CCCF专栏 | 面向领域定制的神经网络结构设计
如果我们将神经网络应用到某个领域的同时加入相关的领域知识,针对该特定应用领域设计算法来理解网络,便能大大提高神经网络的可解释性。

人工神经网络(Artificial Neural Network, ANN)简称神经网络(NN),是基于生物学中神经网络的基本原理,提出的一种模拟人脑的神经系统处理复杂信息的数学模型。该网络模型是深度学习的代表模型,衍生了一系列人工智能技术,影响并改变着人们的日常生活方式。例如,车站检票时的人脸识别技术,菜单拍照翻译的文本识别技术和机器翻译技术,嘈杂环境下的语音增强技术,等等。人工神经网络具有独特的知识表示方式及自学习和自适应能力,可以通过预先提供的一批相互对应的输入输出数据,分析两者的内在关系和规律,最终根据这些规律形成一个复杂的非线性系统函数,这种学习分析过程称为“训练”。“训练”完成后的网络模型具有不错的泛化功能和很强的容错能力,在多项任务上都能收获比传统方法优越的性能提升,从而引起各学科领域的关注。
神经网络大受追捧的一个重要因素是,如今有大量可使用的数据,这些数据从过去几年,甚至几十年前累计至今,使得神经网络能够真正发挥其潜力。这正是神经网络最突出的优点,因为神经网络获得的数据越多,其表现越好。另一个因素在于逐渐增强的计算能力。神经网络的可并行计算特性以及计算硬件的更新换代,使得神经网络能越来越高效地使用更多的数据。由于神经网络大受追捧,研究者也相应的增多,算法开发方面的突破也大幅提升了神经网络的性能。然而,神经网络不具备很好的可解释性,即具有“黑匣子”性质,这意味着你不清楚神经网络是如何完成你交付给它的任务的。神经网络的预测一旦发生了错误,问题就变得没有办法解释,也因而无法得到更深的推广和应用。
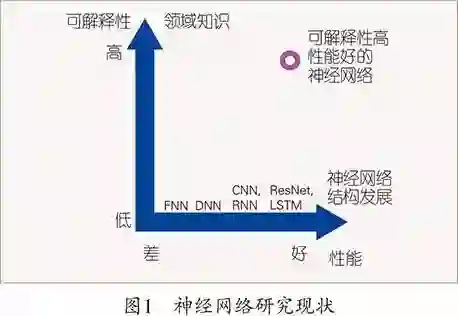
图1阐述了神经网络相关领域的研究现状,横向来看,由于技术的进步和研究者的增加,神经网络的结构框架正在逐步得到更新和扩展,模型的复杂度越来越高。随着神经网络结构框架的更新,模型的基本能力得到增强,在各个任务上的性能也都能获得提升。然而,现在的模型可解释性不足,很多时候都无法理解为什么网络更新后性能就能获得提升。将图1纵向来看,如果我们将神经网络应用到某个领域的同时加入相关的领域知识,针对该特定应用领域设计算法来理解网络,便能大大提高神经网络的可解释性。例如在汉字识别中,通过分析汉字的本质特性,即每个汉字都是由相应的偏旁部首组成,不仅能更好地提升模型性能,增强模型的可解释性,还能克服神经网络对数据的依赖性,使得神经网络具备少量样本学习甚至零样本学习的能力,更符合人类的学习方式。再比如语音信号处理,通过分析语音信号的本质特性,例如谐波特性、包络特性等,设计的语音处理网络也能收获更好的性能并增强可解释性。所以,正如图1右上角红色圆圈所示,只有当领域知识和神经网络相结合,设计出面向领域定制的神经网络时,才能在获得高性能的同时具有更好的可解释性。
面向汉字识别的神经网络结构设计
随着互联网的飞速发展,图片成为信息传播的重要媒介,图片中的文本识别也一度成为学术界和工业界的研究热点,应用在诸如证件照识别、信息采集、书籍电子化等领域。随着手写板和智能手机的推广,手写输入也逐渐成为了一种比键盘打字更自然的输入方式。而这些趋势无疑对汉字识别提出了更高的需求。汉字识别一直以来都是一个很具挑战性的难题,原因在于自然场景照片下的背景噪声,手写输入的模糊性,汉字内部复杂的空间结构,相似汉字的易混淆性,庞大的汉字集合以及越来越多的网络新生汉字。
不少研究已经成功地将卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)等直接作用于4000多类常用汉字的识别。这些方法大多数仍是将汉字看成一个图片或者序列轨迹信号来处理,尽管有不错的识别效果,但神经网络依然是被当成了一个黑匣子。汉字的类别数远远不止4000多个,考虑到全部简体字、非简体字和古文字,汉字的类别数甚至能达到10万。如果要训练一个通用的神经网络分类器来识别如此庞大的汉字集合,则该神经网络参数会很多,代价很大。除去4000多个常用汉字外,剩下的汉字都很少使用(低频汉字),收集这些低频汉字的样本非常困难。由于网络文化的传播,越来越多的网络新生汉字被创造出来,因为它们之前从未被使用过,神经网络并没有它们的训练样本,识别这些新生汉字则更加困难。在这种情况下,神经网络的弊端也就显现出来了——缺少训练数据。
要想更好地解决汉字识别问题,就不能继续将神经网络当成黑盒子,而要充分利用汉字的本质特性,使神经网络的识别过程具备可解释性。文献[1]首次提出基于偏旁部首的汉字识别神经网络(Radical Analysis Network, RAN),充分利用了汉字的特性,见图2。汉字是由偏旁部首通过特有的空间结构构成的。仅用很少的偏旁部首集便能构造出大量的汉字,如约500个偏旁部首便能成功构造出超过25000个汉字。汉字类别很多,拆解成更精简的偏旁部首后,汉字类别数量将大大压缩,去除冗余性。因此,可以很自然地联想到将汉字字符拆解成由偏旁部首构成的层级结构,先识别这种层级结构,再一一对应特定的汉字类别来识别汉字。以“殿”字为例,这个字是左右结构,先是“”字旁和“八”字旁形成上下结构,“尸”字旁左上包围这一上下结构。右边由“几”和“又”上下组成。可以通过深度优先遍历的方式,将层级的树形结构遍历成字符串的形式,再通过识别字符串来识别汉字。有一个预先定义好的结构对应汉字类别的字典。将汉字的结构识别出来之后,在字典里就能索引出结构类别,进而进行汉字识别。这种定制的汉字识别网络具备识别低频汉字的能力,在训练集里没有出现过的词,无须额外收集数据,也不需要重新训练模型。例如,之前很火爆的duang字,上“成”下“龙”形成上下结构。虽然这个字很简单,但是因为训练集中没有,普通的模型无法识别,很有可能将其识别成“成”“龙”或其他字。RAN模型可以在集外字场景下将其识别出来,以duang字作为输入,解出“成”和“龙”,同时出现一个表示“成”和“龙”上下结构的序列。

