SIGIR20 | 基于用户行为检索的点击率预估模型

1、背景
在CTR预估场景下,用户历史行为序列对于用户未来兴趣的预测起到至关重要的作用。如何对用户历史行为序列进行有效的建模,也引起了越来越多的关注。首先简单回忆一下之前介绍过的对于历史行为序列处理的方式。最早的Youtube DNN对用户最近观看的N个视频的embedding进行avg-pooling,这种方式最主要的缺点是针对不同的target item,用户行为序列处理后得到的embedding都是相同的,对序列中的每个行为赋予相同的重要度。但用户对于target item是否喜欢,往往只与历史行为中部分行为紧密相关,因此阿里的DIN、DIEN等通过注意力机制,计算行为序列中每个item和target item的相关性作为权重,对行为序列中的Embedding进行加权。
但在实际工业界落地的过程中,由于耗时的限制,DIN等方法通常仅使用用户最近的N个行为,在一些用户行为频次较低的场景下,这种做法是OK的,但像淘宝这样的场景下,有超过20%以上的用户有1000+的历史行为,这种截断的方法往往难以有效建模用户行为中的序列模式。举个简单的例子,当前时间为夏天,用户想买一件T恤,而截断的N个行为中,都是去年冬天的购买记录,那么就容易出现夏天推荐羽绒服的bad case。
