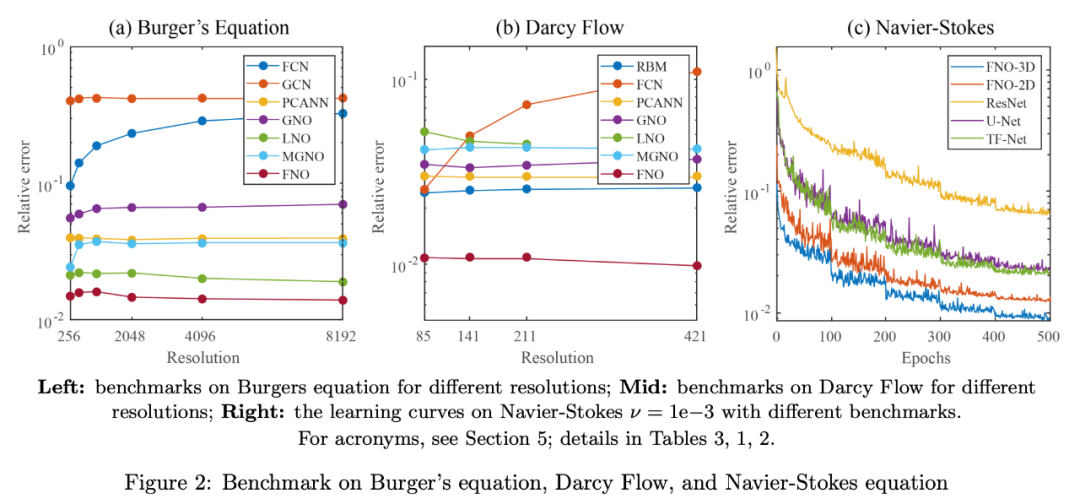
作者:Zongyi Li、Nikola Kovachki、Kamyar Azizzadenesheli 等
论文链接:https://arxiv.org/abs/2010.08895v1
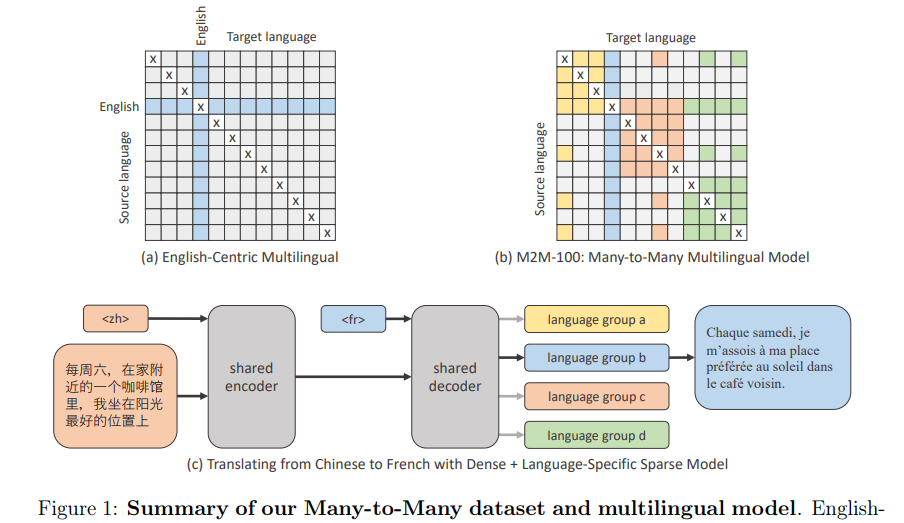
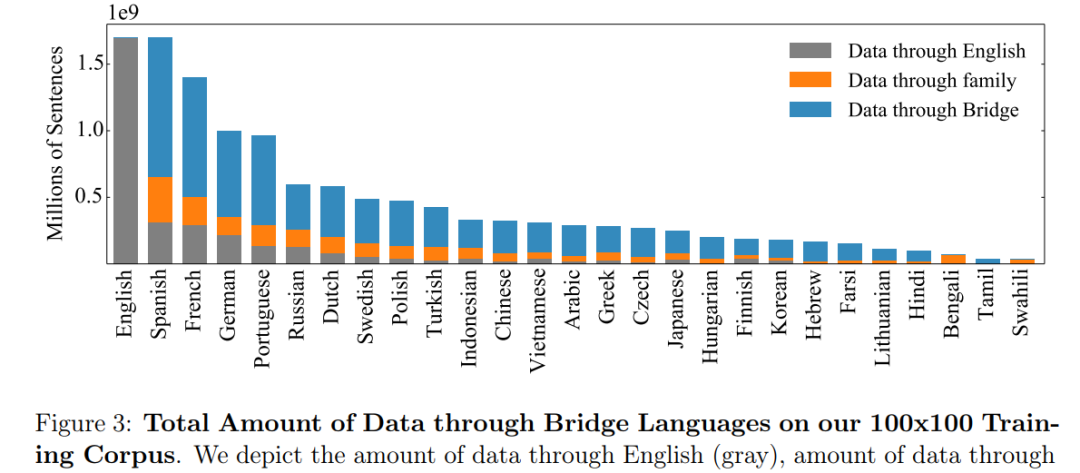
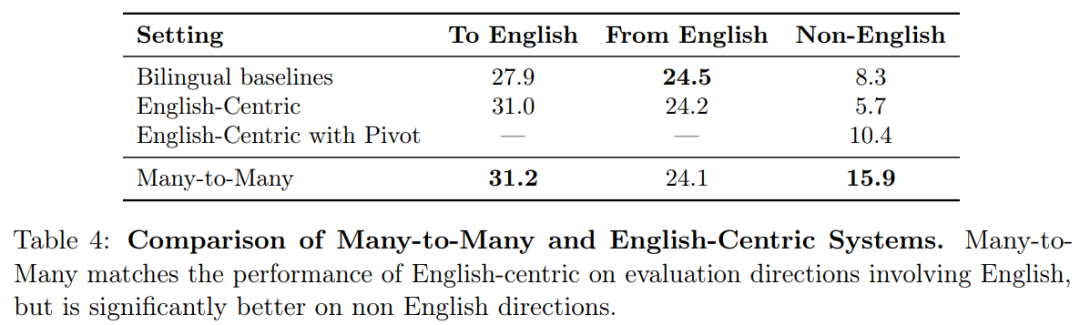
作者:Angela Fan、Shruti Bhosale、Holger Schwenk 等
