从 ClickHouse 到 ByteHouse,一场成功的深度改造 | Q推荐

如同 DB-Engines 网站上的 Rank 变化曲线一样,ClickHouse 无论是性能表现还是市场普及速度,都可以用“彪悍”两个字来形容。
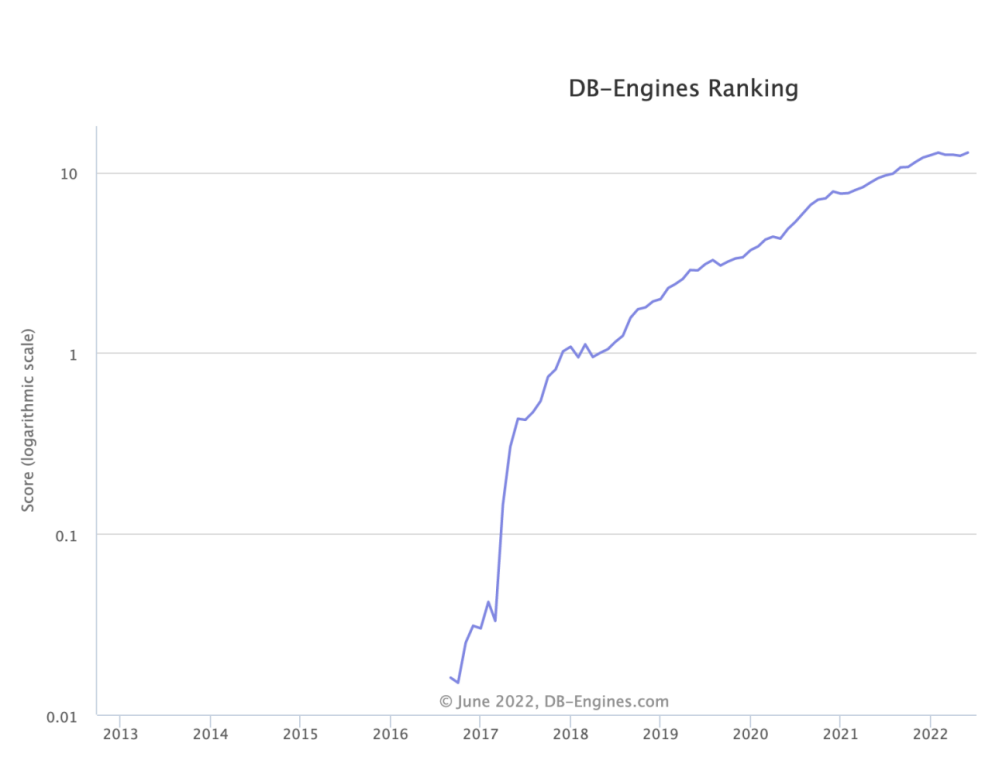
ClickHouse Rank 增长曲线,数据来源:DB-Engines
在性能方面,ClickHouse 在 OLAP 场景下的性能超越同类产品数倍不止,它允许系统以亚秒级的延迟从 PB 级的原始数据生成报告,服务器吞吐量高达每秒数亿行。
ClickHouse 的崛起标志着专用数据引擎开始取代通用型数据引擎,也标志着大数据的基础设施在技术上已经完备,单一场景下已实现性能的突破。剩下的无外乎是从技术到服务的转化,进而彻底兑现技术价值。
但是将 ClickHouse 引入企业级生产环境中,仍然存在的问题,以及关于这些问题的解决方法。关于落地实践的坑,并不是业内所有团队都需要自己踩一遍,也不是所有团队都能负担得起这样的成本,我们要做的是吸取足够的经验,以及选择自研、采购等更加实际的解决方案。
在这一点上,字节跳动无疑是一家非常有代表性的国内企业:字节跳动从 2017 年开始大规模启用 ClickHouse;到了 2019 年,仅在头条业务,集群规模已经达到数千个节点;到了今天,字节跳动将经过五年定制化改造的 ClickHouse,沉淀为 ByteHouse,正式对外提供服务。
从采用并改造开源产品,到上线商业版本对外服务,这是一条非常难走的路,同时也让其中的实践思考和经验更具参考价值。
