CVPR2019 | CMU和UC伯克利开源:无监督跟踪和光流新方法
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Xiaolong Wang(论文一作)
https://zhuanlan.zhihu.com/p/62026270
本文已授权,未经允许,不得二次转载
这篇文章主要是为了推广下我们CVPR 2019 (Oral) 的工作:

Xiaolong Wang*, Allan Jabri* and Alexei A. Efros. Learning Correspondence from the Cycle-consistency of Time.
Paper: Learning Correspondence from the Cycle-Consistency of Time
Code: https://github.com/xiaolonw/TimeCycle
Slides (google drive): drive.google.com/file/d
Slides (百度网盘): https://pan.baidu.com/share/init?surl=prNthUokiqRPELs8J4O-vQ
提取码: es86
我们这个工作主要是给tracking和optical flow提供一种新的思路。我们把两者联系并且统一起来称为correspondence in time。而这个工作的目标就是训练一个神经网络,使得它能帮助我们获得在video中帧与帧之间的semi-dense correspondence。
和以往的方法不一样,我们不需要人为的数据标注也不需要synthetic data进行训练。这个工作采用的是无监督学习(self-supervised / unsupervised learning),而且训练网络的方法能被应用到任意的video上面。
首先show一下结果,我们训练出来的网络可以用来做以下的human part segment tracking (没有经过任何用segmentation training 和 fine-tuning)。

Video Segmentation Tracking
在介绍我们的方法之前,先讨论一下目前找correspondence的方法:
Related Work 1: Visual Tracking
Visual Tracking 能够获得box-level correspondence。但是目前训练神经网络做tracking需要标注视频的每一帧进行训练,这样大大限制了训练样本的数量。

Related Work 2: Optical Flow Estimation
Optical Flow Estimation 能够获得pixel-level correspondence。但通常训练神经网络计算optical flow通常需要在synthetic dataset上进行,使得训练出来的网络很难泛化到真实数据中(generalization to real data)。而且optical flow对于局部的变化过于敏感,很难处理长距离或者large motion的视频。

其实Visual Tracking 和 Optical Flow Estimation 之间非常相关,但是似乎在近年来深度学习之后这两个领域变得互相独立。我们这篇文章希望让大家能把两者联系起来思考。
Our Approach
我们这里提出的其实是介于tracking与optical flow的中间的mid-level correspondence或者说是semi-dense correspondence。正因为我们是在mid-level上算correspondence,这使得我们对pixel上的局部变化变得更加robust,能在一定程度上encode invariance,从而让我们可以做long-range tracking 和处理large object displacement。
我们在deep feature上计算semi-dense correspondence。如下图,对于相邻两帧,我们首先抽取deep feature (大概30x30 resolution)。对于在t-1帧的一个格子,我们通过算nearest neighbor找到在t帧最相似的格子。下图箭头两端代表了其中一个correspondence。
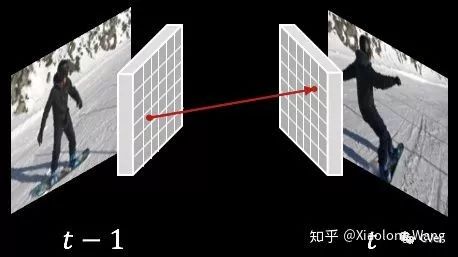
以下是我们训练这个deep network的方法,这里采用的是无监督学习(self-supervised/unsupervised learning):既是学习过程中不需要任何的人为的标注。
如下图所示,假设我们用这个network进行tracking。在最后一帧上,我们首先随机选一个起bounding box,然后对这个bounding box进行backward tracking(蓝色箭头),接着对在第一帧的结果进行forward tracking(红色箭头)。那么initial box和最后的tracking box之间的error(黄色箭头)就会作为我们训练network的supervisory signal。我们把这个signal称为Cycle-Consistency Loss。
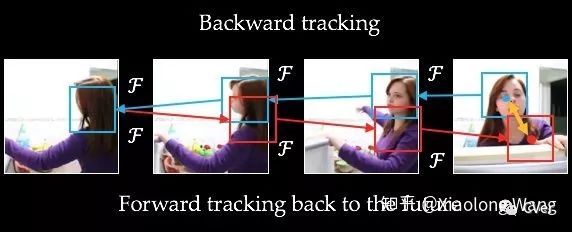
在训练的过程中,我们把error沿着cycle来传递(图中用黄色虚线表达):

