学界 | 微软研究员提出多束深度吸引子网络,解决语音识别「鸡尾酒会问题」
或许这也是一种方法论:当针对一个问题有多种方法时,不妨将它们综合起来,或能取各家之长,补各家之短。
本文所要介绍的工作正是采用了这种思路,在语音识别的鸡尾酒会问题上取得了较大的突破。
AI 科技评论按:近日来自 Microsoft AI and Research 的研究员在 arXiv 上贴出一篇论文《Cracking the cocktail party problem by multi-beam deep attractor network》,即利用多束深度吸引子网络解决鸡尾酒派对问题。

所谓「鸡尾酒会问题」是指人的一种听力选择能力,在这种情况下,注意力集中在某一个人的谈话之中而忽略背景中其他的对话或噪音。做一个类比,鸡尾酒会现象就是图形-背景现象的听觉版本。这里的「图形」是我们所注意或引起我们注意的声音,「背景」是其他的声音。

具体来说,鸡尾酒会问题的任务就是在高度重叠的音频中将不同说话者的内容分离和识别出来。我们人类可以很容易完成这项任务,但是要想建立一个有效的系统来模拟这个过程还是挺困难的。事实上这也是语音信号处理中最为困难的挑战之一,对它已经超过 60 年的研究,但由于混合源的变化很大,所以即使现在鸡尾酒会问题仍未解决。
在「深度学习时代」之前,有一些学者在这个任务上也做了一些尝试。事实上,鸡尾酒会问题可以分成两类:单通道系统和多通道系统,两者的区别就在于前者只有一个麦克风,而后者后多个。在单通道系统中,分离过程完全依赖于语音的频谱属性(例如音调的连续性、谐波结构、常见的声母等),这可以通过统计模型、基于规则的模型或者基于分解的模型。在多通道系统中,分离过程可以利用声源的空间属性。但是不管使用多少麦克风,大多数现有的系统只能用于相当简单的情况,例如固定扬声器、有限词汇表、不同性别的混合等,在一般的情况中则不能产生满意的性能。
随着深度学习的爆发,鸡尾酒会问题也有了较大的进步。不过与大多数其他深度学习任务不同的的是,多人说话的分离有两个独特的问题:置换问题和输出维度问题。
置换问题:大多数深度学习算法要求评估目标是固定的,而在多人讲话分离任务重,分离源的任意置换是等价的。
输出维度问题:指混合说话的人数在不同样本中是不同的,这就造成了学习的困难,因为神经网络通常要求其输出层具有固定的维度。
目前有三种单通道神经网络模型,即深聚类(Deep Clustering)、深吸引子网络(Deep Attractor Network)、置换不变训练(Permutation Invariant Training)。在深聚类和深吸引子网络中,会将混合频谱中每个时频段映射到更高维度表示中,也即所谓的嵌入,这两种模型能够有效的解决上述两个问题。而置换不变训练模型则通过掩码学习框架(Mask Learning Framework),其中网络受限为每个目标说话者生成输出掩码,然后彻底搜索输出与干净的参考音源之间的组合来解决置换问题。这三种算法在很大程度上提高了语音分离领域的水平。对他们的评估结果显示,它们在普通数据集的两音源和三音源分离问题上具有相似的表现。
尽管以上基于深度学习的方法在鸡尾酒会问题中取得了很大的突破,但是它们离应用于真实世界的应用程序中还存在很大困难。这主要有两个原因:
首先,它们的分离能力有限。例如当有四个讲话者时(即使是最简单的两个男性和两个女性的分离任务),由于声音混合较为复杂,每个讲话者的声音大部分都会被其他讲话者的声音掩盖住,上面提到的几种单声道模型几乎无法完成这样的任务。
其次,目前的单声道系统通常容易受到混响的影响,这主要是因为混响会模糊掉单通道分离系统用来分离讲话者的语音频谱线索。
在多通道方法中,目前也有几种基于神经网络的模型,例如声学模型(Acoustic Modeling)和语音增强(Speech Enhancement)。但是现有的系统都还没有解决鸡尾酒会问题。例如在语音增强模型中,每个通道都需要一个预先学习的掩码,这在当前是不适用的,因为还没有一个系统能够自动获取掩码。而在声学建模中,则需要多个汇集步骤,这不适用于多方讲话者的场景。作者表示,就他们所知目前还没有一种系统能够处理复杂的多方讲话者语音分离问题。
为了消除以上这些模型性能上的限制,将单通道和多通道方法进行结合是一个很自然选择方向,因为这两种方法使用了不同的信息进行分离,因此会起到相互补充的作用。
在作者所发表的这份工作中,他们提出了一种新颖、有效且简单的多通道语音分离和识别系统。这个系统由多声道部分和多声道部分组成。

