基于EMR OLAP的开源实时数仓解决方案之ClickHouse事务实现

一 背景
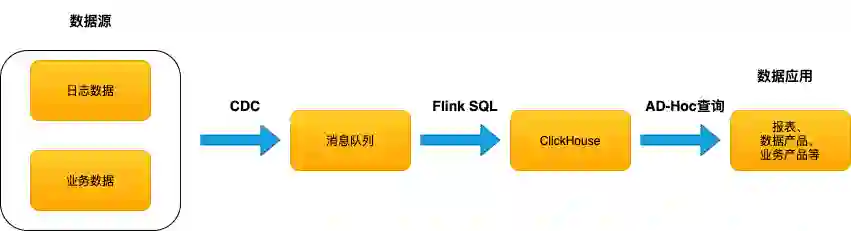
二 机制梳理
1 ClickHouse 写入机制
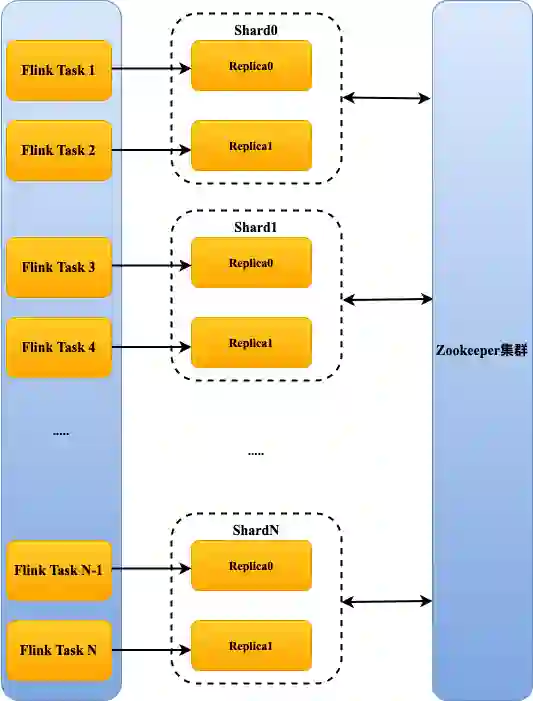
2 Flink 写机制
-
从快照中取出上次任务执行时持久化的 xid 记录。快照中主要存储两种 xid,一组是未完成 snapshot 阶段的 xid,一组是已经完成了 snapshot 的 xid。
-
接下来对上次未完成 snapshot 的 xid 进行 rollback 操作;对上次已经完成了 snapshot 但 commit 未成功的 xid 进行 commit 重试操作。
-
若上述操作失败,则任务初始化失败,任务中止,进入 close 阶段;若上述操作成功,则继续。
-
创建一个新的唯一的 xid,作为本次事务ID,将其记录到快照中。
-
使用新生成的 xid,调用 JDBC 提供的 start() 接口。
-
事务开启后,进入写数据的阶段,Operator 的大部分时间都会处于这个阶段。在与 ClickHouse 的交互中,此阶段为调用 JDBC 提供的 preparedStatement 的 addBatch() 和 executeBatch() 接口,每次写数据时都会在报文中携带当前 xid。
-
在写数据阶段,首先将数据写到 Operator 内存中,向 ClickHouse 提交内存中的批量数据有三种触发方式:内存中的数据条数达到batchsize的阈值;后台定时线程每隔一段时间触发自动flush;在 snapshot 阶段调用end() 和 prepare() 接口之前会调用flush清空缓存。