最近,火山引擎 ByteHouse 联合 InfoQ 发布白皮书《从 ClickHouse 到 ByteHouse》,深度介绍字节跳动万台节点 ClickHouse 背后的技术实现,本卷白皮书大致分为四个章节:
ClickHouse 的介绍;
ClickHouse 典型场景;
针对生产环境中的 ClickHouse,ByteHouse 的技术优化思考;
ByteHouse 的设计和演进思路。
前两章主要是对 ClickHouse 系统的基础介绍,让你对 ClickHouse 的优势和场景测试情况,有统一的、准确的认知。第三章则主要介绍了 ByteHouse 的优化思路,也是行业关注的重点。目前,ByteHouse 对 ClickHouse 做了很多升级和优化,本次挑选了非常重要的三个方面:
目前,ByteHouse 对 ClickHouse 做了很多升级和优化,本次挑选了非常重要的三个方面:
自研表引擎;
查询优化器;
弹性可扩展。
在自研表引擎模块,尽管 ClickHouse 提供 MergeTree Family、Memory、File、Interface 等几十种不同的表引擎,但是在字节内部实际使用中,还是明显感觉到了一些表引擎不足以满足业务的使用需求,于是进行了相应的优化。白皮书则重点介绍 HaMergeTree 、HaUniqueMergeTree、HaKafka 三种表引擎。
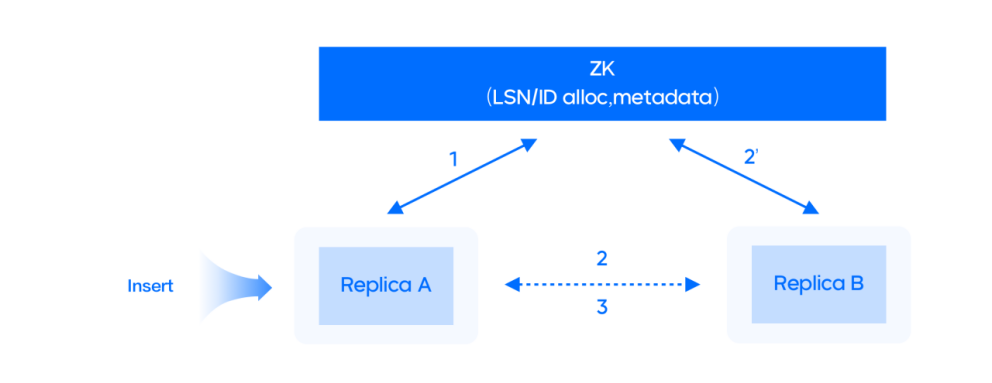
白皮书配图摘选:HaMergeTree 副本协同原理