在训练过程的不同迭代次数中,cycle产生如下图的变化。可以看见随着迭代次数的变化,tracking也逐渐变得越来越好:
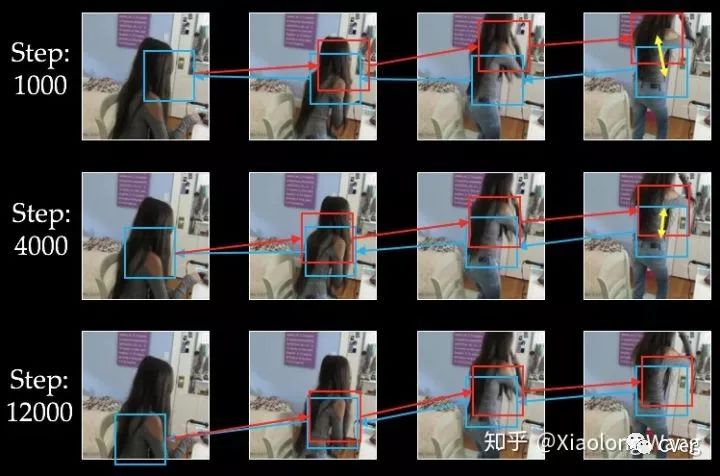
Our Result
我们训练出来的网络能够帮助我们找correspondence,并应用在各种的Tracking Tasks。我们在VLOG 数据集(github.com/xiaolonw/Tim) 上面进行unsupervised learning。在训练之后的网络我们可以直接应用在以下不同的tracking tasks,不需要在目标数据集上做任何的training/fine-tuning。
除了开篇提到的human part segments tracking,我们还可以完成以下tasks:
1. Tracking Object Mask


2. Tracking Pose

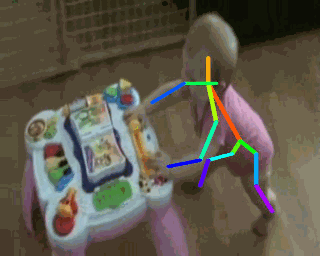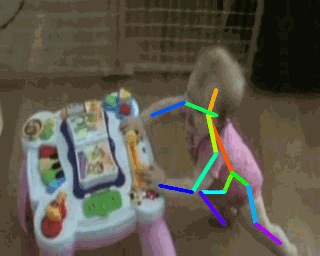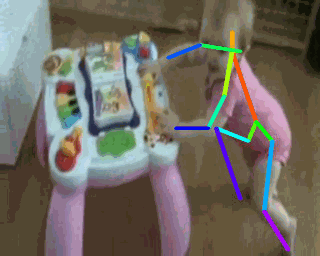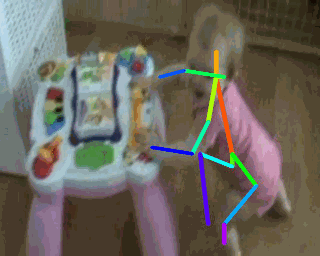
3. Tracking Texture
在这个task里面,我在第一帧画了一个彩虹texture,然后用我们的correspondence可以把彩虹texture一直传递下去。
4. Optical Flow
我们还能将correspondence visualize出来,结果和optical flow类似。

Conclusion
我们希望这个工作能将tracking和optical flow联系起来。针对tracking tasks, 我们能突破有限的human annotation的限制,提供一种新的训练tracker的思路。我们还希望能够提供一种新的video里面,或者有时序关系的数据中的无监督学习的方法。在未来可以用这种cycle-consistency in time来作为一种supervisory signal帮助其他任务。
---End---
CVer目标跟踪交流群
扫码添加CVer助手,可申请加入CVer-目标跟踪交流群。一定要备注:目标跟踪+地点+学校/公司+昵称(如目标跟踪+上海+上交+卡卡)

▲长按加群
这么硬的分享,麻烦给我一个在看

▲长按关注我们
麻烦给我一个在看!