-
当前事务会调用 end() 和 prepare() 接口,等待 commit,并更新快照中的状态。
-
接下来,会开启一个新的事务,作为本 Task 的下一次 xid,将新事务记录到快照中,并调用 JDBC 提供的start() 接口开启新事务。
-
将快照持久化存储。
-
若当前事务尚未进行到 snapshot 阶段,则对当前事务进行 rollback 操作。
-
关闭所有资源。
三 技术方案
1 整体方案
2 ClickHouse-Server
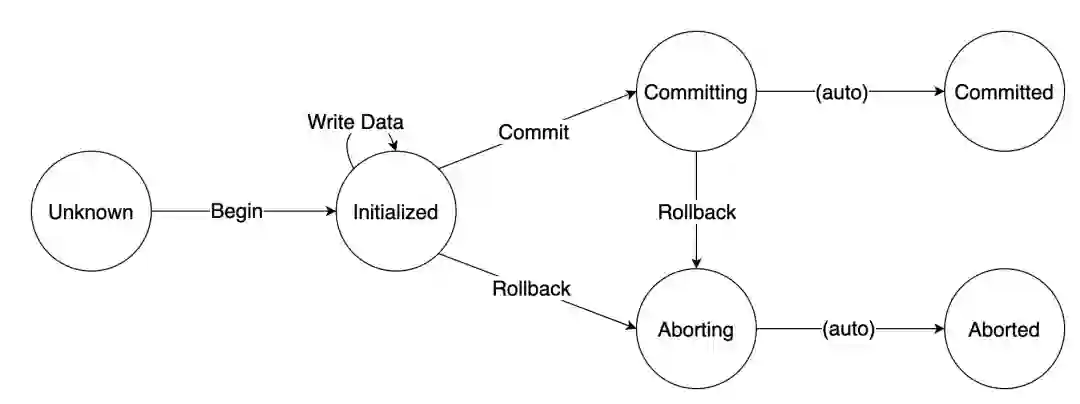
状态机
-
Begin:开启一个事务。 -
Write Data:在一个事务内写数据。 -
Commit:提交一个事务。 -
Rollback:回滚一个未提交的事务。
事务状态: -
Unknown:事务未开启,此时执行任何操作都是非法的。 -
Initialized:事务已开启,此时允许所有操作。 -
Committing:事务正在被提交,不再允许 Begin/Write Data 两种操作。 -
Committed:事务已经被提交,不再允许任何操作。 -
Aborting:事务正在被回滚,不再允许任何操作。 -
Aborted:事务已经被回滚,不再允许任何操作。
完整的状态机如下图-4所示:
事务处理
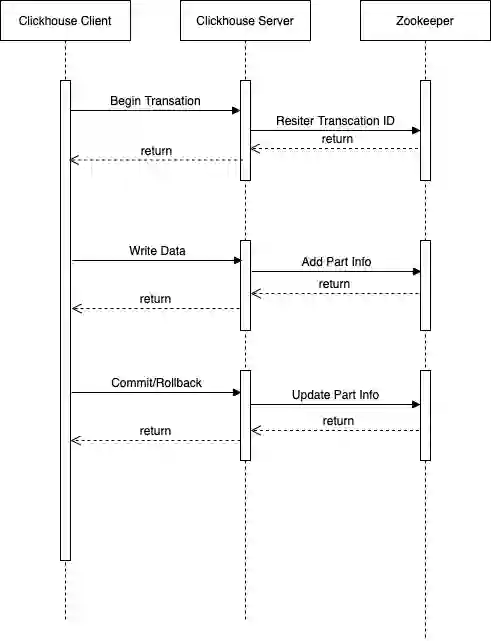
-
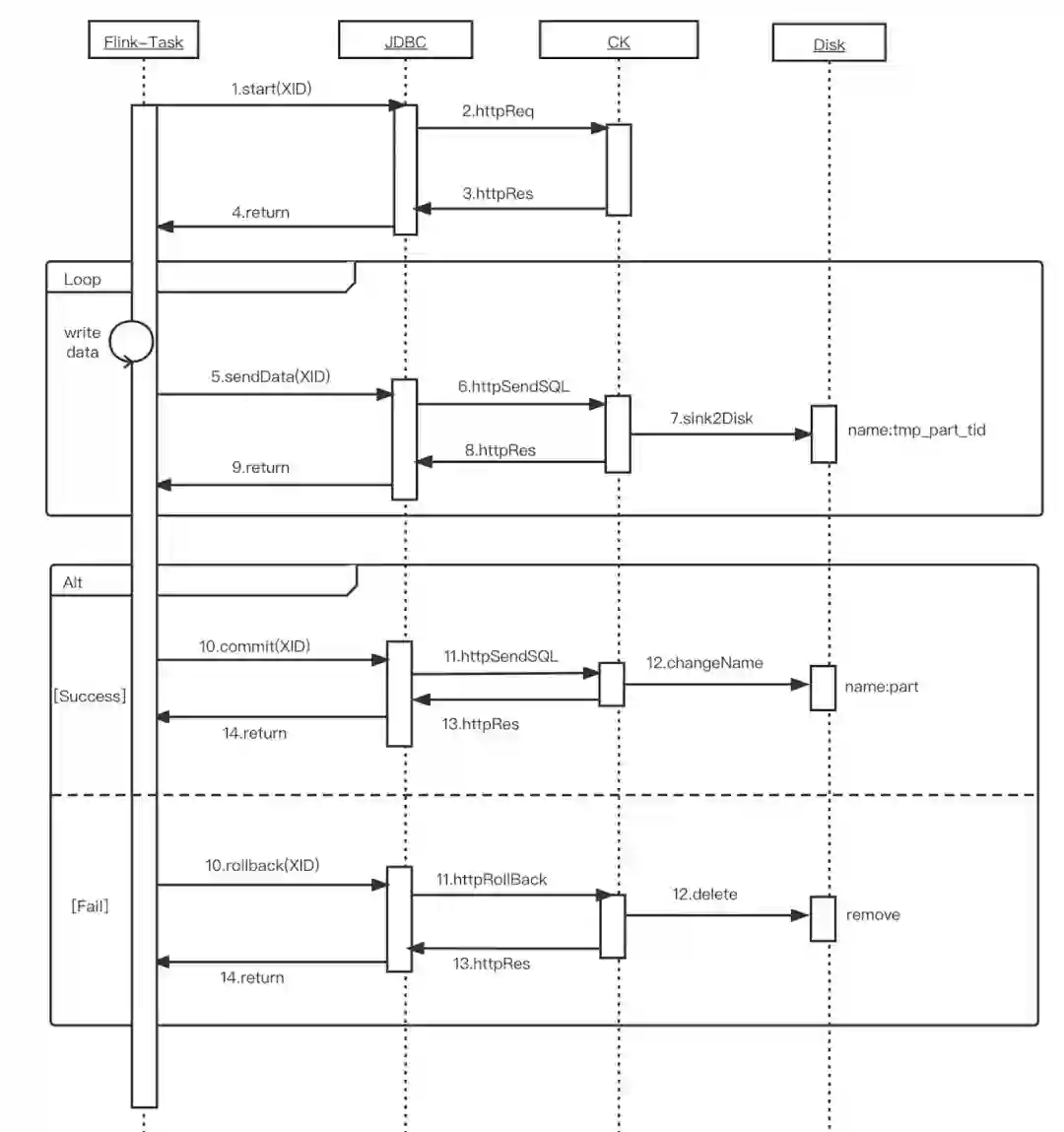