论文链接:https://ai.facebook.com/research/publications/beyond-english-centric-multilingual-machine-translation
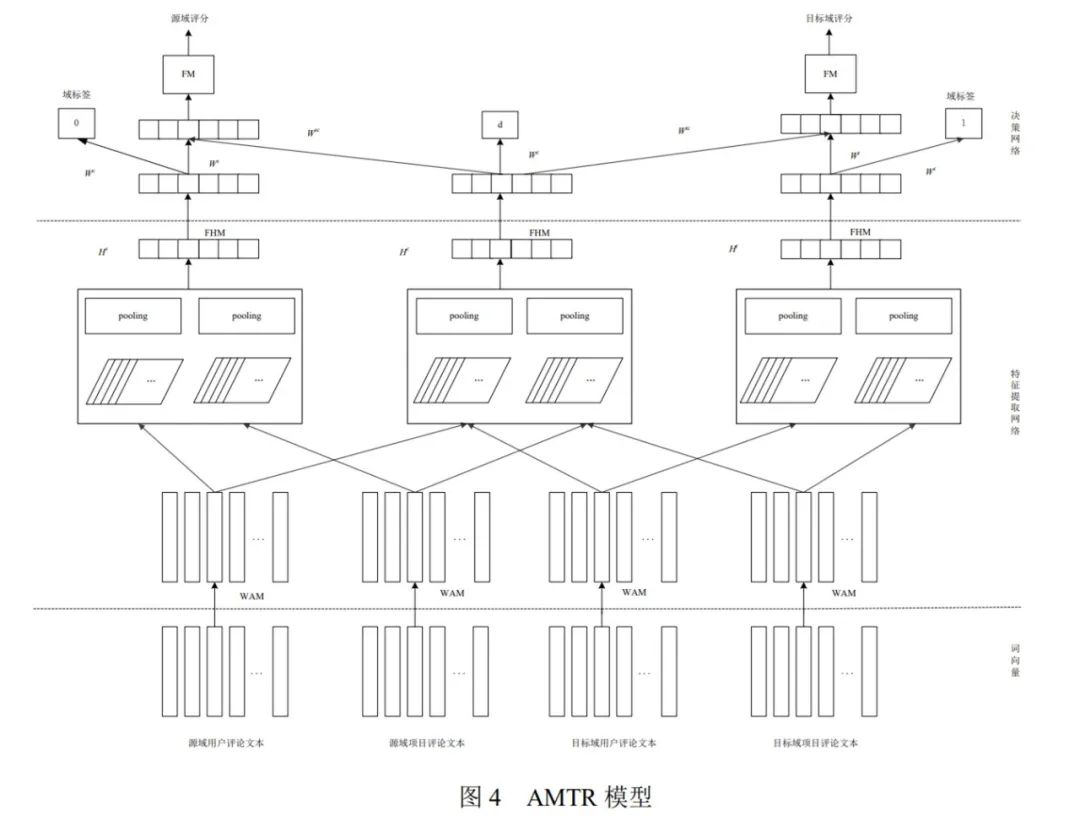
作者:CHAI Yu-Mei、YUN Wu-Lian、WANG Li-Ming、LIU Zhen
论文链接:http://cjc.ict.ac.cn/online/bfpub/cym-2020324142846.pdf

作者:Yingqi Qu、Yuchen Ding、Jing Liu 等
论文链接:https://arxiv.org/abs/2010.08191