RAN的实际组成部分是一个编码器和一个解码器。编码器负责从原始输入中提取有效特征。我们将神经网络看成一个特征提取器,其内部的高维非线性函数使得其具备丰富的表达能力,所提取的特征也比一般人为设计的特征更好。解码器负责生成汉字被拆解后的偏旁部首序列,它是一个前向循环神经网络,在解码每一个输出字符时都与前一时刻解出的字符有关联。对于汉字内部偏旁部首的切分对齐,我们采用一个注意力机制来解决。该注意力机制能够使解码器仅关注到独立的偏旁部首,从而正确地将各个偏旁部首区分开来。对于汉字内部复杂的空间结构,RAN同样选择注意力机制来解决。此注意力机制能够检测出各偏旁部首之间的空间关系,对于左右结构、上下结构,都能很好地注意到两个偏旁部首中间的空白部分。这种针对汉字结构识别问题设计出来的注意力机制使得RAN的可解释性得到提高。当一个汉字被错误识别时,我们可以通过注意力机制来观察具体是哪一个偏旁部首被识别错误,或是哪一个空间结构被检测错误。此外,我们还可以将RAN解析汉字的过程步骤可视化,从而理解网络的学习过程。
RAN的优势能有效地提高汉字识别的准确率,尤其是对低频汉字的识别。该方法不仅在手写场景中效果显著[2],在自然场景下的文本识别也具备很好的鲁棒性,因此在国际模式识别大会(InternationalConference on Pattern Recognition, ICPR)上举办的自然场景下的中文文本行识别竞赛[3]中夺得桂冠。
面向语音增强的神经网络结构设计
2014 年,基于回归深度神经网络(Deep Neural Networks, DNN)的语音增强被首次提出,并在实验中证明了该算法可以取得优于传统语音增强算法的性能。虽然基于深度学习的语音增强算法在训练数据准备阶段使用了很多噪声类型和训练语料,但是其在真实数据上的推广能力还存在诸多问题,比如在低信噪比下的语音失真、处理不匹配噪声类型和不匹配说话风格时的效果不稳定等。
语音增强的目的是从语音和噪声的混合信号中提取出语音的成分。基于深度学习的语音增强算法,可以通过训练深度神经网络来完成这一估计问题,如图3左侧所示。在网络的训练过程中,神经网络以带噪语音(noisy speech)的特征为输入,以干净语音(clean speech)的特征为目标,通过有监督训练的方式来学习输入和目标的映射关系,我们称之为直接映射(direct mapping)。然而,当语音淹没在噪声当中,语音特有的频谱结构信息不再清晰时,低信噪比的带噪语音到干净语音的映射学习难度就会很大。在测试阶段,通过直接映射的网络学习方式训练得到的语音增强模型在低信噪比时效果通常不好[4]。现有的语音增强网络训练方式可以看作是“黑箱子”式训练,给定一个输入和一个目标,内部如何解题完全依靠网络自身去学习。当任务难度很大时,“黑箱子”式的网络训练则有一定的局限。
针对训练难题,文献[4, 5]提出渐进式语音增强(SNR-based progressive learning),如图3右侧所示。其基本思想是从“小”开始,先学习容易的任务或子任务,然后逐渐增加学习难度。具体到语音增强任务,带噪语音到干净语音的映射按照信噪比(SNR)递增的方式被分解为多个子问题,每一个子问题被定义为提升输入语音的信噪比(SNR gain)。前一个问题的输出视为下一个问题的输入,每一步问题的求解都会使得下一步的难度降低。渐进式学习可以使得网络内部功能明确而有序,逐层递进,直达最终学习目标。以输入带噪语音的信噪比是0dB为例,对于直接映射来说,其学习目标是对应的干净语音;对于渐进式语音增强来说,除了干净语音是最终的学习目标之外,还存在多个中间目标,这些中间目标是信噪比更高的带噪语音,如10dB、20dB等。

