【重磅】Hinton大神Capsule论文首次公布,深度学习基石CNN或被取代

【AI WORLD 2017世界人工智能大会倒计时 11 天】
“AI达摩”齐聚世界人工智能大会,AI WORLD 2017议程嘉宾重磅发布
在2017年11月8日在北京国家会议中心举办的AI World 2017世界人工智能大会上,我们邀请到阿里巴巴副总裁、iDST副院长华先胜,旷视科技Face++首席科学家、旷视研究院院长孙剑博士,腾讯优图实验室杰出科学家贾佳亚教授,以及硅谷知名企业家、IEEE Fellow Chris Rowen,共论人脸识别等前沿计算机视觉技术。
抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
大会官网:http://www.aiworld2017.com
新智元报道
编辑部
【新智元导读】Hinton要打造下一代CNN的Capsule细节终于通过一篇论文发布。本文带来详细介绍。此前,Hinton曾讨论了用“capsule”作为下一代CNN的理由。他解释了“标准”的卷积神经网络有什么问题?结构的层次太少,只有神经元、神经网络层、整个神经网络。所以,我们需要把每一层的神经元组合起来,形成一个组,并装到“舱”(capsule)中去,这样一来就能完成大量的内部计算,最终输出一个经过压缩的结果。“舱”(capsule)的灵感来自大脑皮层中的微柱体(mini-column)。Hinton要革CNN的命,要知道,CNN的代表人物之一,可是大名鼎鼎的Yann LeCun。