因此,如何突破耗时的限制,来利用用户更长的行为序列甚至是所有的历史行为呢?主要有两类方法,一种是基于memory的方法,如MIMN,另一种是基于检索的方法,如之前介绍的SIM。这里不再对这两篇论文进行回忆,感兴趣的同学可以翻阅相关论文或本系列之前的文章。而今天我们介绍的UBR4CTR(User Behavior Retrieval for CTR prediction) ,同样从检索的角度出发,设计了用户行为检索模块,基于每一次不同的请求和target item,从用户历史行为中抽取最有用的部分行为用于后续的点击率预估,一起来看一下。
2、UBR4CTR介绍
2.1 整体介绍
首先来看一下UBR4CTR的整体架构,如下图所示:
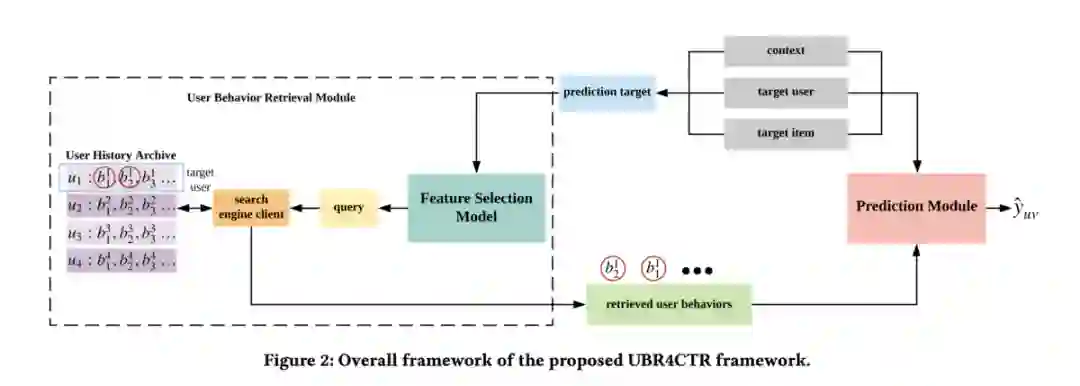
可以看到,UBR4CTR主要分为用户行为检索模块(user behavior retrieval module)和预测模块(prediction module)。用户行为检索模块又包括特征选择模块(feature selection model)、检索引擎(search engine client)和用户行为档案(user history archive)。
本文用到的符号定义如下:

接下来,对具体的细节进行介绍。
2.2 用户行为检索模块
用户行为检索模块是论文的主要创新所在。刚才也提到,用户行为检索模块又包括特征选择模块(feature selection model)、检索引擎(search engine client)和用户行为档案(user history archive)。
