非线性优化方法的总结——approximation
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:邓康康
链接:https://zhuanlan.zhihu.com/p/85423364
本文已由作者授权转载,未经允许,不得二次转载
一、Deterministic Methods
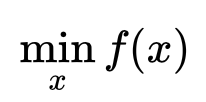
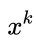 ,梯度方法通过在该点做一个泰勒展开得到一个局部逼近的二次函数,然后求解该二次函数得到
,梯度方法通过在该点做一个泰勒展开得到一个局部逼近的二次函数,然后求解该二次函数得到
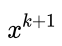
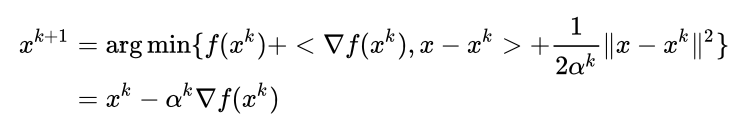
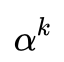 为步长,步长的选择有很多种,比如最速下降法这样选择步长
为步长,步长的选择有很多种,比如最速下降法这样选择步长
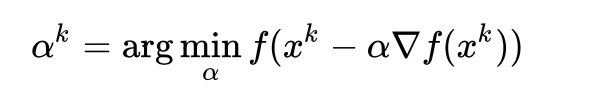
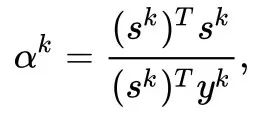
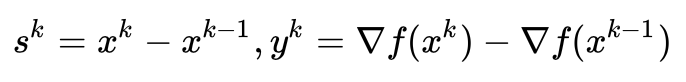
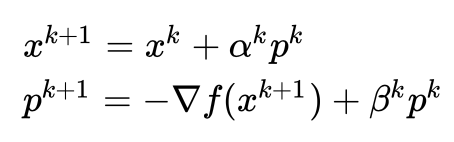
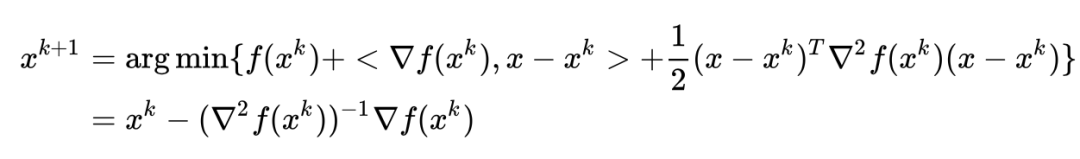
