SIGIR'21 快手 | 动态图神经网络如何挖掘用户兴趣的动态变化?
点击蓝字关注,提升学习效率

Sequential Recommendation with Graph Neural Networks
https://dl.acm.org/doi/pdf/10.1145/3404835.3462968


1. 背景
首先这里涉及到序列推荐的概念:序列推荐就是根据用户的历史行为来预测用户的后续交互。现存两个挑战:
-
在丰富的历史序列中,用户的 行为是隐式(点击、观看)的并且有噪声信号在里面,从而导致无法充分的反应用户的偏好。噪声:用户可能点击了该item,但是后续没有和相似的其他item发生交互,那么用户可能对该item并不感兴趣。 -
用户的偏好是 动态变化的,从历史数据中难以挖掘用户是模式。
本文提出 SeqUential Recommendation with Graph neural nEtworks (SURGE)来解决上述问题。
2. 方法
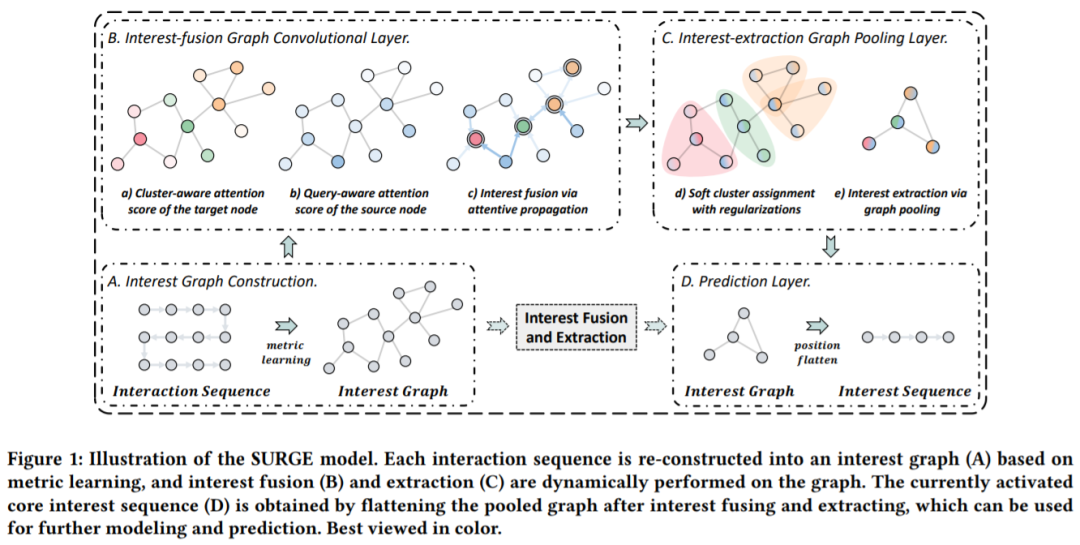
-
兴趣图构建(Interest Graph Construction):基于度量学习将松散的项目序列重新构建为紧密的项目-项目兴趣图,明确地整合和区分了长期用户行为中不同类型的偏好。 -
兴趣融合图卷积层(Interest-fusion Graph Convolutional Layer):通过在兴趣图上进行图卷积,动态融合用户兴趣,强化重要的行为,弱化噪声行为。 -
兴趣提取图池化层(Interest-extraction Graph Pooling Layer):采用动态池化的方式对用户不同时间动态变化的兴趣进行提取。 -
预测层(Predict Layer):对后续可能交互的item进行预测。
2.1 兴趣图构建
通常可以采用共现关系来构图,但是共现关系的稀疏性导致不足以为每一个用户构建图。本文结合度量学习进行构图。
2.1.1 原始图构建
为每一个交互序列构建无向图 。其中 表示边的集合, 表示邻接矩阵, 表示交互的item,item对应的embedding为 。目标是学习到邻接矩阵A反应item i与item j之间是否相关。通过该图反映用户的核心兴趣和边缘兴趣,所谓核心兴趣就是具有更高的度(degree),连接更多的相似兴趣节点。相似兴趣的频率越高,子图就越密集。如何计算相似兴趣节点,在下一节介绍。
2.1.2 相似度度量
上述构建了基本图后,需要判断哪些item之间时相似的。本文采用加权余弦相似度来度量相似关系,公式如下,其中可学习参数w和item的embedding h做哈达玛积,然后计算余弦相似度。
为了提高表达能力和稳定性,这里将上式扩展为多头度量,公式如下,就是计算多次取平均。
2.1.3 图稀疏化
之前通过计算两两item之间的相似度得到了一个n*n的矩阵 ,如果把这个矩阵作为邻接矩阵,那么这个邻接矩阵里每一个位置都有值,相当于都是邻接的,这在计算上代价高昂,并且可能引入噪声。同时图卷积无法专注于最相关的部分,因此需要对当前的图稀疏化,只提取其中最重要的关系。稀疏化的公式如下,其中 表示从M中选出第 大的值,n为矩阵大小, 控制稀疏性。简单理解就是,大于某个阈值的就都为1,表示强关系;小于某个阈值的,都为0。只保留 个强关系,从而控制了稀疏性。
2.2 兴趣融合图卷积层
2.2.1 通过图注意力卷积进行兴趣融合、
