ClickHouse 布道者郭炜:讨论ClickHouse的人需要了解它的设计理念

ClickHouse 素以社区火爆著称,无论是谁只要在社区里提交了有价值的想法或代码,管理者都会以最快的速度将它实现、上线。这种做法在激励着 ClickHouse 社区贡献的同时也给 ClickHouse 本身带来了无尽的活力,保证了 ClickHouse 在数据查询速度和稳定性方面的远超同行的霸主地位。几乎每一个月就更新一次的 ClickHouse,在过去的 2021 年实现了哪些优秀的功能呢?现在的 ClickHouse 适合在哪些场景下使用呢?未来 ClickHouse 发展的重点又在哪里呢?从 2019 年突然火爆起来的 ClickHouse 作为一匹黑马,在云原生场景下,是一匹能跑长途的黑马,还是仅仅是明日黄花呢?
基于对上述问题的好奇,我们特意邀请了 ClickHouse 中国社区发起人郭炜老师,请他从社区发起人的角度,聊聊飞速发展的 ClickHouse 在 2021 年有哪些最新场景应用,以及它的未来发展趋势。同时郭炜老师也是本次 QCon+ 案例研习社(北京站)「ClickHouse 集群版深度实践」专题的出品人,他邀请了国内 ClickHouse 深度使用者来分享,为大家带来 ClickHouse 集群版有关的实践经验,希望可以给 ClickHouse 使用者带来启发。
让我们一起来看看老师对 ClickHouse 最新场景和未来方向的思考吧。
郭炜:ClickHouse 今年迭代的功能非常多,我印象非常深刻的有:
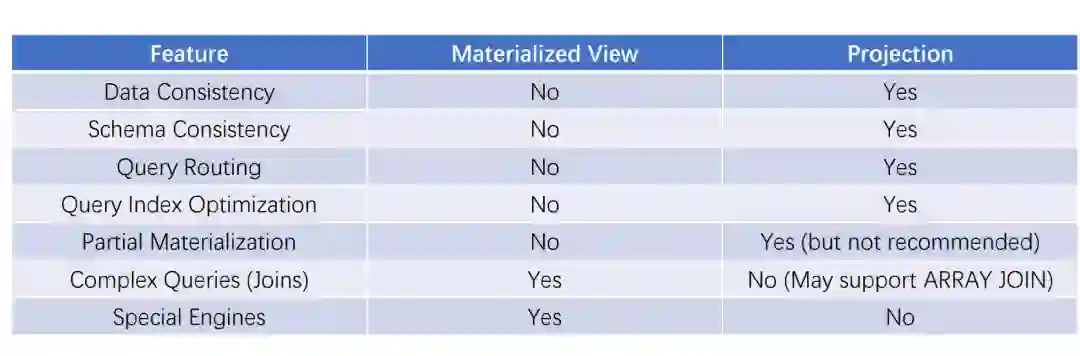
Projection:预聚合。这是今年发布的非常重要的一个特性,它进一步提高了常用并发度和汇总查询的速度,同时还保证了数据表和表内设计的一致性,非常方便地提供了类似下图中的可以实时更新的 Cube 查询:
JIT(just-in-time compilation):开启 JIT 优化后,根据社区小伙伴的评测,ClickHouse 在一些一元运算、二元运算、逻辑运算等方面性能提高了 1.5-3 倍,聚合步骤方面性能提升了 1-2 倍。
UDF(UserDefine Function):用户自定义函数。我特别期待其中 v21.11 里增加的对于各种语言 UDF 的支持,它大大减少了不同语言的开发者使用 ClickHouse 的学习成本,对于 ClickHouse 进一步发展有着重要意义。
Windows Function:开窗函数。这是高级 SQL 里最常用的一个特性。有了开窗函数,ClickHouse 就可以和 Oracle、DB2 等商业级别的数据仓库拥有一样的特性,对于本身速度又非常快的 ClickHouse 来说,简直是如虎添翼。
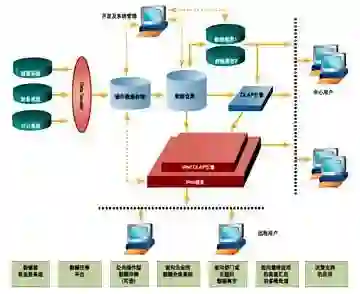
依赖极致的社区,ClickHouse 基本上每月都会更新一个版本。除了我上面提及的,ClickHouse 今年还增加了物化列,ALL,ANY,EXCEPT 等运算符、可以连接 XML 文件,新加了 Executable Table 等等其他的功能,大家可以去社区查看。
此外,ClickHouse CTO Alexey-Milovidov 会在 12 月 11 日的 ClickHouse China Meetup 上重点讲解 ClickHouse 的新特性和 2022 年的规划。
郭炜:ClickHouse 过去最常见的场景有三个:
用户行为分析:在采集用户行为日志之后,进行 PV、UV、留存、转化漏斗等操作,例如头条、快手、喜马拉雅等。
用户画像圈选:每个公司都拥有大量的用户和用户画像标签,如何快速从用户画像标签里圈选出某几类标签的人群,例如阿里、喜马拉雅等。
机器日志监控 & 查询:每台机器都产生大量日志,如何快速监控、查询机器日志,以确保整体服务没有问题。基本上所有的互联网公司都在这样使用 ClickHouse 的。
在今年数字化转型非常热门,有很多的企业用户加入到 ClickHouse 社区使用者阵营,因为我们也看到一些很有意思的场景,如:
IOT 场景:一些钢铁厂用 ClickHouse 采集、监控、分析自己内部 IOT 数据。我知道的最大的集群超过 100 台了。
政府大数据:ClickHouse 赋能政府合作伙伴,针对政府大量结构化和非结构化数据,进行大量数据质量整理和搜索。