Client 向 ClickHouse 集群任意一个 ClickHouse Server 发送 Begin Transaction 请求,并携带由 Client 生成的全局唯一的 Transaction ID。ClickHouse Server 收到 Begin Transaction 请求时,会向 Zookeeper 注册该Transaction ID(包括创建 Transaction ID 及子 Znode 节点),并初始化该 Transaction 的状态为 Initialized。
-
Client 接收到 Begin Transaction 成功响应时,可以开始写入数据。当 ClickHouse Server 收到来自 Client 发送的数据时,会生成临时 data part,但不会将其转为正式 data part,ClickHouse Server 会将写入的临时 data part 信息,以 JSON 的形式,记录到 Zookeeper 上该 Transaction 的信息中。
-
Client 完成数据的写入后,会向 ClickHouse Server 发送 Commit Transaction 请求。ClickHouse Server 在收到 Commit Transaction 请求后,根据 ZooKeeper 上对应的Transaction的 data part 信息,将 ClickHouse Server 本地临时 data part 数据转为正式的 data part 数据,并更新Transaction 状态为Committed。Rollback 的过程与 Commit 类似。
-
如果创建 Transaction ID 过程中发现 Zookeeper 中已经存在相同 Transaction ID,根据 Zookeeper 中记录的 Transaction 状态进行处理:如果状态是 Unknown 则继续进行处理;如果状态是 Initialized则直接返回;否则会抛异常。