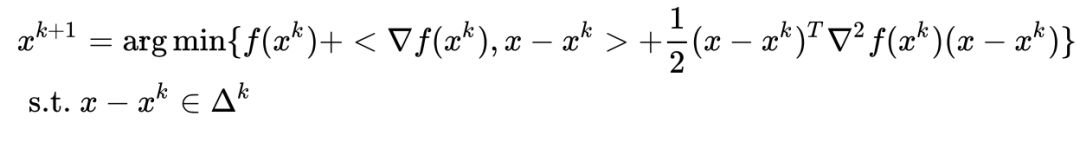
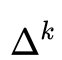 为信赖域半径,如果泰勒展开逼近的好,我们就扩大半径,否则就缩小半径。
为信赖域半径,如果泰勒展开逼近的好,我们就扩大半径,否则就缩小半径。
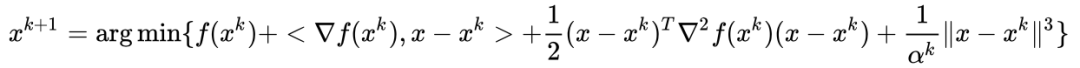
二、Stochastic Methods
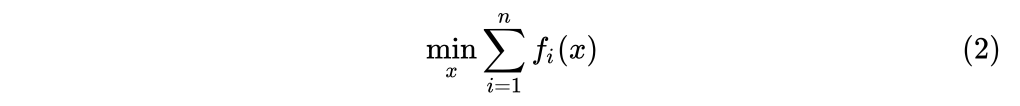
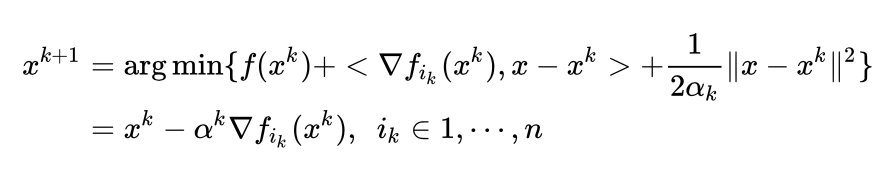
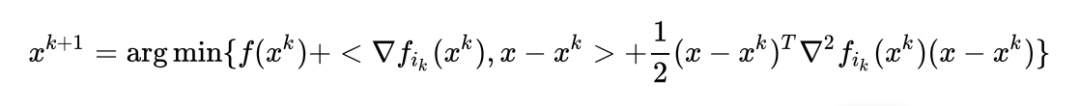
三、临近类方法
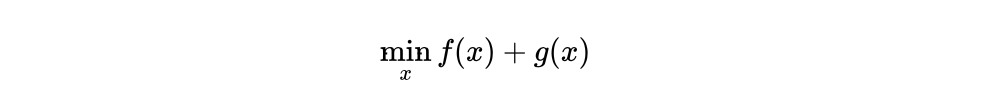
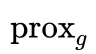
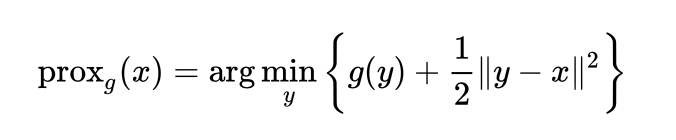
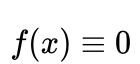 ,PPA有如下迭代
,PPA有如下迭代
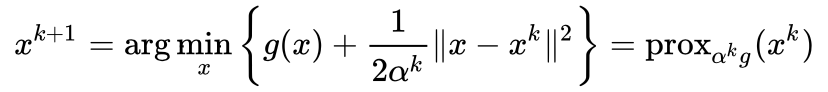
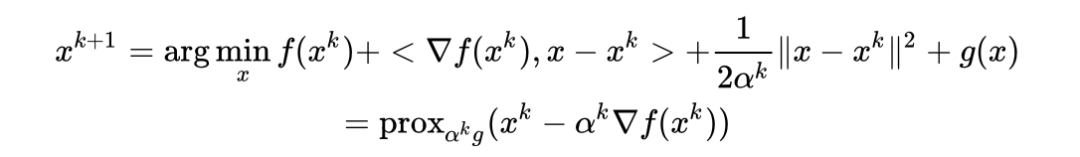
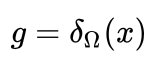 ,那么PGA就变成了投影梯度方法了(神奇吧)。
