淘宝 | GNN如何在稀疏推荐场景发力?

在视频推荐系统中,有相当一部分用户的行为较为稀疏,基于行为序列建模的方式无法较好的对这部分用户的兴趣进行表征. 针对场景行为稀疏的问题,学术和业内有多种解决方案。最直观的方案是深度发掘side info的威力,在用户和内容缺乏行为关联的情况下,通过side info构建更多的关联,这一块的内容我们在基于content-base召回有一些实践,感兴趣的同学可以移步https://mp.weixin.qq.com/s/Ari-xyJPkla-h5IsQAeiJQ;第二种是通过预训练的方法,通过行为稠密用户训练得到表达较为充分的公共模型,然后在行为稀疏用户上进行fineturn;第三种可以利用跨域行为,在源域行为稀疏的情况下,利用其它域内的行为构建联系,但是这个存在的问题就是其它域内学习到的兴趣并不一定能真正代表用户在源域内的兴趣;第四种是利用知识图谱构建图模型,通过Meta-learning的范式学习出用户表达;其他的也有通过构建u2u的同构图,通过相似行为稠密用户去表达行为稀疏用户,但是这种方式依赖于u2u的图谱构建。
本文拟从图模型的角度出发,探索解决用户稀疏行为的图模型方法。事实上,图模型在推荐系统中应用的越来越广泛,但是传统的图模型在构图的时候依赖用户的行为,我们尝试在构图的时候加入内容图谱的信息,通过内容图谱构建用户行为图。图模型在实际推荐系统中的应用主要是两类方法:path-based和embedding-based.
其中,embedding-based model就是将图网络先预训练成embedding,然后将embedding输入到模型中,比如KGE,CKE,DKN,SHINE等都是这种方式,这种方式的好处是可以分开建模,但是缺点是预训练和推荐任务是分离的,在embedding的训练上没法做到面向任务训练,而且存在图结构更新的问题。另外一种就是path-based方法,主要是把图谱原始结构输入,比如RippleNet,Personalized Entity Recommendation (PER) 和 Meta-Graph Based Recommendation,KGAT等,这种方式是把整个图谱原始信息输入到模型中去,靠模型端到端的学习出对应表达。