渐进式学习的语音增强网络是一个针对语音增强任务定制的神经网络模型。网络的目标层使用线性激活函数,隐层是非线性激活函数(隐层可以是DNN层、LSTM1层等)。所有的目标层被要求去学习比输入具有更高信噪比的中间目标(从目标1到目标K-1)和最终的干净语音(目标K),网络中对每一个中间目标的估计都是有具体物理意义的,代表对更高信噪比语音的估计。在对中间目标的学习中,原始输入以及对目标1到目标K-1的估计被拼接在一起送入到子网络K中,使得该子网络可以同时看到原始的带噪语音的特征和对不同信噪比语音的特征估计。多信息的同时输入能够解决渐进式网络传递过程中原始输入信息的损失问题,还可以让网络面对复杂测试环境时更加鲁棒。
这种定制的基于渐进式学习的语音增强算法框架可以提高语音增强模型在复杂环境下的推广能力。在语音增强实验中,渐进式学习可以有效提高低信噪比下的语音增强客观指标,尤其是语音可懂度。在低信噪比和高信噪比情况下,对于多种噪声类型,都有很好的语音增强表现。在鲁棒性语音识别的研究工作中,我们发现基于深度学习的语音信号预处理技术可以轻松地在干净语音训练的声学模型上带来识别率的有效提升,但在实际应用的基于混合数据训练的声学模型上却很难带来识别率的提升。而渐进式语音增强对信噪比的逐步提升不仅可以减少语音失真,使得语音识别效果有所改善,其内部生成的多个目标估计更是对基于混合数据训练的语音识别效果有着显著的提升作用。
基于渐进式学习的语音增强系统可以大大提升系统在实际应用数据上的推广能力,基于该方法的参赛系统也因此在CHiME-52语音识别比赛中[6]中夺得桂冠。
通过以上两个回归(语音增强)和分类(文字识别)的例子,我们可以看出除了使用越来越复杂的通用神经网络结构(比如能达到1000多层的ResNet)来获取性能的提升,另一种思路是采用面向领域定制的神经网络结构。通过充分挖掘应用领域的知识来设计神经网络结构,不仅可以大幅提升性能,还使得网络具有更强的可解释性、更紧致的设计以及更快的解码速度,甚至还能具有更好的小样本和零样本学习能力。
作者介绍
杜 俊

•CCF专业会员。
•中国科学技术大学副教授。
•主要研究方向为语音信号处理、模式识别应用。

张建树

•中国科学技术大学博士生。
•主要研究方向为深度学习、文本处理。
高 天

•中国科学技术大学博士生,科大讯飞研究院研究员。
•主要研究方向为语音信号处理、深度学习。
脚注
1 麦LSTM:Long Short-Term Memory,长短期记忆网络。
2 第五届国际多通道语音分离和识别大赛(Computational Hearing in Multisource Environments),是国际语音识别评测中的高难度比赛,始办于2011年。
中国计算机学会

长按识别二维码关注我们
CCF推荐
【精品文章】
点击“阅读原文”,加入CCF。