模型架构
多通道处理 由 12 个固定束(beam)的差分波束形成器组成,它们在空间中进行等价的采样;然后进行单通道处理,这通过锚定深度吸引子网络(Anchored Deep Attractor Network)来实现,其中每个通道都会学习比率掩码(Ratio Mask)。
通过结合多声道处理和单声道处理,这种系统可以充分利用空间和频谱信息,并且能够克服大多数多声道系统只能在封闭环境中运行的限制,从而使性能优于单通道和多通道系统。该系统利用 beam 作为神经网络输入,这可以消除神经网络的复杂域处理,并且将空间处理和频谱处理单独处理,这可以使系统独立于麦克风的位置分布。由于引入吸引子网络结构,作者所提出的这个系统能够执行端到端的优化过程,并且可以扩展到任意数目的音源,而不会有置换或者输出维度的问题。
先来个直观的感受:
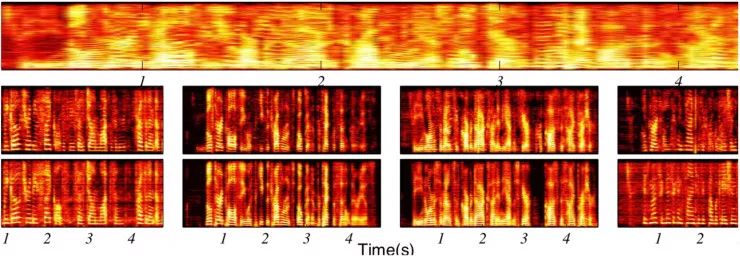
在这个例子中,上面是原始混合频谱,中间为根据模型分离并重构出四个说话者的音频频谱,最下面则为原始无混合的参考音频频谱。可以看出基本上一致。在所有测试数据上都有类似的表现。再来看一下具体情况——
语音分离

这个表格中绿色背景的为对比模型,数据单位为dB,越大越好。其中:
MBBF——multi-beam beamformer,
OGEV——oracle generalized eigenvalueOMVDR——oracle minimum variance distortionless response
IRM——ideal-ratio-mask
DAN——deep attractor network
而 MBDAN、OMBDAN、MBIRM 则分别是依照作者所提出的系统对上面模型进行的改造。可以看出,这三种模型的表现远远优于其他模型。当然从这个表中其实还可以看出蛮多信息的。
首先,我们可以看到,无论是在封闭环境还是开放环境,这三个模型在性能上并没有太大变化。这说明这些模型可以在现实世界的场景中使用。
其次,与其他波束形成算法(例如 MBBF、OGEV)相比,性能上有 40% 以上的提升,并取得了与 OMVDR 类似的性能,但 OMVDR 模型的缺点是要求必须具有确切的位置信息。
再次,MBBF 和 MBDAN 的对比可以看出,多通道模型与单通道模型的结合能够产生互利的结果。
最后,当与单通道的模型比较式,我们可以看到有明显的优势。这也是由于结合多通道后弥补了单通道模型混响问题。
语音识别
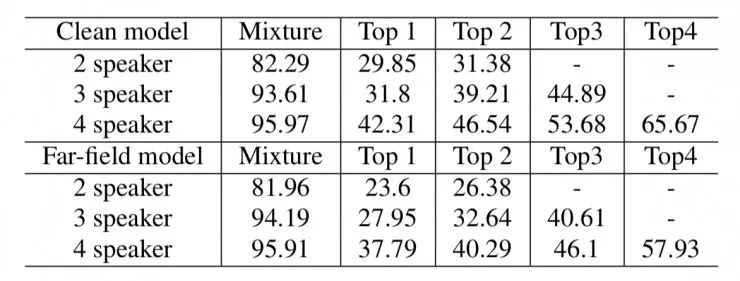
上表中显示了用 OMBDAN 模型分离出语音后再做识别的性能,分别有 clean model 和 Far-field model 两种。可以看出表中六种条件的混合语音的 WER(word error rate)都接近 100%。但是经过处理后,WER 在所有条件下均大幅下降。与净化模型相比,相对净增量分别为 62.80%,58.73%,45.59%,远场模型分别为 69.51%,64.19%,52.53%。由于混响和平稳噪声包含在训练数据中,远场模型取得了更好的性能。
最近神经网络的使用对单通道语音分离方法(或者更广义地说,鸡尾酒会问题)的性能有了显著的提升,不过在多通道问题中的性能仍然不能让人满意。在这项工作中,我们提出了一种新的多通道框架来进行多通道的分离。在所提出的模型中,我们首先将输入的多声道混合信号转换为使用固定波束模式的一组波束形成信号。对于这种波束形成,我们建议使用差分波束形成器,因为它们更适合于语音分离。然后,每个波束形成的信号被送到单通道锚定深度吸引子网络中来生成分离的信号。通过悬着每个光束的分离输出来获得最终的分离结果。
为了评估所提出的这个系统,我们创建了一个具有挑战性的数据集,其中包含 2、3、4 个说话者的混合。我们的结果表明,所提出的系统在很大程度上改善了语音分离领域的现状,对于 4、3、2 个说话者的混合,实现了 11.5dB、11.76dB、11.02dB 的平均信号与失真比的改善,其性能与使用 oracle 位置、源和噪声信息等信息的模型相近或更好。我们还使用干净的训练好的声学模型对分离后的语音进行语音识别,在 4、3、2 个说话者完全重叠的语音上分别实现将相对词错误率(WER)降低 45.76%、59.40%、62.80%。使用远场讲话声学模型,WER 会进一步降低。
论文地址:
https://arxiv.org/abs/1803.10924
对了,我们招人了,了解一下?

限时拼团---计算机视觉基础班
从算法到实战应用,限时拼团,最后一周
已有 100+人参加了此拼团,最高每人优惠 200 元!
点击阅读原文或扫码立即参团~

┏(^0^)┛欢迎分享,明天见!



