Hinton最新访谈丨他如何看待谷歌胶囊网络专利、神经科学以及下一代AI?

Geoff Hinton 是公认的深度学习先驱。2018 年,他与 Yoshua Bengio、Yann LeCun 共同获得了图灵奖。而在这之前的一年,他提出了一个想法 —— 胶囊网络(Capsule Network)。这是卷积神经网络的替代方案,它考虑了物体在 3D 世界中的姿势,尝试弥补当今计算机视觉软件学习能力上的不足,比如学会从不同的角度来识别同一个物体。
从那之后, Hinton 在学术界的公开活动有所沉寂,直到 2020 年。2020 年 12 月,在 NeurIPS 上,他的团队介绍了一项堆叠式胶囊自动编码器(stacked capsule autoencoders)相关的研究成果。更早之前 2 月的 AAAI 会议上,他谈到,胶囊网络是无监督学习的关键。4 月,Hinton 又重新提出了将反向传播作为人类大脑中的一种学习功能,并介绍了近似反向传播的算法 —— 用活动差异表示神经梯度(neural gradient representation by activity differences,简称 NGRAD)。

近日,在播客节目 Eye on AI 中,受到播客主理人、纽约时报资深记者 Craig Smith 的邀请,Hinton 进一步分享了他对于胶囊网络、下一代神经网络 SimCLR 框架以及 NGRAD 这三大技术成果的一系列思考。“数据实战派” 将 Hinton 的主要观点整理如下:
提出胶囊网络之后,它已经有所改变,而且更多的变化正在发生。
最初,我们用的是监督式学习,我们认为这样很容易让它运转起来,尽管我并不相信监督式学习。而在去年,我们换成了无监督学习,改用 Set Transformers。
胶囊网络做的是通过识别部分和部分之间的关系来识别整个物体。
如果你看到一个可能是眼睛的东西,以及一个可能是鼻子的东西,前者对应一个脸部的位置,后者对应一个脸部的位置。如果它们指向的脸的位置达成某种一致,那么你就会判断,嘿,它们的关系是正确的,可以做一张脸,所以我们将实例化一张脸。我们将激活脸部胶囊。
这里面有各种问题。其中一个问题是,你是否尝试在有监督或无监督的情况下训练它,使用无监督会更好,因为这样就不需要标签。但是另一个问题,如果你看到比如说直线线条中有一个圆状物,你不知道它是左眼还是右眼,或者是汽车的前轮后轮。
所以,要为该圆状物可能对应的各种存在 vote。
现在发生的情况是,每一个更高级别的胶囊都会得到一大堆 votes,几乎所有都是错误的。但是有一种方法可以纠正这种情况,那就是说,如果有其他胶囊喜欢这个 vote,如果有其他胶囊可以利用这个 vote,成为这个对象的一部分,那么就把这个 vote 导向到那里,而不是这里。
这就是动态路径选择(dynamic routing)的想法。尝试让所有的错误的 votes 去到它们可以作为正确 votes 的地方。

这是很复杂的工作。我们在堆叠胶囊自动编码器中使用的替代方法是,如果你发现了一些部件,假设是一个圆形、一个三角形和一个矩形,你并不知道它们是谁的部件,它们可能是很多很多东西的一部分。你要做的是让它们相互作用一下,利用它们之间的空间关系,让每个部分更加确信自己是什么样的部分。所以,如果你是一个圆,有一个三角形作为一个鼻子出现在你右边的位置,如果你是一个左眼,那么格外确认这一点。而这正是 transformers 非常擅长的地方。
在语言的情况下, transformers 对词语片段有一个表示。例如,“may” 这个词恰好是一个完整的单词, transformers 不知道它表示 “愿意”、“应该” 的意思,还是像 “六月” 和 “七月” 一样表示一个月份。transformers 所做的是,让这个片段的表示与其他片段的表示相互作用。如果句子中还有另一个片段,比如说 “六月”,那么 “may” 就更像是在说一个月份。而如果有另一个片段是,“会” 或 “应该”,“may” 就会更像一种情态动词。经过几层之后,这些片段可以消除歧义。也就是说,每个片段都意味着什么是可知的。
在语言中,这意味着对这个词存在着一个上下文敏感的表达,它在不同的意义之间消除了歧义。在视觉上,如果有一个圆,你想知道这个圆是眼睛,还是汽车的轮子,通过零件之间的相互作用,就可以做到这一点。在堆叠式胶囊自动编码器中,我们就是这么做的。
我们用第一层的各个部分让它们相互作用。因此,它们对自己是哪类事物的哪一部分会更有信心。一旦对自己是什么样的一部分更有信心,它们就会投票决定自己可能是什么样的一部分,就能得到更具体、更有信心的 votes。
而且不会有很多疯狂的 votes。一旦你确信一个圆圈可能是左眼,它就不会投票赞成成为汽车的后轮。这意味着容易找到集群。我们做到了这一点,而不是试图通过监督学习,通过贴标签。堆叠式胶囊自动编码器学会了创造善于重构部分的整体。这就是无监督学习。
至于胶囊网络专利的问题,我不知道申请专利的全部动机。但我认为,谷歌对通过专利赚钱不感兴趣。专利法保护的是第一个申请专利的人,不是第一个发明的人。所以,申请专利,只是为了保护。
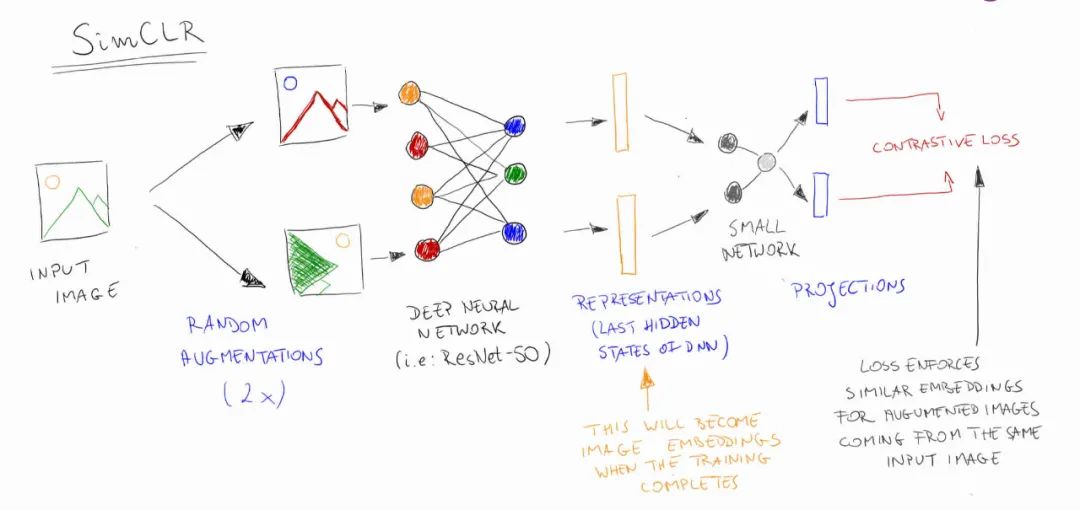
SimCLR 框架所要做的是说,我想学习用一种方式来表示一幅图像的一个局部,使同一幅图像的其他局部具有相似的表示。所以,你要做的是,先截取一幅图像,然后再截取另一幅图像。
再来一个神经网络,把它们转换成向量表示,转换成神经活动的模式。我们希望这些模式是相似的。如果它们来自同一个图像,你必须使它们相似;如果它们来自不同的图像,你必须使它们不同。这就是对比学习。
事实上,与这个想法相关的第一个研究,是我在 1993 年与 Sue Becker 合作的研究,然后是我在 2002 年的研究。但我们从来没有真正让它在图像上起到很好的作用,其他人在 2018 年重新提出了这个想法,并让对比学习在大规模图像数据上发挥作用。后来 Google lab in Toronto 的 Ting Chen 让这个想法达到了新的高度。
一旦你有了这个图像局部的表征,或者,这个神经网络可以把这个局部转换成一个表征,这样你就可以得到相似的表征,两个局部来自同一图像,那么你就可以用这些表征来尝试识别图像中的物体是什么。这个阶段是监督学习,但这不需要深深度网络。
而我们的想法是,通过使用深度网络来进行无监督学习,尝试为同一图像的两个不同的 patch 获得相同的表征或非常相似的表征。而对于不同图像的局部,则有不同的表示。像 Ting 用的是 ResNet,就直接学习把这些没有额外隐藏层的表征变成类标签。这就叫线性分类器。
它里面没有隐藏层。而且效果非常好。我们通过纯无监督学习得到的,基于这些表征的线性分类器,没有标签知识的线性分类器,现在在 ImageNet 上和有监督的方法一样好。前提是对于无监督学习,我们使用更大的 ResNet。如果你在 ImageNet 上使用标准大小的 ResNet,会有一定的错误率。
神经科学家一直非常怀疑大脑是否存在类似反向传播的机制。
其中一个大问题是,大脑是如何传递神经梯度的?因为在反向传播中,无论误差函数是什么,都需要根据误差的梯度来改变权重。它的原理是用神经活动的变化率来表示误差。
这很好理解,因为它可以有两个标志,也就是说,神经活动可以上升也可以下降,所以可以用这两个标志来表示误差。这也暗示了使用神经梯度的学习规则,一种叫做脉冲时间依赖的可塑性( spike timing dependent plasticity,STDP)的机制。也就是说,当改变突触强度时,它会随着误差导数的变化而变化。
这意味着根据突触后活动性的变化率来改变它,即突触前活动乘以突触后活动的变化率。这就是 STDP。事实上,我很久以来一直在建议使用神经活动差异。
我和 James McClelland 在 1987 年有一篇论文,提出神经活动的时间差异可以用作误差导数。那是在发现脉冲时间依的可塑性之前。到 2005 年,我又对活动差异产生了兴趣。最近,人们已经成功地让它发挥了作用。
到现在,我还是有点怀疑。我认为大脑可以做反向传播,如果它想的话。大脑有点笨拙,我现在对此持怀疑态度,因为我认为反向传播算法对大脑来说太适合了。大脑实际上处理的问题与大多数神经网络处理的问题非常不同。
大多数神经网络想要获得大量用有限的参数来表示的知识,例如,10 亿个参数。对于大脑来说,这参数太小了。这是大概一立方毫米的大脑所拥有的参数的数量。我们的大脑有无数的参数。
但是,大脑无法进行很多训练。因为我们只能活十亿秒或二十亿秒。
所以,我们的大脑拥有大量的参数但是没有太多的经验。而大部分神经网络能接受大量的训练,但是没有太多的参数。现在,如果有很多很多的参数却没有多少训练数据,我认为就需要做一些不同于反向传播算法的事。
我对可以让这种活动差异法很好地工作的方法很感兴趣。这种方法试图在自顶向下表示和自底向上表示之间产生一致性。比如说,如果你已经有了一些零件的层次结构,你就能通过查看图像在不同的级别将部件实例化。
然后从高级别的部分,从上到下预测低级别的部分。你希望看到的是自顶向下的预测(取决于较大的上下文)与自下而上的零件提取(取决于较小的上下文)之间的一致性。所以,从图像的局部区域中提取一部分,从这些部分中,你可以预测整体。从整体上,你自上而下地预测各个部分。但这些对部分的预测需要使用更多的信息,因为它们是基于整体的,所以需要的信息也更多。
你想要的是,自顶向下的预测和自底向上提取之间的一致性。而且,你希望它是特别一致的。你真正想要的是在同一幅图像上,它们是一致的,但在不同的图像上它们是不一致的。所以,如果从一张图片和自上而下的预测或另一张图片中提取部分,它们应该是不一致的。
这就是 SimCLR 中的对比学习。但它也提出了一种不同于反向传播的大脑学习算法。我非常兴奋。它不像反向传播那样有效,但它更容易植入大脑,因为你不需要反向传播很多层。
只需要比较自上而下的预测和自下而上的预测。我称它为 back relaxation。而且,在许多步骤中,它将向后获取信息,但是在试用中不会向后获取信息。反向传播会在一幅图像的单个表示上通过多层网络向后发送信息,而 back relaxation 每次仅将其返回到一层,并且它需要对同一图像进行多次表示才能完全返回。
因此,我对这种 back relaxation 算法真的很感兴趣,这或许可以解释大脑如何进行多层网络的学习。但是后来我发现那种纯粹的、贪心的自下而上学习算法也差不多。我没有足够仔细地进行控制。我在 2006 年引入的自底向上算法实际上可以很好地解决此问题。
这让我感到非常失望。我仍然想看看我是否可以使 back relaxation 算法比贪心的自下而上算法更好。
人们喜欢这种自上而下的预测,并使其与自下而上的提取相一致。你会希望这比一次一层地训练一堆自动编码器要好。否则就不值得这么做,训练一堆自动编码器,每次隐藏一层,结果证明是很好的。
最近在这些大型神经网络中发生的事情是,深度学习在 2006 年左右真正开始发展,我们发现如果训练一堆自动编码器或受限玻尔兹曼机器时,一次一层微调它,它能工作得很好。
这让神经网络再次运转起来。然后人们做了像演讲这样的事情。在 ImageNet 上,他们说不需要预先训练,不需要训练这些自动编码器,可以在监督下训练它。
这在一段时间内是没问题的。但是当得到更大的数据集和更大的网络时,人们又回到了无监督的预训练。这就是 Bert 所做的。Bert 是无人监督的预训练。GPT-3 使用无监督的预训练。这一点现在很重要。我们确实需要一些无监督学习算法。但是无监督学习算法现在变得更加复杂。
计算神经科学的巨大成功是利用 Rich Sutton 等人在时间差异方面所做的工作,并将其与大脑和多巴胺的实验研究联系起来。尤其是 Peter Dayan,他非常重要地展示了理论学习算法和大脑中实际发生的事情之间的关系。但这是关于强化学习的。
我认为强化学习是锦上添花。大部分的学习都是无监督学习。你必须了解世界是如何运作的,但不是通过强化信号来了解。你不会想通过蹩脚的方法来学习视觉。你要学习用其他的方法来做视觉。
我人生的主要目标是了解大脑是如何工作的,而所有这些试图了解大脑是如何工作的技术,并不能解释真正的大脑是如何工作的。它是有用的副产品。
但这不是我真正想要的。
胶囊网络、SimCLR、NGRAD 会 “合并” 吗?
如果你的研究已经有一段时间了,你会有很多关于事物应该如何发展的深刻直觉,然后你会有一些特定的项目,这些特定的实例也会与这些直觉相结合。通常看起来很独立的项目最终会合并。但就目前而言,胶囊网络的工作有些不同。尽管这三个都可以合并在一起。
如果我们能从上到下的预测和从下到上的预测在一个对比的意义上一致,也就是说,它们对相同的图像很一致,对不同的图像很不同,这将适合堆叠式胶囊自编码器。
但它也是一个对比学习的例子,就像 SimCLR 一样。这也可以解释大脑如何学习多层网络。所以很明显,我和很多人一样,想找出所有问题的解决方案。只是,我们得更现实一点,我们只能了解其中的一部分,不可能一下子得到所有的东西。
堆叠胶囊自动编码器的一个重要动机是,它会有更像我们用的表示方式。
一个经典的例子是,如果有一个旋转了 45 度的正方形,你有两种完全不同的方式来感知它。一个是倾斜的正方形,另一个是直立的菱形。这取决于你使用的表示方式。卷积网络没有两种不同的表示方式。
它们只有一种表示。为了得到两种不同的表示方式,你需要一个参照系。我们感知的一个非常强烈的特征是,我们给事物强加了参照系并根据这些参照系来理解它们。如果强加一个不同的框架,那么对事情的理解就会完全不同。
这是制作堆叠胶囊自动编码器的主要动机之一。它也是一个计算机图形处理算法。所以,在计算机图形学中,你用一个特定的坐标系来代表一个房子。然后相对于那个坐标系,你才能知道窗户和门的位置。
这就是我们在神经网络中需要的表现方式,如果神经网络在表达对象方面更像我们的话。目前深度神经网络非常擅长分类,它们的分类方式与人类完全不同。所以,他们更依赖于纹理之类的东西。
它们可以看到各种我们不敏感的复杂纹理。这就是为什么会有这种情况,两个东西在我们看来完全不同,但在神经网络看来是相似的。
Refrence:
https://www.eye-on.ai/