针对用户行为稀疏的问题,我们提出了一种较为新颖的稀疏行为场景下序列扩展的方法,通过v2v+知识图谱的行为扩展方式,并结合多种信息聚合方式,我们迭代了多版模型,在行为稀疏用户上取得了pctr +6%的效果。
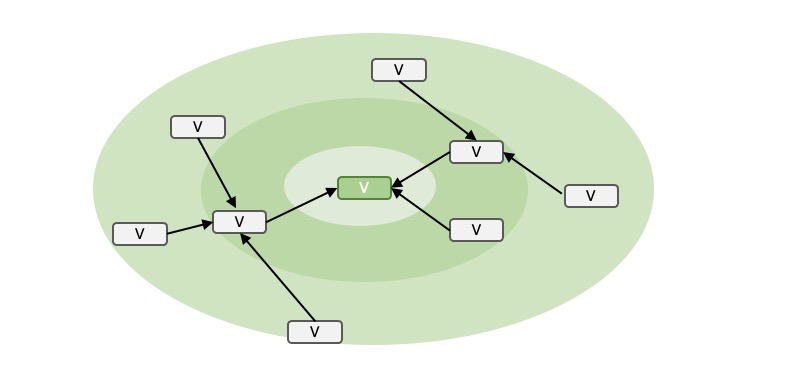
和一般的图模型建模思路类似,我们提出的稀疏场景下行为序列扩展方法一共包含两个部分,第一步基于某种数据构建图的拓扑结构;第二步在图中进行某种信息聚合。其中,拓扑结构的建立我们结合了u2v2v和基于图谱的图模型,其中u2v2v虽然只是user->video->video的扩展,但是实际还是u2u的扩展关系。因为其中的video->video的关系是通过整个训练集合中video->user->video的关系构建得到。如图所示,用户小明的行为中的视频序列,会同时有多个行为较为稠密的用户也同时感兴趣,而这部分用户的兴趣我们可以通过他们点击/观看的视频表示,这样子就可以通过u->v->u->v的扩展方式将行为稠密的用户感兴趣的视频去表达用户小明,而其中小明行为->稠密用户->稠密用户感兴趣视频的二部图则可以用swing v2v来表达。
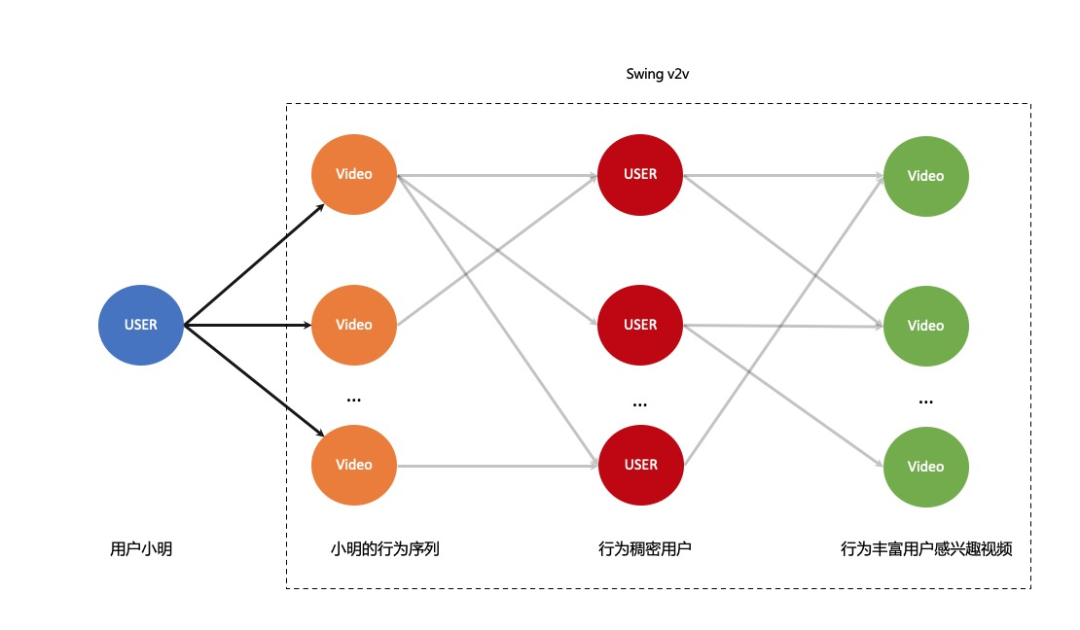
这样通过v2v的方式,间接的实现将行为稠密的用户的表达(video set)去表征行为稀疏的用户。考虑到这种扩展的关系不是完备的,所以还会用基于认知图谱的图模型扩展的结果进行辅助扩充,保证扩展关系的完备性。通过v2v和图谱的扩展之后,对于行为稀疏的用户我们可以将拓扑结构由序列变为图谱,如下图所示。
在得到图谱结构之后,如何表征用户行为便是下一步需要解决的问题了。在传统的序列+transformer的架构中,序列embedding之后经过self-attention便得到序列的初始表达。序列拓扑结构改变之后,信息聚合的方式也相应会发生变化。从以往的序列attention的范式变为按照图拓扑结构进行聚合了。一般可以通过某种聚合函数对one-hop或者multi-hops节点的信息进行聚合。一般的聚合方式包括:
GCN聚合
GraphSage聚合
Bi-Interaction Aggregator
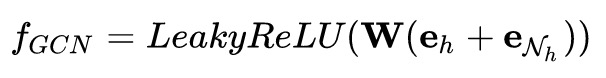