在查询优化器模块,字节内部在使用社区版 ClickHouse 过程中也碰到了很多相关问题,很多时候不得不妥协,例如提前加工成大宽表进行使用,但是也有明显的弊端,使用很不灵活,维表数据变更后对历史数据还要进行全表刷新。
大量的需求迫使研发开始对于 Optimizer 的改造投入,经过过去一年多的开发,已经逐步稳定。本卷白皮书详细列举了 ByteHouse 在查询优化器上的改造与优化功能。从客户端发起 Query 请求到最终返回结果经历的所有核心模块,白皮书中都有所介绍。
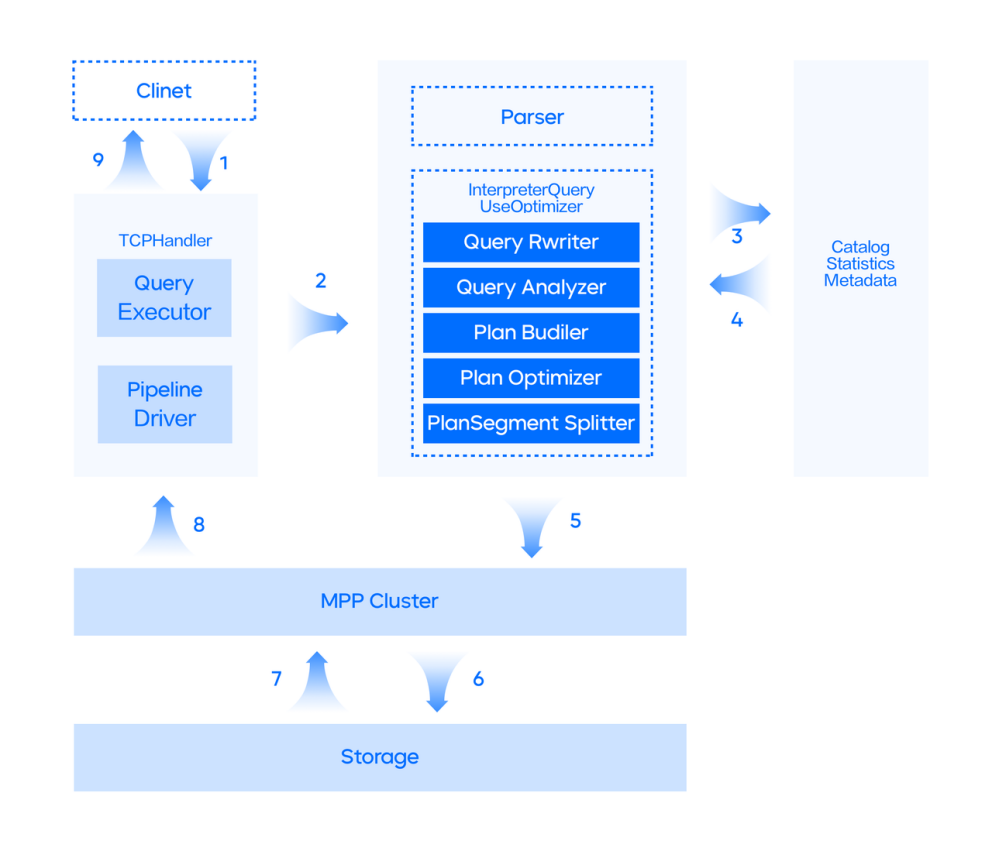
白皮书配图摘选:简易 Query 请求流程
当然,从客户端发起 Query 请求到最终返回结果经历的所有核心模块,白皮书中都有所介绍,此处我们就不详细展示了。
另外,本卷白皮书也详细介绍了 ByteHouse 在改进与优化 ClickHouse 过程中,基于架构的调整,包括如何在存储和计算上的拆解解耦,实现弹性可扩展的技术优化方案。
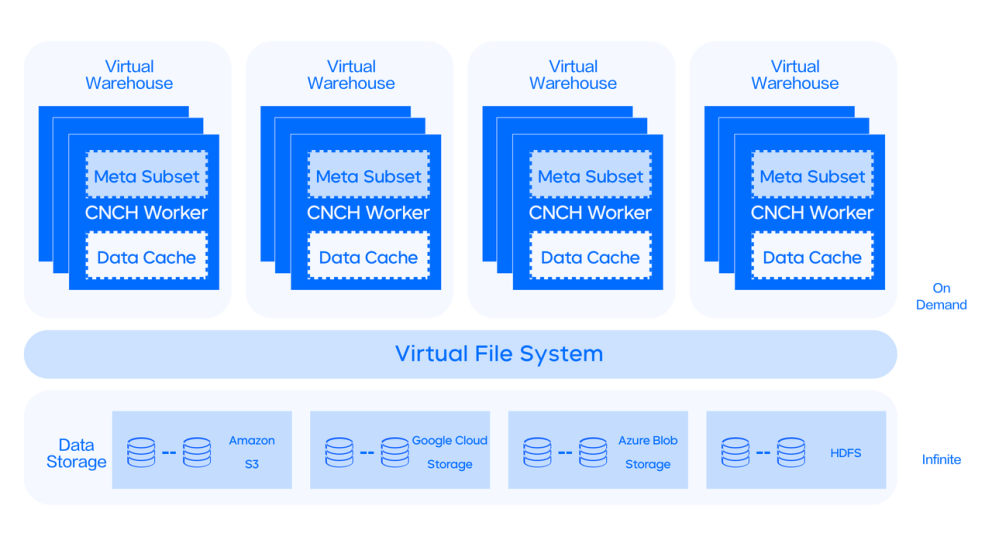
白皮书配图摘选:计算存储分离架构
从架构设计到场景落地,毕竟还有距离,但实践案例会将真相带给我们。白皮书重点列举广告、金融、工业互联网三大行业的实践案例,都属于 OLAP 的典型应用行业,并从技术与企业落地等角度给出了当下企业在 OLAP 数据引擎选型的三个核心关注点。
希望这本白皮书,能切实为你带来价值与收获。
点击阅读原文下载《从 ClickHouse 到 ByteHouse》白皮书