-
目前实现的事务还不支持分布式事务,只支持单机事务,所以 Client 只能往记录该 Transaction ID 的 ClickHouse Server 节点写数据,如果 ClickHouse Server 接收到到非该节点事务的数据,ClickHouse Server 会直接返回错误信息。
-
与写入数据不同,如果 Commit 阶段 Client 向未记录该 Transaction ID 的 ClickHouse Server 发送了 Commit Transaction 请求,ClickHouse Server 不会返回错误信息,而是返回记录该 Transaction ID 的 ClickHouse Server 地址给 Client,让 Client 端重定向到正确的 ClickHouse Server。Rollback 的过程与 Commit 类似。
3 ClickHouse-JDBC
4 Flink-Connector-ClickHouse
四 测试结果
1 ClickHouse事务性能测试
-
写入 ClickHouse 单批次数据量和总批次相同,Client端并发写线程不同性能比较。
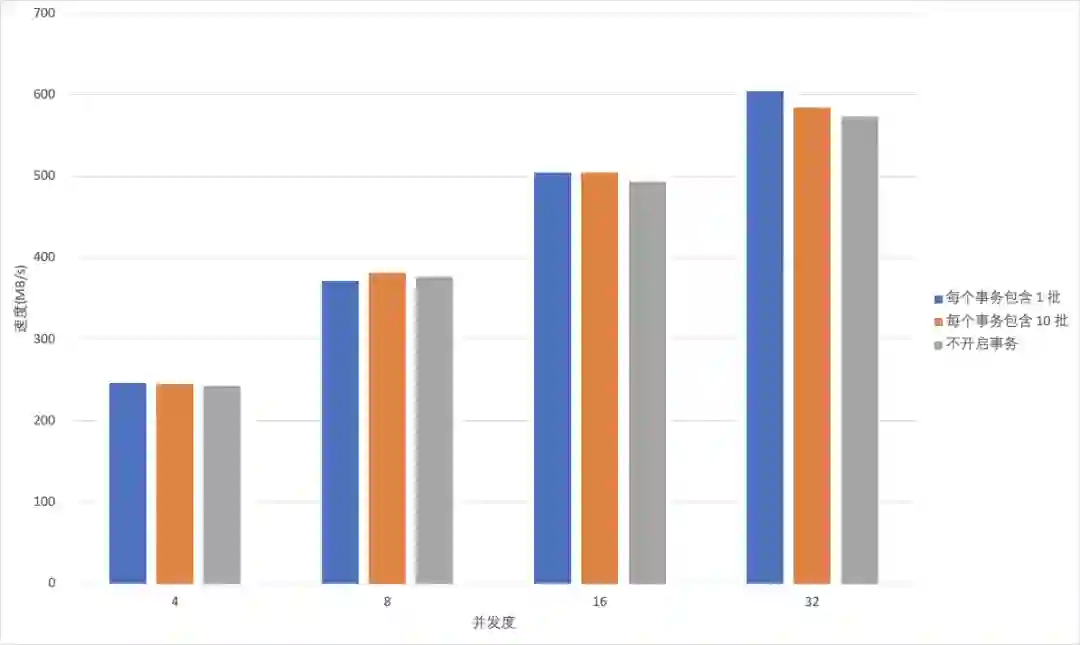
-
写入 ClickHouse 总批次 和 Client 端并发写线程相同,单批次写入 ClickHouse 数据量不同性能比较。
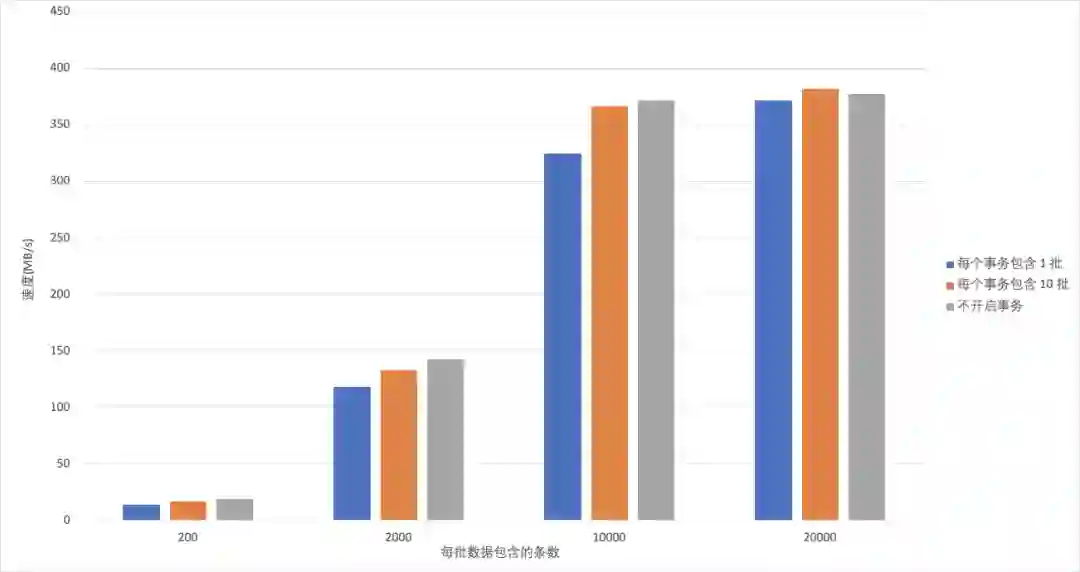
-
总体来说,开启事务对写入性能几乎没有影响,这个结论是符合我们预期的。