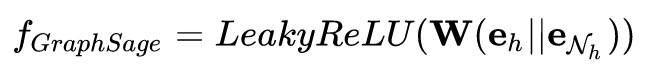
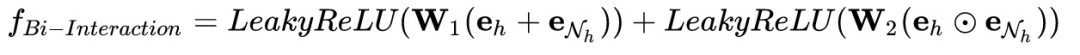
我们先后迭代了基于rippleNet、基于GAT、图谱序列生成、KG-gating的方式,下面分别介绍。
▐ 基于图注意力的深度召回模型(GADM)
通过用户初始锚点,构建初始的ripple set (h,r,t), 其中h可以表示为初始的兴趣锚点,r是兴趣锚点到扩展节点的relation, t则表示扩展节点。
在原始的论文中,第二步是计算target item v和每一个扩展节点(h,r)的attention, 然后利用attention对扩展节点t进行加权求和得到output. 但是我们使用的场景是召回模型,这里使用target item来进行attention不现实,所以我们使用的relation和head的attention对tail进行加权求和,得到head的ripple 表达。
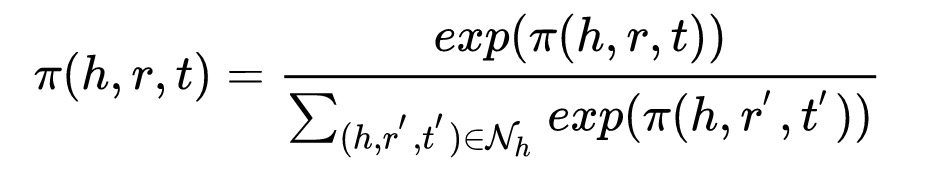
接着,在第二个hop中,将1-hop的tail作为2-hop的head, 1-hop得到的表达作为2-hop的head的表达(实际中在初始阶段为了上线rt, 我们只采用了1-hop)。
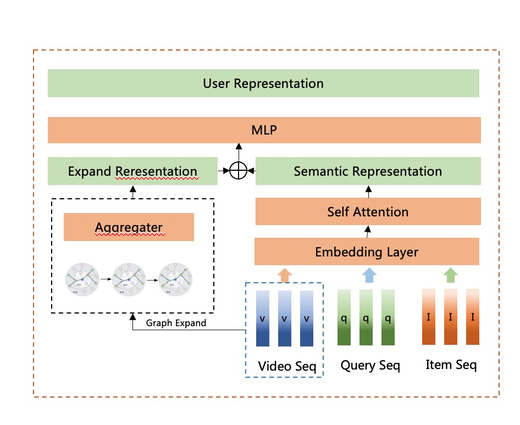
经过rippleNet的聚合之后,我们可以得到每一个感兴趣种子视频的表达,然后pooling成用户表达. 线上我们也没有扔掉原有序列表达,而是concat到一起作为用户序列表达。整个模型结构如下:
此外,考虑到聚合的时候的方式,依赖的是relation的表达,但是实际上relation所能表达的信息有限。所以我们进一步采用了类似于KGAT的聚合方式,通过参数自适应调节attention权重。
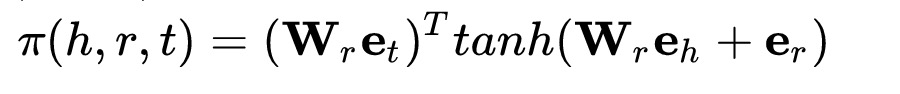
模型上线之后,也取得了不错的效果. 其中 GADM-v1 pctr+1.5%, uctr +2.65%, GADM-v2 pctr +2.1%,uctr +1.4%。
▐ 适应生成式图模型扩展召回模型
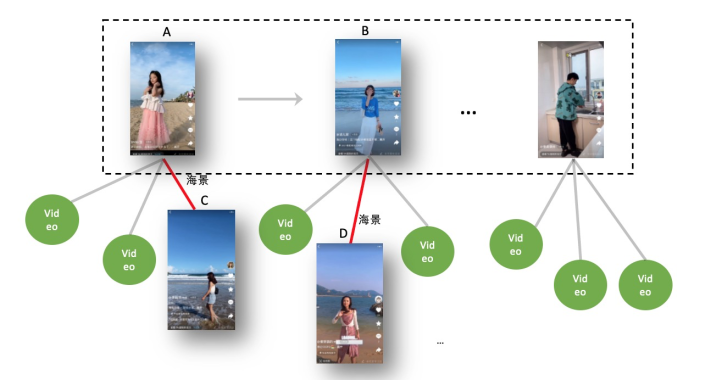