网管监控:针对一些特殊 APP、特殊网站的日志,快速分析和快速报警。
关于数字化转型,我多啰嗦两句。事实上,ClickHouse 解决的是“数据分析的最后一公里”,解决了很多数字化转型企业数据分析的效率问题,包括:
大数据建设完成后最终产出了大量的 BI 报表、OLAP 分析,数据驱动距离业务远。
有经验的业务分析人员无法快速获得需要的数据,或者需要复杂 NoSQL 技术。
数据驱动还是“人”驱动,还有大量的提数、出报表的需求,而很多报表往往只用一次。
业务快速变化要求更新速度高,数据流无法让业务人员上手。
我举例的这些都是企业在数据化升级当中遇到的问题,因为越来越多的运营、产品、决策都需要用到灵活查询的一手明细数据,过去传统的层层数据仓库,OLAP 已经不能满足这些需求了,这正是 ClickHouse 的拿手好戏。
郭炜:ClickHouse 的开源版本为了追求极致的性能,从底层列式存储到上层向量化计算引擎其实都没有选择存算分离、弹性扩展的技术方案,甚至于本地化机器扩容的横向数据 Re-balance 都需要手动或者等待新数据自动填充。
因此,如果要实现云上的可动态伸缩、存算分离,Cloud-ClickHouse 需要重构底层代码,否则 ClickHouse 只是变成装在虚拟主机上的云本地版本,并不是真正的和 Snowflake 一样的云端数据服务。
当然,目前国内很多云是基于这个云本地版本模式提供 ClickHouse 服务的,即上层使用 ClickHouse 进行计算,为了实现底层云存储,有的使用性能不太高的 S3 接口,有的直接利用原来的格式,而底层用云存储上文件软连接方式解决存储扩展问题。
因为 ClickHouse 性能非常彪悍,所以这种云模式也可以带来一定的利润空间。当然,终极解决方案还是需要解决存算动态分离和动态伸缩问题,这需要俄罗斯团队携手全球社区人才共同解决。
郭炜:ClickHouse 的火爆除了它极致的速度还和它出现的时机有很大关系。我认为随着数据量的增大、使用场景的深入,普适性的数据计算引擎将会被细分,根据不同场景会出现各种各样不同的数据引擎。例如,用于流计算的数据库引擎、用于即席数据分析的数据引擎,用于物联网的数据引擎等等。
这是因为在巨大的数据量面前,想追求极致的性能和全部的适应性,必须在某些技术方案上进行取舍,从而达到引擎针对某些场景引擎的最大化支持。每一个引擎要在足够细分的赛道情况下要和其他引擎有数量级级别的差异。在数据暴增的情况下,过去的通用性引擎已经无法满足业务需求,所以场景性的计算引擎将会崛起。
ClickHouse 是个场景引擎崛起的例子,解决的是“数据分析最后一公里”的问题,不是用来解决所有问题的。这和当年我曾经工作过的 Teradata 和 IBM 的数据引擎设计是完全不同的。所以,大家以过去数据仓库、数据库的方法来衡量 ClickHouse 就很难理解它的一些设计,才会产生这些唱衰的声音。
随着数据量级的持续暴增,能解决所有问题的数据引擎几乎是不会存在的,未来的数据引擎一定是百花齐放百家争鸣的局面。如何和这些数据引擎并存、快速交换数据、管理数据是 ClickHouse 除了云化之外,主要面临到的问题。这些问题的解决就需要依赖周边生态和上下游的合作伙伴了。
如前面所述,ClickHouse 并不是数据仓库,它也不是数据导入和调度工具,它需要很多合作伙伴,包括:
数据仓库:可以用 Hadoop 生态来存储更多的冷数据,也可以用 Greenplum 来存储关系型数据,当然也可以用一些商业数据仓库来存储大量 3NF 数据;
关联查询:可以用 Presto、Doris 来弥补 ClickHouse 关联查询不强的问题。现在京东、趣头条都使用了 Presto 或者 Doris 的小集群来做关联查询,用 ClickHouse 的大集群来做日常非关联的分析;
数据导入:Sea Tunnel(原 Waterdrop)可解决 ClickHouse 数据导入不方便、容易不一致的问题。它可以从各种不同数据源里抽取数据,最终放到 ClickHouse 或者其他数据源里。唯品会和滴滴都在用这种方案。这个具体方案在我们 2022 的 QCon+ 会有分享。
其他:多任务时可以使用 DolphinScheduler 进行调度,展现时可以使用 E-Chart 等等。