2 Flink写入ClickHouse性能比较
-
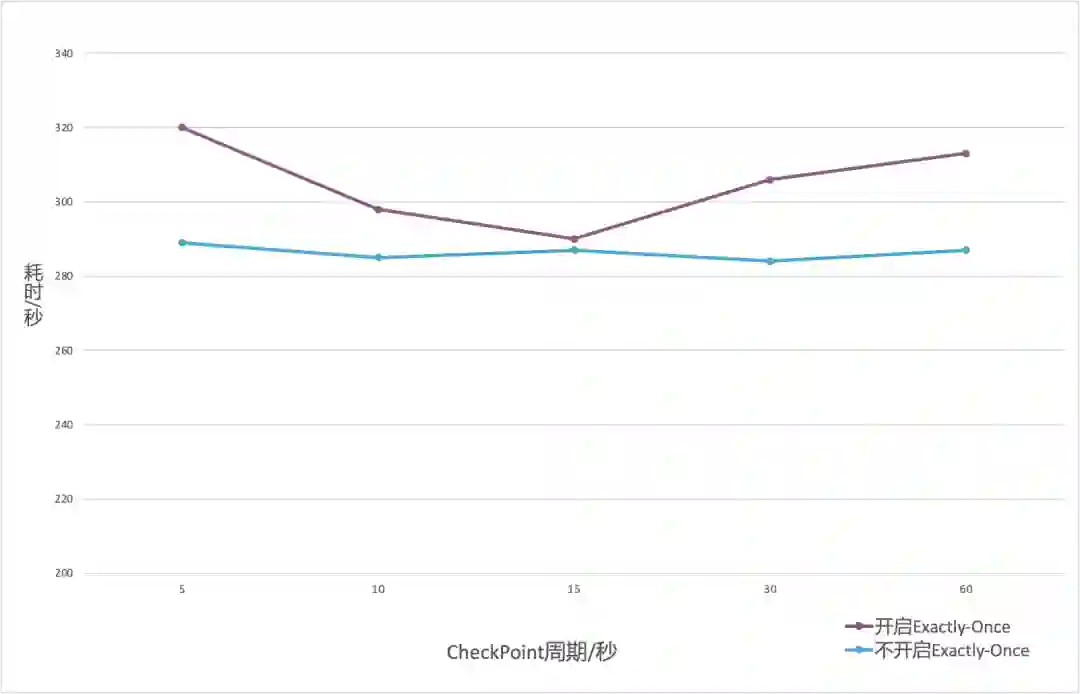
对于相同数据量和不同 checkpoint 周期,Flink 写入 ClickHouse 总耗时如图-8所示。可以看出,checkpoint 周期对于不开启 Exactly-Once 的任务耗时没有影响。对于开启 Exactly-Once 的任务,在5s 到60s的范围内,耗时呈现一个先降低后增长的趋势。原因是在 checkpoint 周期较短时,开启 Exactly-Once 的 Operator 与 Clickhouse 之间有关事务的交互过于频繁;在 checkpoint 周期较长时,开启 Exactly-Once 的 Operator 需要等待 checkpoint 周期结束才能提交最后一次事务,使数据可见。在本测试中,checkpoint周期数据仅作为一个参考,生产环境中,需要根据机器规格和数据写入速度进行调整。
-
总体来说,Flink写入Clickhouse时开启 Exactly-Once 特性,性能会稍有影响,这个结论是符合我们预期的。
五 未来规划
附录
《SaaS模式云原生数据仓库应用场景实践》电子书重磅来袭!
激活数据生产力,让分析产生价值!
点击阅读原文查看详情!
登录查看更多
相关内容
Arxiv
1+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月15日




相关VIP内容
相关资讯
相关论文
Arxiv
1+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月15日