本节作者提出了聚类感知和查询感知的图注意力卷积层,在信息聚合过程中感知用户的核心兴趣(即位于聚类中心的item)和与查询兴趣相关的兴趣(即当前目标item)。查询(query)就是对应目标item。根据下式,可以通过聚合将原有的embedding h转换为新的能够反映用户兴趣偏好的embedding h'。其中 表示对齐分数,将目标节点 的重要性映射到其周围的节点 ,其具体计算方式和注意力机制类似,后面介绍。w为可学习参数,聚合函数Aggregate可以是sum,max,gru等等,本文采用sum。
和计算相似度一样,此处为了稳定性,也采用了多头的方式,如下式,计算多个权重$E_{ij}$然后进行加权。||表示拼接,即将多次计算得到的embedding拼接后得到最后的embedding。
2.2.2 聚类感知和查询感知的注意力机制
通过这个注意力机制得到的权重就是我们在上一小节中用到的权重 。这个权重用于强化重要的型号,弱化噪声信号。首先,作者假设目标节点 及其邻居 会形成一个簇(聚类),并且簇的中心是 。定义 的k阶邻居是它的感受野,这些邻居节点的embedding的均值为该簇的平均信息。为了判断 是否为中心,可以采用下式计算分数,其中 是两层前馈神经网络,激活函数为LeakyReLU。W为可学习参数,||为拼接。 为 的embedding, 表示 所在簇的平均信息,就是前面所述的均值。
其次,为了服务于下游的动态池化方法,学习用户兴趣对不同目标兴趣的独立演化,还应该考虑源节点嵌 和目标项嵌 之间的相关性。如果源节点与查询项的相关性更高,则其在对目标节点的聚合中的权重将更显着,反之亦然。由于只有相关行为才能在最终预测中发挥作用,所以我们只保留相关信息,聚合时会丢弃不相关信息。
上述两部分,第一个是聚类感知,第二个是查询感知。将这两部分结合可以得到注意力权重,即 。其中 表示节点i的邻居,包含节点i自身。α控制目标节点可以接收多少信息,β控制源节点可以发送多少信息。
2.3 兴趣提取图池化
2.3.1 通过图池化进行兴趣提取
为了得到池化图,需要先得到聚类分配矩阵,假设存在聚类分配矩阵 [1,2],那么它就可以将节点信息池化为聚类信息。其中n是节点个数,m是超参数,表示聚类的个数。我们现在已知原始图得到的embedding 和分数 ,可以得到粗化图的聚类embedding和分数,如下式,对前面小节得到的 做softmax得到 反应不同节点的重要性。通过聚类矩阵S,可以将原有的embedding转换为新的embedding。
这里的矩阵S确定了每一个节点属于哪一个聚类,不过这里采用soft聚类,即每一个节点可能隶属于不同的聚类,采用这种soft的形式可以使得整个个矩阵是可微的。正式因为这里可能会属于多个聚类,因此需要后续的正则项。这里得到S矩阵的方式如下,w为可学习参数,将输出的维度控制在m,即聚类个数。softmax归一化后用于计算分到不同聚类的概率。通过 可以得到池化图的邻接矩阵 。
可以重复计算上式,进行兴趣的分层压缩。
2.3.2 正则项
在下游的推荐任务中的梯度下降法很难训练上述矩阵S,因为这是非凸优化问题,容易陷入局部最优。并且,h'的顺序 可以反映交互的时间信息,但是聚类后得到 无法反应时间信息,因此提出了三种正则项。
2.3.2.1 Same mapping regularization
该正则项使得连接强度更大的两个节点更容易映射到统一聚类。公式如下,其中 表示 Frobenius 范数。A为邻接矩阵,反应节点之间的连接强度, 矩阵中的元素反应两个节点划分到同一个聚类中的概率。