v1版本通过v2v+知识图谱构建用户行为图谱,将原本的行为序列进行单向进一步拓扑展开,每个行为内的子图中进行信息聚合,这些行为和对应的图谱是不存在时序关系的, 而且单个行为锚点的信息聚合attention仅限于内部,两两之间并没有产生关联,我们最终采用的聚合的方式也是对每一个子图谱的结果进行avg pooling, 各个子图之间孰轻孰重并没有区分。但是实际上,各个子图之间的边的权重应该互相影响,如下图所示,其中用户行为中有两个视频A,B都能扩展出海景(Relation)的视频C,D(Entity), 那么在进行聚合的时候,B和D之间的关系理应得到进一步加强,这种自适应的能力不同于以往的解决静态图谱数据的方法(KGCN 或者 Topic-sensitive random walk),他依赖于对连续行为之间的关系进行建模。
借鉴NMT中的encoder-decoder架构(主要是使用其中的attention),我们提出了自适应的生成式图注意力模型(Self-adaption Generative Graph Attention, SGGA) , 整体架构如下:
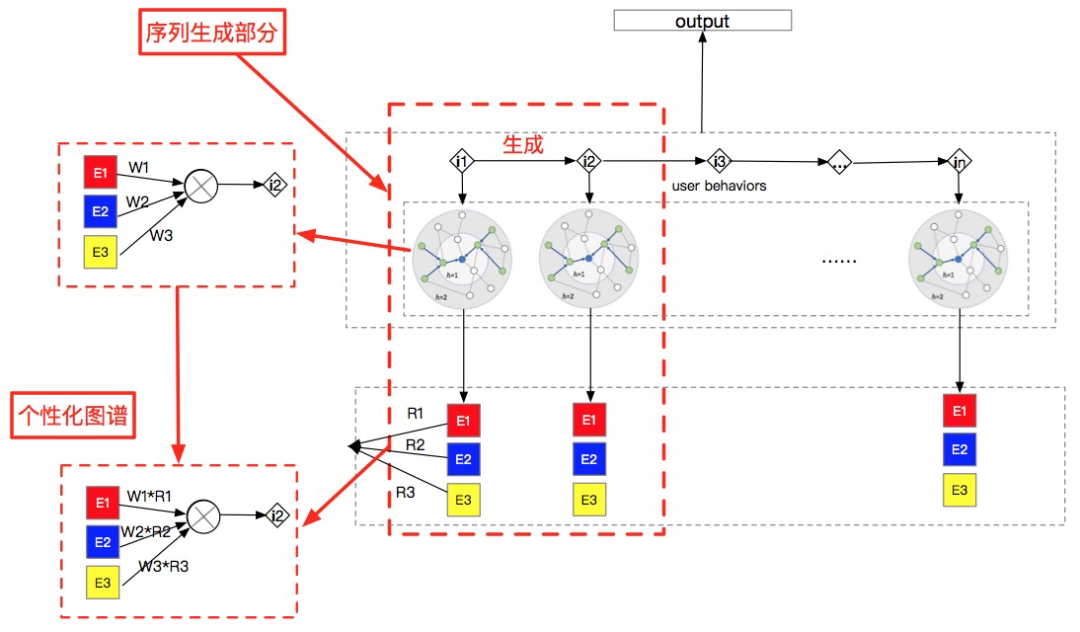
该模型基于v1模型基础,加入了encoder-decoder架构来建模序列之间的权重影响程度,其中,encoder-decoder的架构如下所示,encoder输入的是前面行为对应的图谱展开(考虑性能我们取的前置行为长度为1),主要是Tail和Relation的拼接。decoder输入的是下一个时刻的图谱展开,也是Tail和Relation的拼接。
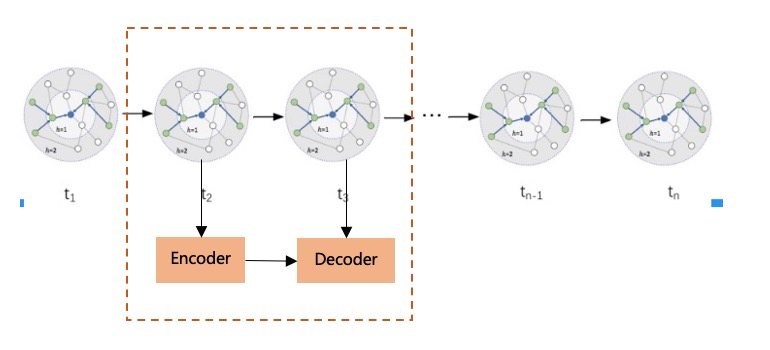
经过encoder-decoder之后,我们便可以得到相邻行为的attention weight, attention weight可以作为权重去影响图谱的边的权重输入到最后的模型中去,attention weight就显示了输入中哪些[Tail+Relation]对生成下一个行为更加重要,这样attention weight就是个性化权重。我们称之为Entity to Entity(E2E),但这里的entity包含了Entity和Relation2个部分。
▐ 自适应的生成式门控图注意力模型