首先来看一下特征选择部分,特征选择的目的主要是从用户特征、target item特征以及上下文特征中,选择合适的特征来形成行为检索的query。为了更好的建模特征之间的交互关系,特征选择部分使用self-attention进行建模,其结构如下:
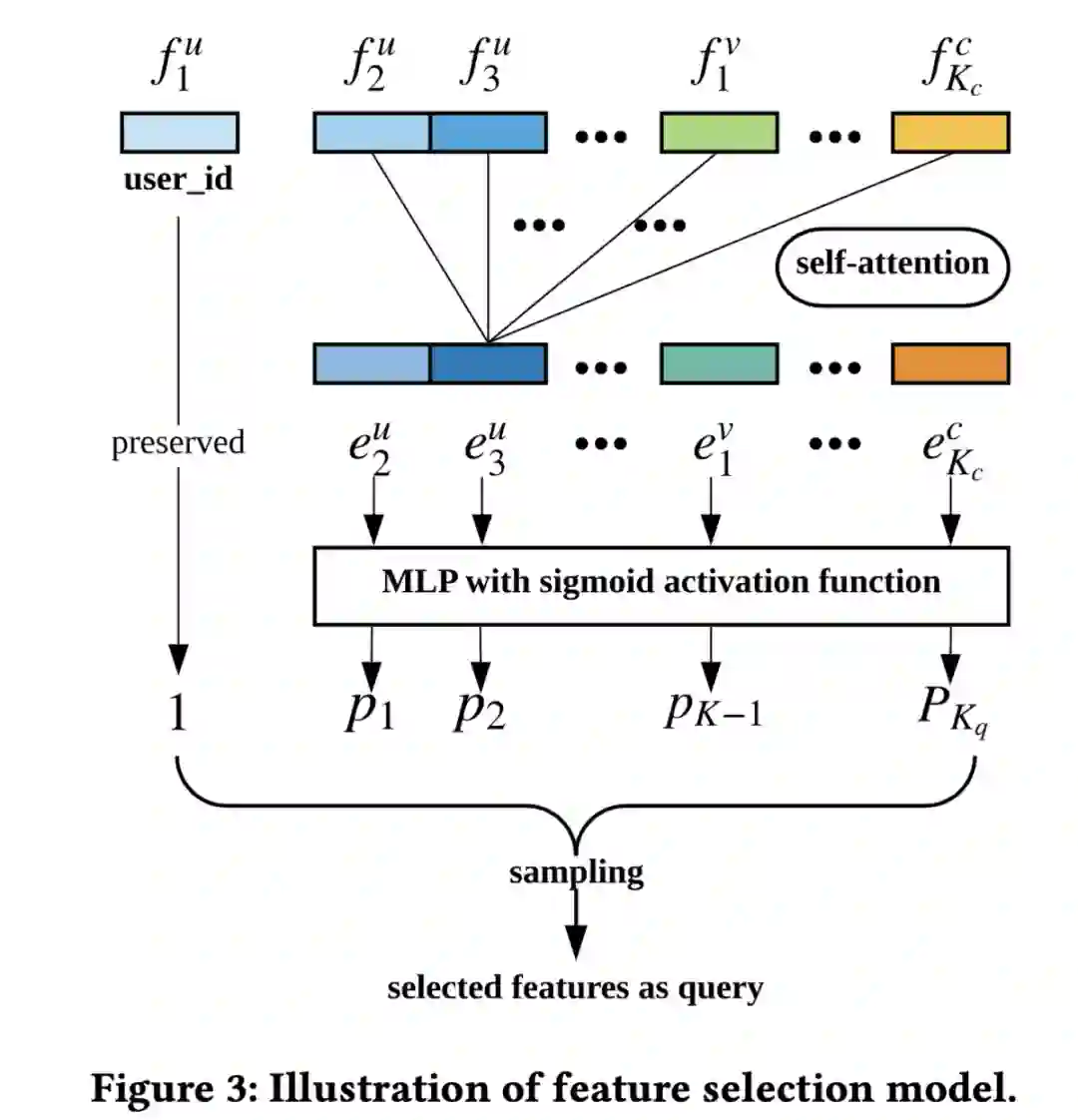
如上图所示,输入为用户特征、target item特征以及上下文特征对应的embedding表示,而用户特征中的用户id需要在后续检索引擎中使用,因此被保留,不作为self-attention的输入。self-attentiond的输出经过MLP以及sigmoid激活函数,得到Kq长度的输出(Kq表示除用户id之外剩余特征的数量),并基于sigmoid激活后的值的大小,选择最大的n个特征组成检索query。可以看到,由于特征选择是基于用户信息、上下文信息和候选物品计算的,那么在线上预测时也会动态且灵活的选择不同的特征。
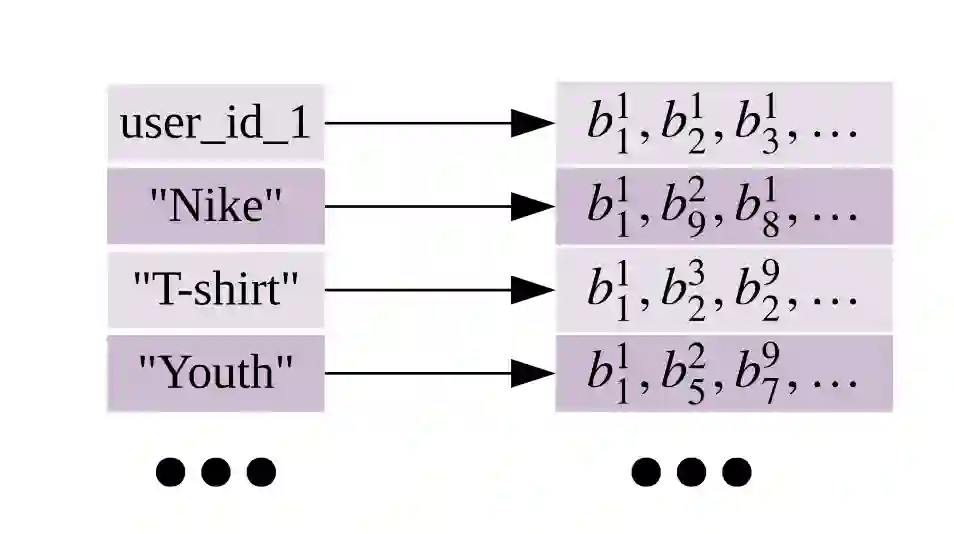
选择出n个特征构成query之后,如何检索得到S个用户行为呢?这里,首先介绍一下用户行为档案,也就是一张倒排索引表,主要包含两方面的内容,一是用户id到用户行为的映射,二是特征到用户行为的映射,如下图所示:
那么最终选择的行为序列的候选集,则是基于用户id得到的行为序列以及基于不同特征得到的序列的交集:
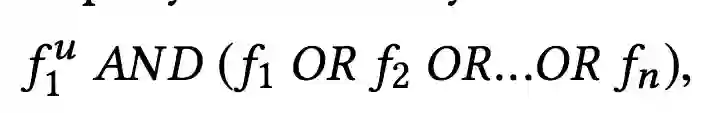
接下来的问题是,如何从候选集中选择S个最相关的行为,这里采用的是BM25算法,相似度计算公式如下:
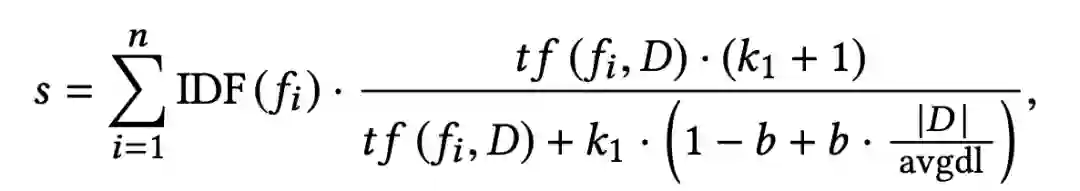
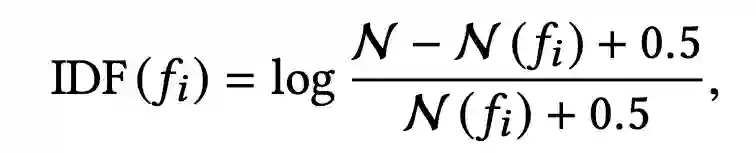
BM25算法是一种TF-IDF的升级版,大家可以参考:https://my.oschina.net/stanleysun/blog/1617727,这里不再做详细的介绍。
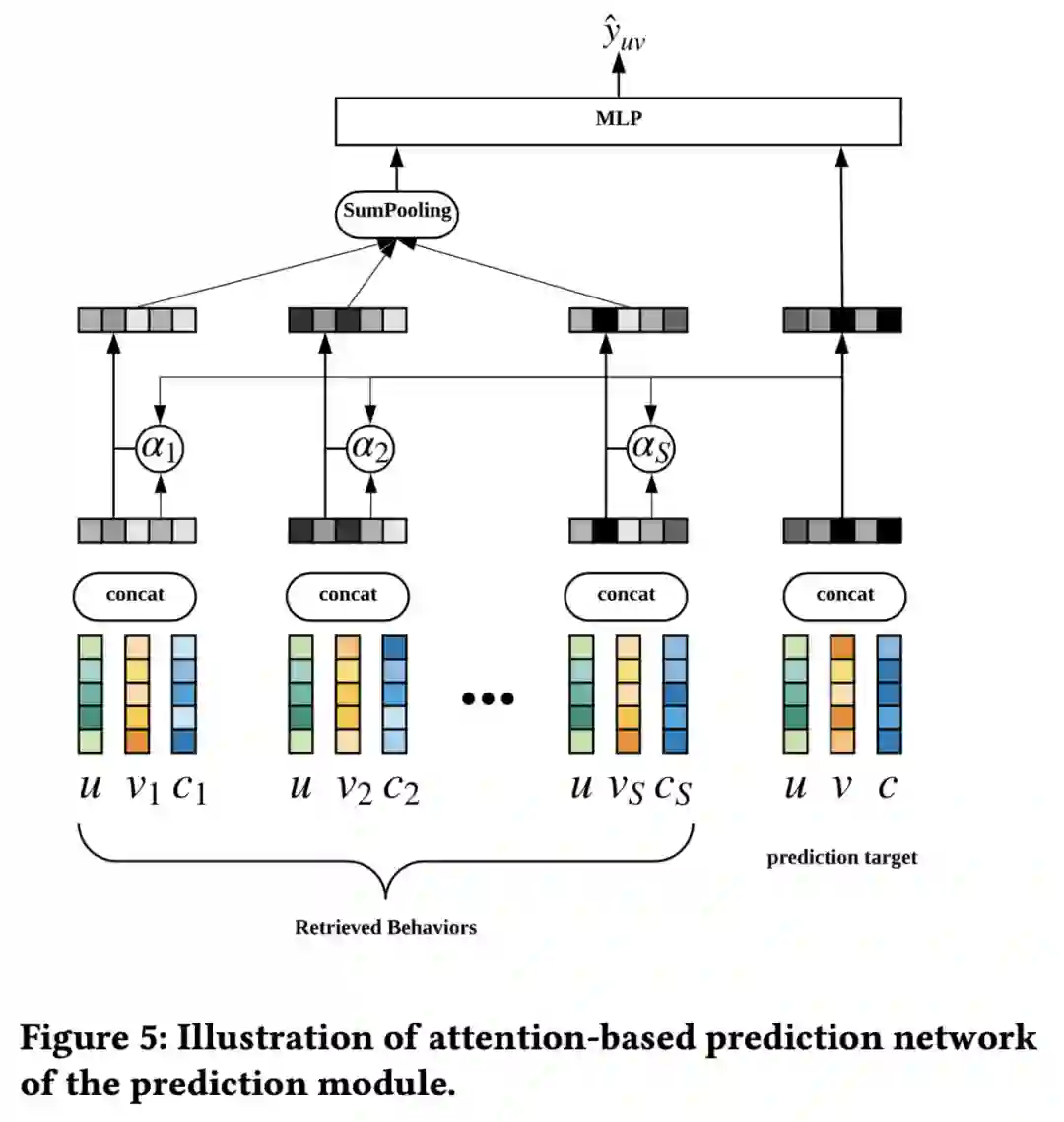
2.3 预测模块
预测模块则相对简单,结构与DIN类似,首先计算检索得到的S个行为(每个行为包含用户特征,item特征和上下文特征三部分)与target item的相似度,并基于此对embedding进行加权,随后经过MLP层得到点击率预估值,其结构如下:
2.4 模型训练
从网络结构可以看出,检索模块与预测模块是无法做到端到端训练的,论文采用了一种交替训练的方式,其过程如下所示:

具体的,对于预测模块,使用logloss和L2 loss作为损失函数,进行训练;而对于检索模块,只需要更新特征选择部分的参数,由于涉及到采样的过程,很难通过梯度下降的方式对参数进行更新,因此论文将检索模块视为一种策略,使用强化学习中策略梯度(policy gradient)的更新方式对参数进行更新。
2.5 线上部署
对于线上部署部分,在原有的CTR预测部分的基础上,增加了一个额外的检索模块。而时间复杂度也是可控的。接下来简单分析下模型的时间复杂度:
首先是特征选择(self-attention)模块,特征数量为Kq个,因此时间复杂度为O(Kq2);接下来是检索模块,N表示所有用户记录的行为的总数,F表示倒排表中特征的数量(不包含用户id),用户行为的平均长度为T,那么检索模块的时间复杂度约为O(T+Kq * N / F),其中,N / F代表每个feature对应的倒排表中的行为的平均长度,Kq代表选择的特征上限;最后是预测模块,预测模块的时间复杂度是O(C),C是attention计算的耗时,可以进行并行化处理。
3、实验结果及分析
最后来看一下实验结果,论文中进行了两组实验来验证UBR4CTR相较于base模型的效果,第一组实验中,base模型只用用户最近的20%的用户行为,第二组实验中,base模型则可以使用用户全部的历史行为,而UBR4CTR则保持抽取20%的用户行为不变,从结果可以看出,UBR4CTR相较base模型在AUC和logloss指标上有较为明显的提升:

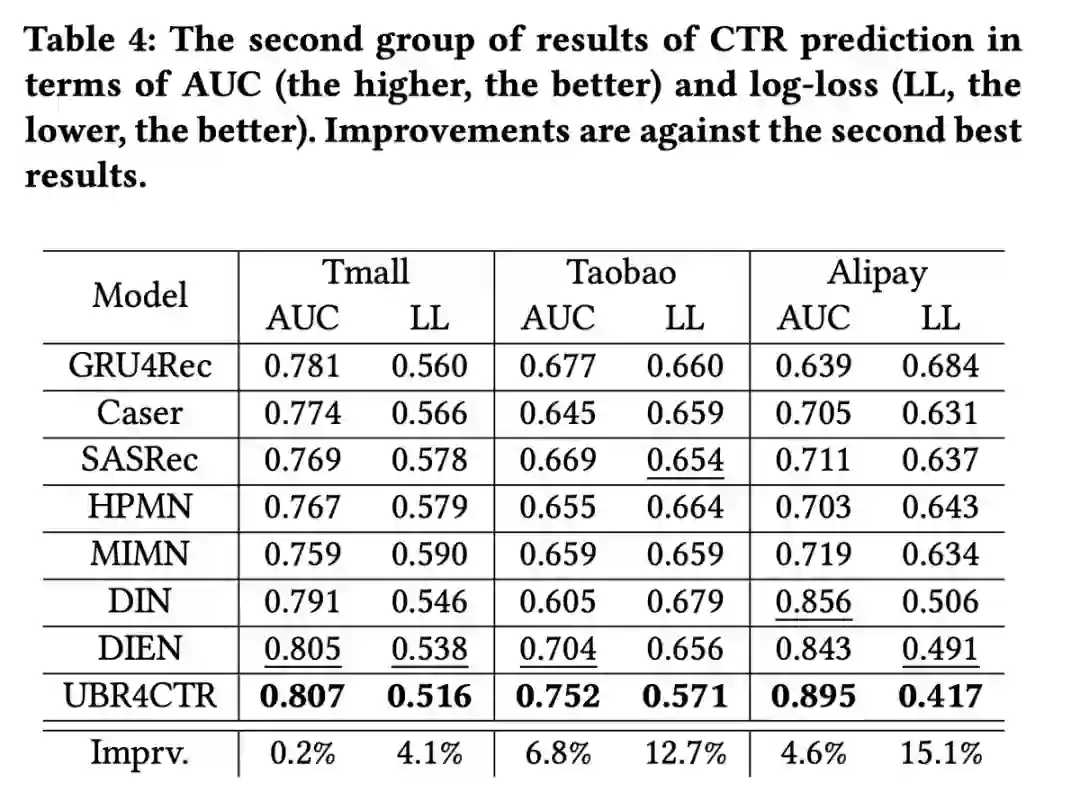
好了,本文介绍就到这里了,与SIM类似,同样采用基于检索的两阶段方案对用户所有的历史行为进行处理,不过个人感觉在行为检索方面,UBR4CTR具有更高灵活性,但时间复杂度也相对更高。不过两种方式都是两阶段的方式,这种方式最大的缺点在于两个阶段的目标是存在一定差异的,检索阶段更多的是寻找与target item最相似的历史行为,而非更准确的点击率预估。因此,在后续的文章中,咱们会介绍端到端的处理方法,保持关注哟~。