2.3.2.2 Single affiliation regularization
该正则项明确定义每个聚类的从属关系,计算S矩阵中的每一行 的熵 来使得每一行接近one-hot向量。公式如下。最优情况为每一个节点都只映射到一个簇,这时熵为0。
2.3.2.3 Relative position regularization
为了维持聚类前后的时间序列关系,可以采用以下正则项,其中 是位置编码向量 , 也是编码向量 。最小化这个L2范数使得S矩阵中的非零元素的位置更接近对角线。
2.3.3 Graph Readout
在得到了表示用户强兴趣的紧密粗化图 之后,在原始图 上进行加权约束每一个节点的重要性,对embedding加权得到图级别的表征,公式如下,其中γ是池化之前每个节点的分数,Readout函数可以是Mean,Sum,Max等,本文采用Sum。
得到图级别的表征后,可以将其用于后续的预测层了。
2.4 Predict Layer
2.4.1 兴趣演化模型
用户的兴趣是随着时间不断变化的,因此在这里从历史行为中考虑时间信息,进行兴趣演化。此处的兴趣演化层直接采用了DIEN中的AUGRU,利用兴趣提取层中的 作为AUGRU中更新门的权重
2.4.2 Prediction
将兴趣演化层的表征,图级别表征,以及目标item的表征进行拼接后进行预测。Predict函数为两层前馈神经网络。
最后损失函数采用交叉熵损失函数+L2正则项。
3. 实验结果
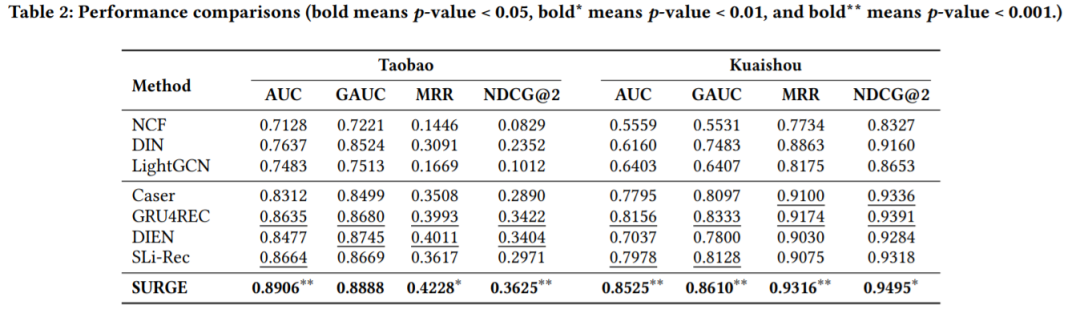
4. 总结
这篇文章的内容有点多,让我们来简单总结一下。本文主要针对兴趣挖掘和兴趣变化这两个方面的难点提出了SURGE。该模型主要包含四个方面:
-
第一部分,主要是构建后面需要用到的图,本文主要通过用户的 历史行为,来构建i tem-item的图结构,然后根据 加权余弦相似度计算item之间的相似度,并通过 阈值控制整个 图的稀疏性。 -
第二部分,通过 聚类感知和 查询感知计算得到两个权重,结合两个权重得到 注意力分数,然后对目标item的 周围邻居节点的embedding进行 加权融合,使得得到的embedding是融合了周围相似item的embedding。这可以 强化重要行为,弱化噪声。 -
第三部分,这部分进行兴趣提取,通过 池化,对用户的 兴趣进行 分层提取,并且通过 正则项加强模型的训练,同时考虑时序信息。 -
第四部分,这部分考虑 兴趣演化,即用户兴趣随时间 动态变化,采用了DIEN中的AUGRU。再结合全连接层进行预测。
关于聚类分配矩阵的文献
[1] Ekagra Ranjan, Soumya Sanyal, and Partha Talukdar. 2020. Asap: Adaptive structure aware pooling for learning hierarchical graph representations. In AAAI. 5470–5477
[2] Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, William L Hamilton, and Jure Leskovec. 2018. Hierarchical Graph Representation Learning with Differentiable Pooling. In NeurIPS

点个在看你最好看