作者:Hao Zhang
论文链接:https://www.cs.cmu.edu/~hzhang2/files/hao_zhang_doctoral_dissertation.pdf

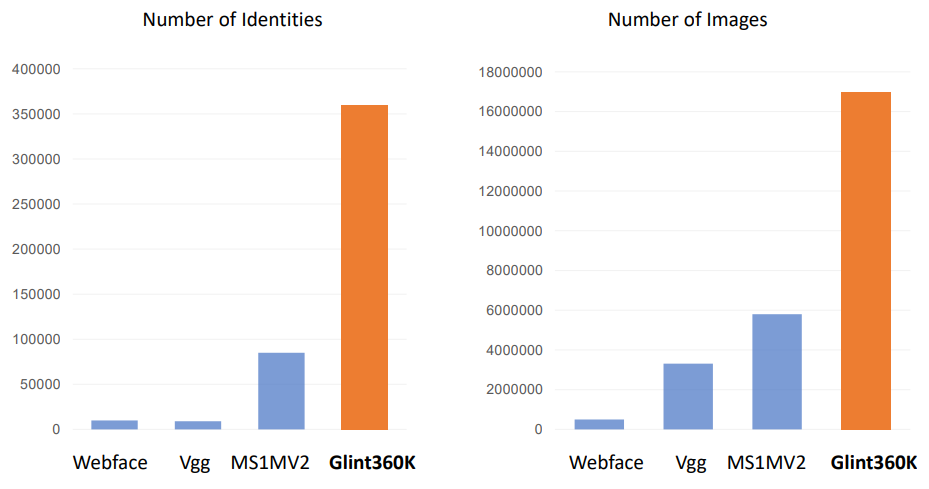
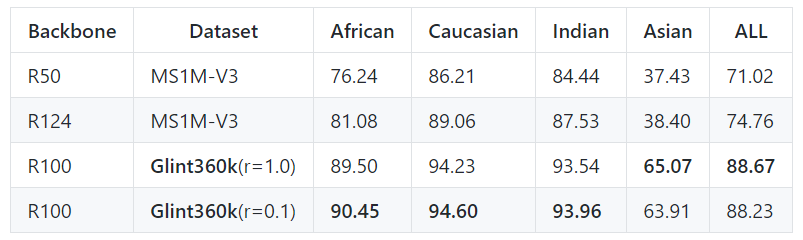
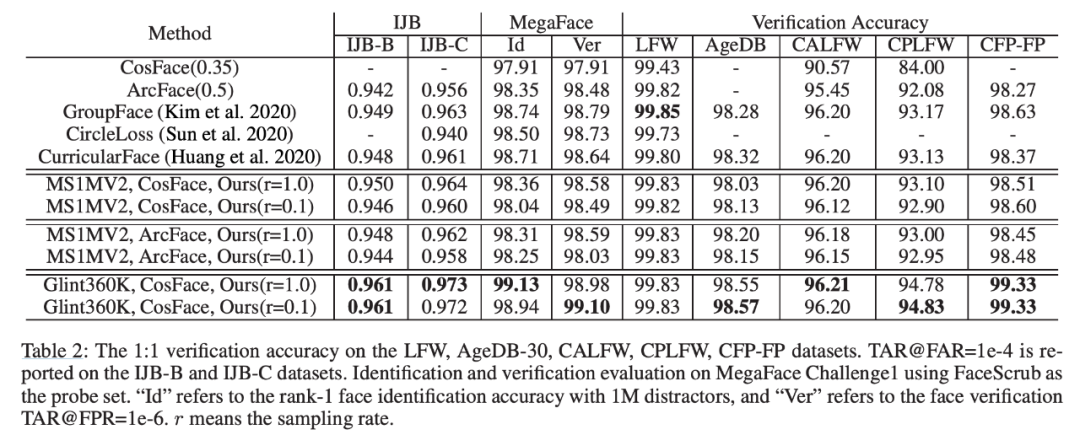
作者:Xiang An,1 Xuhan Zhu, 2 Yang Xiao
论文链接:https://arxiv.org/pdf/2010.05222.pdf