,那么PGA就变成了投影梯度方法了(神奇吧)。
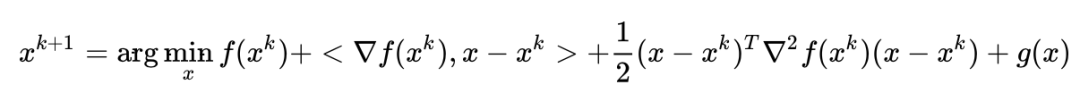
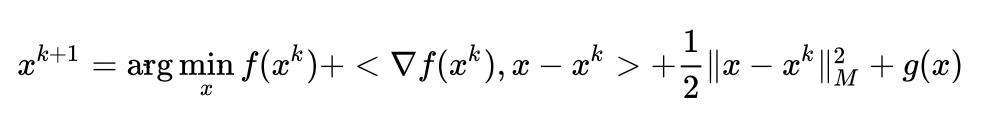
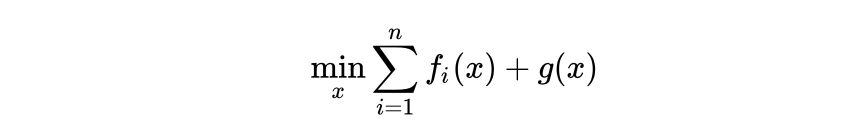
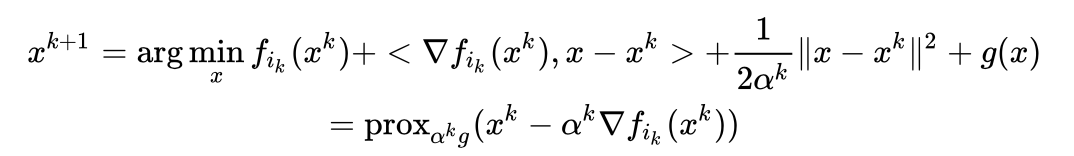
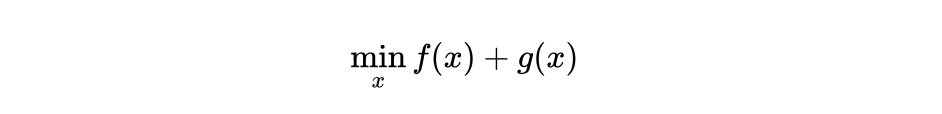
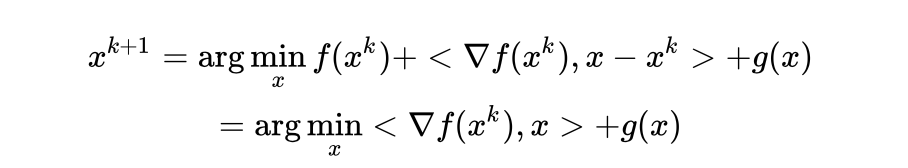
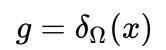 ,上述问题变为
,上述问题变为
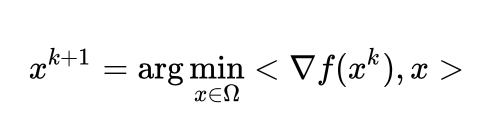
四、对偶类方法
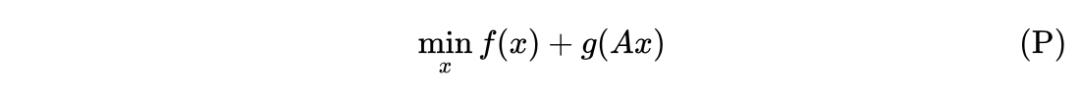
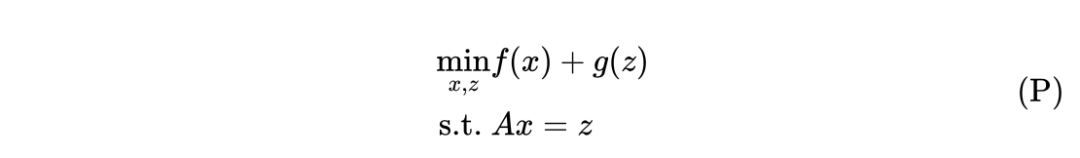
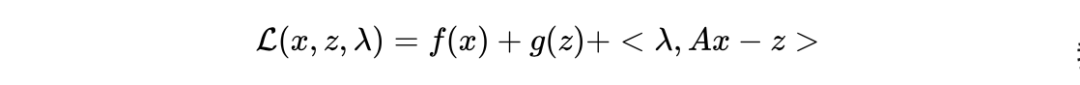
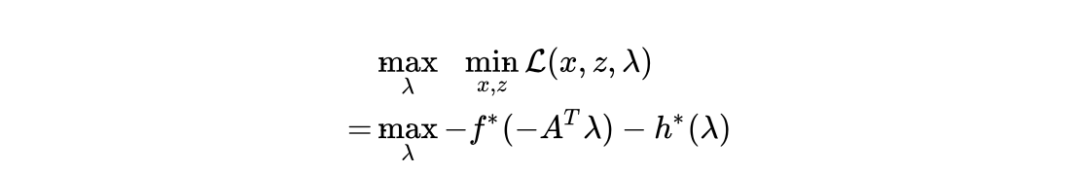
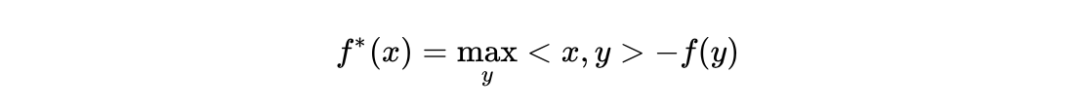
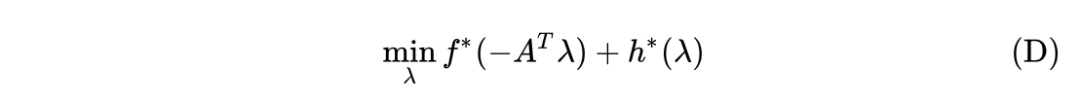
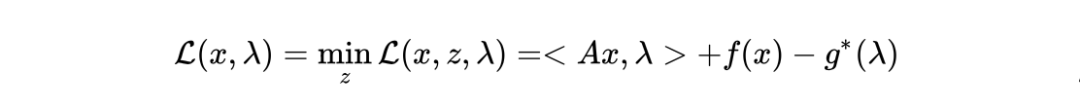
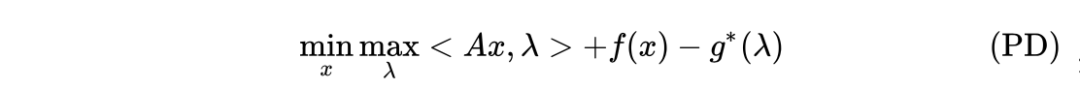