模型的动机是path-based和embedding-based方法都是将知识图谱当做特征信息输入。知识图谱本身是一种语义带结构的表达,受到Facebook的《Language Modeling with Gated Convolutional Networks》的Gated CNN的启发,按照Gated CNN的做法,图谱信息不仅可以用作特征,还可以用来筛选特征,这类似于神经网络中gating机制。基于SGGA模型,我们提出了 加入KG-guided gating的自适应的生成式门控图注意力模型(Self-adaption Generative Gating Graph Attention, SGGGA)网络,网络整体架构如下。
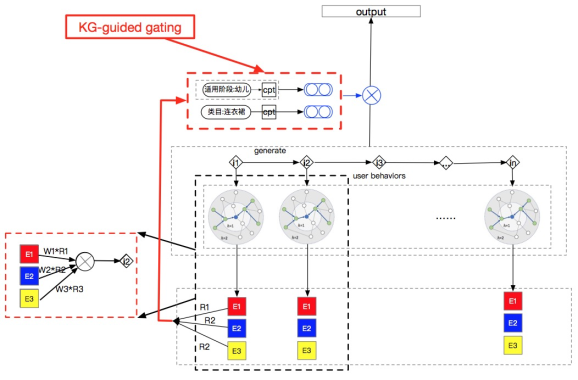
与SGGA的整体架构类似,不同的是我们每一个图谱扩展出的Relation会拿出来进行gating。
行为稀疏问题是众多推荐系统中值得研究的问题之一,基于图和图谱的模型能够一定程度上在用户和内容之间建立起更高维度的拓扑联系,在这方面本文进行了初步的探索,相关工作也在持续优化中,欢迎对这方面感兴趣的同学一起交流合作。
https://arxiv.org/abs/1905.07854 (KGAT)
https://arxiv.org/abs/1803.03467(RippleNet)
我们来自淘宝逛逛算法团队,逛逛是淘宝重要的内容化场景,团队优势有:
业务空间大、基础设施完善:场景海量反馈,在工程团队的支持下,算法工程师可以轻松上线大规模模型,分钟级更新,更加注重算法本身。
团队氛围好、研究与落地深度结合:团队不仅仅解决业务算法问题,还会紧跟学术领域进展。也欢迎有实习想法的同学加入,由资深师兄根据同学优势与兴趣定义好业务问题,辅导研究,给每位同学都有充分的成长空间。
人才需求:有机器学习、深度学习有一定理解,对内容分发和内容理解感兴趣,可以发邮件到邮箱mingyi.ff#alibaba-inc.com或者jinxin.hjx#alibaba-inc.com(发送邮件时,请把#替换成@)
大淘宝技术新春拜年
“虎虎虎”
纸质红包大派送

关注”淘系技术“回复"红包“即可获得领取方式
(2月28日18:00截止)