Hinton的“胶囊”(Capsule)终于来了。从2011年就开始说的概念,现在终于实现了,而且效果看上去很不错。

可以看出,capsule在参数较少的情况下,在NORB基准上实现了更好的效果,超越了CNN,后者还需要更多处理。
论文地址:https://arxiv.org/pdf/1710.09829v1.pdf
我们先来看这篇论文,摘要是这么写的:
胶囊是一组神经元,其活动向量表示特定类型的实体(例如物体或物体部分)的实例化参数。我们使用活动向量的长度来表示实体存在的概率及其表示实例参数的方向。一级活性胶囊通过转化基质对高级胶囊的实例化参数进行预测。当多个预测相同时,较高级别的胶囊会被激活。我们显示了,有鉴别(discriminatively)训练的多层胶囊系统在MNIST上实现了最先进的性能,并且在识别高度重叠的数字时比卷积网明显更好。为了达到这些结果,我们使用了一个迭代的路由协议机制:一个较低级别的胶囊希望将其输出发送到更高级别的胶囊,其活动向量具有大的标量积,预测来自较低级的胶囊。
具体看,作者在论文中介绍,活动胶囊内神经元的活动表示图像中存在的特定实体的各种性质。这些属性可以包括许多不同类型的实例化参数,例如姿势(位置,大小,方向),形变,速度,反照率,色相,纹理等。一个非常特殊的属性是图像中实例化实体的存在。表示存在的一个方法是使用一个单独的逻辑单元,其输出是实体存在的概率。在本文中,我们探索一个有趣的替代方法,即使用实例化参数向量的总长度来表示实体的存在并强制向量的方向来表示实体的属性。我们确保胶囊的矢量的输出不超过1。
胶囊的输出是矢量,因此可以使用强大的动态路由机制来确保胶囊的输出被发送到上层中的适当母体。最初,输出被路由到所有可能的父母,但是通过将总和为1的系数缩小。对于每个可能的父代,胶囊通过将其自身的输出乘以权重矩阵来计算“预测向量”。如果该预测向量具有输出的大标量积可能的父母,则存在自上而下的反馈,这具有增加该父母的耦合系数并减少其他父母的效果。这增加了胶囊对该亲本的贡献,从而进一步增加了胶囊预测的标量积与父母的输出。
这种类型的“按协议路由”应该比通过max-pooling实现的最原始的路由更有效,这允许一层中的神经元忽略下面层中本地池中最活跃的特征检测器。论文也展示了动态路由机制是实现分割高度重叠对象所需的“解释”的有效方式。
卷积神经网络(CNN)使用学习特征检测器的翻译副本,这使得它们能够将在图像中的一个位置处获得的良好权重值的知识转换为其他位置。这已经证明在图像解释方面非常有帮助。即使我们用矢量输出胶囊替代CNN的标量输出特征检测器,并且通过协议来最大限度地合并,我们仍然希望在空间上复制学习的知识,所以我们让最后一层胶囊是卷积的。与CNN一样,我们制作更高级别的胶囊可以覆盖较大的图像区域,但与max-pooling不同,我们不会丢失该区域内实体精确位置的信息。对于低级胶囊,位置信息是由胶囊活动的“地点编码”。当我们上升层级越来越多,位置信息在胶囊的输出向量的实值分量中被“速率编码”(rate-coded)。这种从地位编码到速率编码的转变与高级别胶囊代表具有更多自由度的更复杂实体的事实相结合,这表明胶囊的维数在升级时应该也在增加。
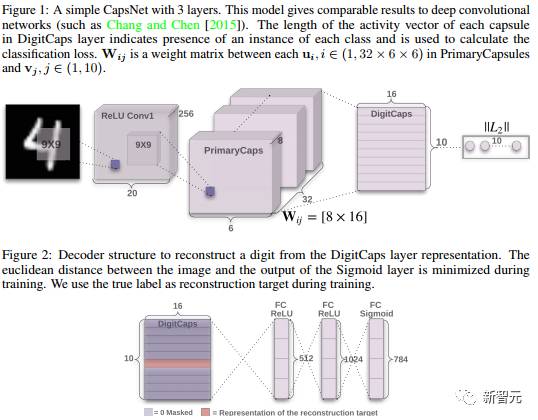
上图是论文中介绍的胶囊——简单的CapsNet的结构。一个CapsNet共有3层,两个卷积层和一个全连接层。
30年来,最先进的语音识别使用具有高斯混合的隐马尔可夫模型作为输出分布。这些模型在小型计算机上容易学习,但是它们具有致命的表征限制:与使用分布式表示的循环神经网络相比,它们使用的一个n表示指数级无效。要将HMM目前为止已经生成的字符串的信息量加倍,我们需要将隐藏节点的数量做指数级增加。对于一个循环网络,我们只需要将隐藏神经元数量加倍就行了。
现在卷积神经网络已经成为物体识别的主要方法,所以询问是否存在可能导致其死亡的任何指数低效率是有道理的。一个好的候选人是卷积网络将概念化到新观点的困难。处理翻译的能力是建立在,但是对于仿射变换的其他维度。我们必须在网格上的复制特征检测器之间选择指数级与维数,或以类似的指数方式增加标记的训练集的大小。
胶囊(Hinton等人[2011])通过将像素强度转换为识别片段的实例化参数的向量来避免这些指数低效,然后将变换矩阵应用于片段以预测较大片段的实例化参数。学习编码部分和整体之间的内在空间关系的转换矩阵构成了视角不变的知识,自动将其概括为新观点。
胶囊作出非常强的代表性假设:在图像的每个位置,胶囊代表的实体类型至多为一个实例。这种假设是被称为“拥挤”的知觉现象(Pelli et al。[2004])所驱动,消除了约束问题(Hinton [1981]),并允许一个胶囊使用分布式表示(其活动向量)进行编码在给定位置的该类型的实体的实例化参数。
此前,在一次演讲中, Hinton讨论了用“capsule”作为下一代CNN的理由。
他解释了“标准”的卷积神经网络有什么问题?结构的层次太少,只有神经元、神经网络层、整个神经网络。所以,我们需要把每一层的神经元组合起来,形成一个组,并装到“舱”(capsule)中去,这样一来就能完成大量的内部计算,最终输出一个经过压缩的结果。“舱”(capsule)的灵感来自大脑皮层中的微柱体(mini-column)。
CNN的代表人物是Yann LeCun,所以这也可以看成是两位大神在深度学习观点上的一次正面交锋。新智元带来最全面的介绍:

2017年8月17日,Hinton在加拿大多伦多菲尔兹研究所开讲,主题是《卷积神经网络有哪些问题》,这是加拿大新成立的“向量研究院”(Vector Institute)2017-2018机器学习的发展和应用课程的一部分。
2017年3月30日,Vector Institute宣布成立,Hinton是这一机构的首席科学顾问。发布会上Vector 方面表示将致力于人工智能的前沿研究,专注在机器学习和深度学习领域的变革性研究。该研究院将与学术机构、孵化器、加速器、初创企业以及大公司展开合作,推动加拿大人工智能的研究及商业化应用。
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
卷积神经网络的集大成者是Yann LeCun,现Facebook 人工智能实验室的主管,它被业界誉为“卷积神经网络之父”。在本次演讲中,Hinton也多次提到了LeCun的观点,提到两人在学术上的不同观点。
在本次演讲中, Hinton讨论了用“capsule”作为下一代CNN的理由。
一个卷积神经网络(CNN)或者神经元只有一个输出AND,在处理两个输入向量时做得不好。一个“capsule”是一个多值描述符号,对应输入向量中的一个特征。
Hinton在开场白中说:“在中国,有超过1万名研究生在研究神经网络”,但是这里面有一个误区,他说:“神经网络与大脑的关系不大,它们虽然是受到大脑启发的,但是因为这是我们手动搭建的,大脑是一个完全不同的架构,并且更高效。”

“标准”的卷积神经网络有什么问题?
结构的层次太少:神经元、神经网络层、整个神经网络
我们需要把每一层的神经元组合起来,形成一个组,并装到“舱”(capsule)中去,这样一来就能完成大量的内部计算,最终输出一个经过压缩的结果。
“舱”(capsule)的灵感来自大脑皮层中的微柱体(mini-column)。

每一个“舱”表示的是它所检测到的类型的一个多维实体的存在和实例化参数。
比如,在视觉通道上,一个“舱”会检测到物体的具体对象的类型。
一个“舱”会输出两个东西:
1. 被呈现的对象可能的分类;
2. 对象的大概状态,包括位置、朝向、大小、变形、体积和颜色等等。

“舱”可以完成同步过滤(filtering)
一个典型的“舱”从下一层的“舱”中接收多维的预测向量,并且寻找一个更紧致的预测群(cluster)。
如果找到了一个一个更紧致的预测群(cluster),它会输出:
一个高概率,即某一类型的实体存在在这个区间
群的引力中心,也就是实体的大概状态
这种方法在过滤噪音上做得非常好,因为高维度的一致性的发生并不是偶然。
它比一般的“神经元”表现得要好很多。

当下用于对象识别的方法:
Convnets(卷积网)使用多层学习到的特征检测器。(这一点很好)
在卷积网中,特征的检测是局部的,每一种类型的检测器被复制到整个空间中。(这一点很好)
在卷积网中,层次越高,特征检测的空间领域变得越大。(这一点很好)
特征提取层与次抽样层交叉存取,将相同类型的相邻特征检测器的输出汇集到一起。(这是问题所在)

将复制的特征检测器的输出进行结合的动机
池化在每一层都会给予一个小量的转换变量
最活跃的特征检测器的精确位置会丢失
可能,这也是ok的,如果池化堆叠很多次或者如果特征对其他特征的相对位置进行编码的话
池化减少输往特征提取下一层的数量
这将让我们在下一层拥有更多的特征类型(更大的领域)

一个卷积网络中拥有什么类型的认知
深度卷积网络中最后一层的激活行为就是一个认知
感知包含了图像中许多物体的信息
但是,物体之间的关系是怎样的?关系的认知并没有经过训练
向一个深度循环神经网络的最初隐藏层的状态上加入上文提到的认知,并且训练RNN来生成字幕(不需要对卷积网络进行预训练)

对于池化(pooling),存在以上 4 点争论:
不合乎我们对形态感知的心理认知
它无法解释为什么把固有坐标系分派给对象后,会有如此明显的效果。
它在解决的是错误的问题
我们想要的是 equivariance,不是 invariance。想要的是 Disentangling,而不是 discarding。
它无法使用基本的线性结构
它不能利用能够完美处理图像中大量variance的自然线性流形。
池化对于做动态routing也很差
我们需要route进入神经网络的输入的每一部分,好知道如何处理它。找到最好的 routing 相当于为图像做parsing。

关于争论1:
四面体Puzzle:关于坐标系能做什么的演示
用一个平面将一个固体四面体切为两块
把这两块拼回成为一个四面体有多难?
一位MIT教授试了10分钟,然后写下了一个证明,证明这不可能实现
这个小任务为什么这么难?我们需要一个解释。

反向四面体Puzzle
想象一下,用一个平面切开一个固体四面体,得到一个方形的cross-section;
如果你用一种方式去考虑这个四面体,做到这点并不难;而如果你用标准的方式去考虑这个四面体,就几乎不可能做到。