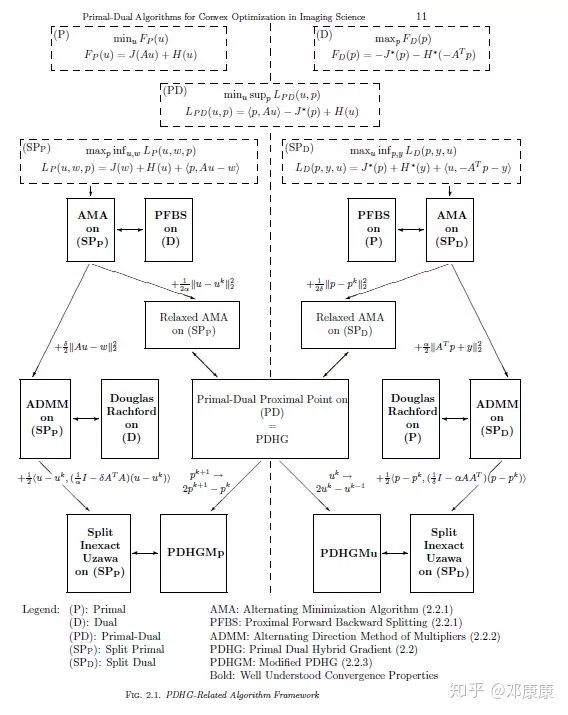
*延伸阅读
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
分析梯度下降的轨迹,更好地理解深度学习中的优化问题
网络深度对深度学习模型性能有什么影响?
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、OCR、姿态估计等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~

登录查看更多
相关内容

专知会员服务
33+阅读 · 2020年4月26日
专知会员服务
43+阅读 · 2020年4月22日
专知会员服务
49+阅读 · 2020年1月1日
专知会员服务
16+阅读 · 2019年11月30日
专知会员服务
23+阅读 · 2019年11月21日
专知会员服务
44+阅读 · 2019年11月20日
Arxiv
11+阅读 · 2018年7月12日
Arxiv
6+阅读 · 2018年3月30日



相关VIP内容
专知会员服务
33+阅读 · 2020年4月26日
专知会员服务
43+阅读 · 2020年4月22日
专知会员服务
49+阅读 · 2020年1月1日
专知会员服务
16+阅读 · 2019年11月30日
专知会员服务
23+阅读 · 2019年11月21日
专知会员服务
44+阅读 · 2019年11月20日
相关资讯
相关论文
Arxiv
11+阅读 · 2018年7月12日
Arxiv
6+阅读 · 2018年3月30日