开源组件一定是在自己最擅长的领域里做到最好才会有市场。一个上下游友好完整的生态,能够够极大地赋能开源组件,让它发挥出自己最大的作用。
郭炜:未来 ClickHouse 最值得期待的就是云化支持和场景扩展了。
ClickHouse 云支持的痛点,我前面已经讲过了。开源 ClickHouse 有非常多的创新设计(例如向量计算、向量存储、压缩算法等方面的创新设计),这些设计保证了它在它常用的场景里是全球最快。一些引擎虽然引用了它的代码,在一些测试场景优化后跑得快一些,但是实际使用起来依然无法超越 ClickHouse 的速度和稳定性。这样的创新如何在云时代实现新的飞跃是我非常期待的。这既然是 ClickHouse 未来的方向,也将是一场引领整体 OLAP 计算引擎的云原生革命。
而场景化是 ClickHouse 天然的属性,大家能看到今年 ClickHouse 还在推出新的表引擎。如前文所述,ClickHouse 的特长就是在细分场景里,面对超大规模数据查询和插入做到极致的快。而面对场景的 OLAP 引擎是我非常认同的。现在 ClickHouse 仍然在不断根据不同场景推出自己的表引擎,这些表引擎还在不断地创新,我相信它在未来会给我们更多的惊喜。
我补充一点,大家可能不知道,前几年 ClickHouse 核心团队都是个位数的,所以很多架构、功能都没有办法快速实现。现在整体开发团队达到百人规模,也成立了独立的公司,必将更快的发展。
此外,ClickHouse 成立公司后,Alexey-Milovidov 和 Ivan 就像过去 5 年中一样,支持着中国社区用户,并没有因为公司的出现而改变初心。我相信 ClickHouse 会在未来 5 年给大家更多的惊喜。
今年冬季的 ClickHouse Meetup 将在 12 月 11 日线上举行,这次分享的嘉宾非常多,除了 ClickHouse CTO 外,来自中国社区的 ClickHouse 资深使用者和贡献者也会有精彩分享,欢迎大家报名。
Qcon+ 北京站也安排了 ClickHouse 的专题,邀请了移动、联通、微信、唯品会、网易、云智慧等深度使用了 ClickHouse 的公司的技术 leader 和高级工程师,分享 ClickHouse 集群版上一些常见问题的解决方案,希望能帮助大家更好更快地进行数据查询。
嘉宾介绍:
郭炜,人称“郭大侠”,Apache Foundation Member,Apache DolphinScheduler PMC,Apache IPMC Member,ClickHouse 中国开源社区发起人和首席布道师。(ClickHouse 社区地址:https://clickhouse.com/docs/zh/whats-new/changelog/#new-feature )
中国软件行业协会智能应用服务分会副主任委员,TGO 北京董事会学习委员,全球中小企业创业联合会副会长,人民大学大数据商业分析研究中心客座研究员。
郭大侠曾任易观 CTO,联想研究院大数据总监,万达电商数据部总经理,并曾在中金、IBM、Teradata 公司担任大数据方向重要岗位,对大数据前沿领域研究做出过卓越贡献。
郭大侠一直致力于让“数据能力平民化”的事业上,本人参与多个开源项目,非常擅长深入简出讲解复杂的大数据和开源概念,被评为虎啸 10 年杰出数字人物。郭大侠促进多个开源社区在中国的落地以及中国开源项目在全球的发展,被评为 Apache Foundation Member 和 2021 年中国开源最佳人物之一。
ClickHouse 社区将于12 月 11 日本周六举办冬季线上 Meetup,精彩纷呈,有俄罗斯团队带来的最新和即将发布的 Feature 介绍,也有来自京东、B 站的关于 OLAP 和用户行为分析的实践分享,更有新的政务以及网络方面的实践经验,日程及免费报名链接:http://hdxu.cn/FEWSp
开源在中国发展的如火如荼,今年 Apache 基金会的 5 个新孵化项目全部来自中国,中国开源正在强势崛起。在此背景下,我们能如何参与这场开源盛宴,是不是只有贡献代码才是对开源的贡献?
本周五晚 8 点, Apache DolphinScheduler PMC Chair、Apache 孵化器导师、白鲸开源联合创始人代立冬将直播分享「如何行之有效地参与开源」,分享参与开源的思考和实践。
扫描二维码或点击阅读原文立即预约。