一些更多的心理学证据,显示了我们的视觉系统在抓住物体形状时,利用了坐标系。

关于争论2:Equivariance vs Invariance
卷积神经网络努力在让神经活动对视点上的小变化invariant,方法是通过在一个“池”内合并这些活动
—这个目标是错误的;
—它由这样一个事实驱动:最终的 label 需要 viewpoint-invariant
以equivariance为目标会更好:视点中的变化引发了神经活动中的相应变化
—在认知系统中,是 weights 编码了viewpoint-invariant knowledge,而不是神经活动。
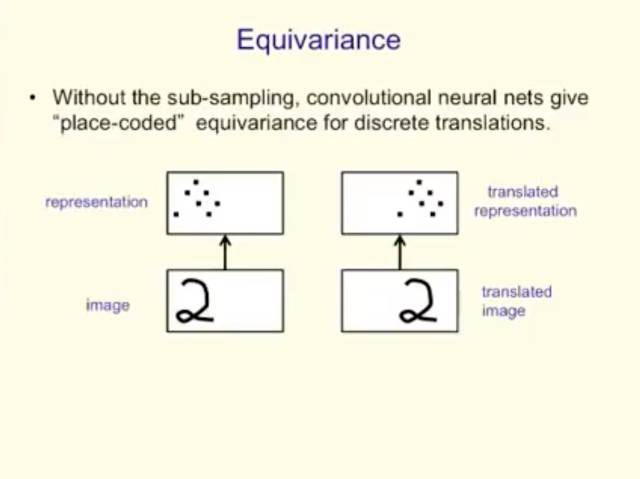
Equivariance
没有sub-sampling,卷积神经网络为discrete translations 给出了“place-coded” equivariance。

两类 equivariance
如果一个低级别部分移动到了一个非常不同的位置,它会被不同的capsule表征
—这是“place-coded” equivariance。
如果一个部分仅移动了很短的距离,它仍会被同样的capsule表征,但capsule的输出将会变化
—这是“rate-coded” equivariance。
更高级别的 capsules 有更大的domain,所以低级别的place-coded equivariance 转化为了高级别的 rate-coded equivariance。

关于争论3:推算形状识别到非常不同的视点
目前的神经网络智慧
—学习用于不同视点的不同模型
—这要求大量训练数据
一个好得多的方法
—同样形状的图像流形在pixel intensities的空间里是高度非线性的
—向流形是全局线性的空间转化(即,图像表征使用了明确的形态坐标)
—这使得大量推算成为可能

使用计算机图像使用的全局线性流形在视点上泛化
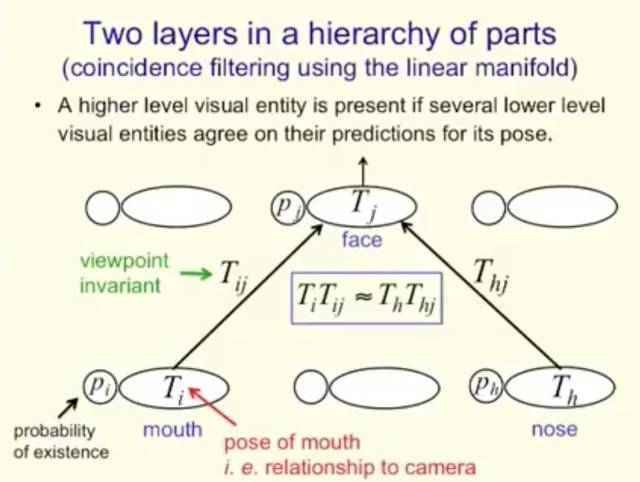
在部分层次中的两层(使用线性流形的coincidence filtering)

关于争论4:我们需要 route 图像中的信息,好让神经网络可以理解
对于复杂形状来说,我们不希望用 small stride 复制所有位置的知识
—用某种方法能 route 信息到一个单独的能够处理它的 capsule会更好
—但这一信息可能会在图像中的任何位置出现
眼球运动拥有伟大的routing机制,但速度慢
—神经网络还有什么方法可以 route 信息?
深入了解AI 技术进展和产业情况,参加新智元世界人工智能大会,马上抢票!

【AI WORLD 2017世界人工智能大会倒计时 11 天】点击图片查看嘉宾与日程。
抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
AI WORLD 2017 世界人工智能大会购票二维码:



