MMDetection v2.0 训练自己的数据集
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:cjsnx shsb
https://zhuanlan.zhihu.com/p/162730118
本文已由原作者授权,不得擅自二次转载
上一次安装mmdetection的docker环境离现在已经快一个月了,本来打算隔三五天记录一下,然后一直拖延到现在都没记录更新。。。。这个项目是打算记录安装环境,训练模型最后到源码解析。
1 新建容器
进入正题 mmdetection docker环境上次已经介绍一次了 ,现在我们新建一个容器
sudo nvidia-docker run -shm-size=8g -name mm_det -it -v /train_data:/mmdetection/datanvidia-docker:新建容器能调用GPU
-name : 容器名称 可自行修改
-v :映射宿主目录到容器目录, /train_data 是宿主目录,映射到容器目录 /mmdetection/data
退出容器
exit重新进入容器
sudo docker exec -i -t mm_det /bin/bashdoxker exec :在运行的容器中执行命令
-i -t : 交互模式执行
mm_det : 容器名称
/bin/bash :执行脚本
2 准备自己的VOC数据集
mmdetection 支持VOC数据集,还有COCO数据集格式,还可以自定义数据格式,现在我们采用VOC的数据格式,mm_det容器已经映射宿主目录了,在宿主目录/train_data,新建目录存放数据集,可在容器内/mmdetection/data里在操作,新建目录结构如下
VOCdevkit
--VOC2007
----Annotations
----ImageSets
------Main
----JEPGImages
Annotations 目录存放.xml文件,JEPGImages 存放训练图片,划分数据集使用以下代码,
代码保存在/VOCdevkit/VOC2007 目录下 ,直接执行
import os
import random
trainval_percent = 0.8
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()上述代码分割数据集,训练集占80%,测试集占20% 运行代码后可在/VOCdevkit/VOC2007/ImageSets/Main看见三个.txt文件
三个.txt文件里面分别是训练测试图片名称的索引,数据集准备到这就完成了
3 修改 VOC0712.py 文件
cd /mmdetection/configs/_base_/datasets进入目录后打开voc0712.py
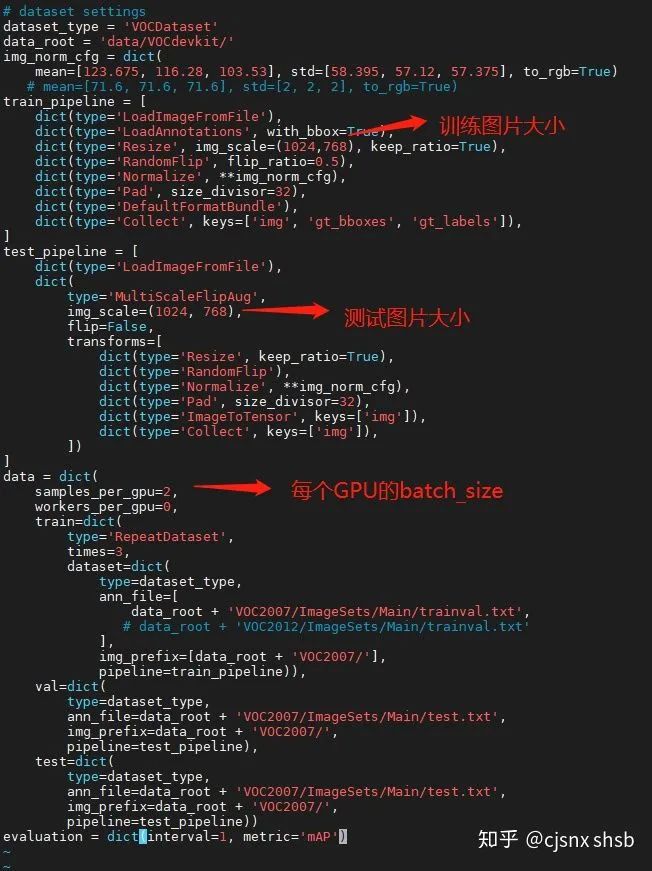
在data的配置 要删除屏蔽VOC2012的路径,和VOC2012变量 保存文件
4 修改 voc.py 文件
cd /mmdetection/mmdet/datasets打开 voc.py文件
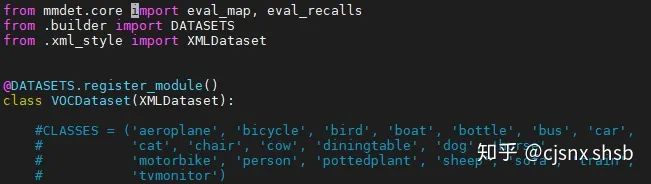
这个CLASSE 是VOC标签的类别 我们要换成自己数据集的类别标签
5 修改class_names.py 文件
cd /mmdetection/mmdet/core/evaluation打开 class_names.py 文件
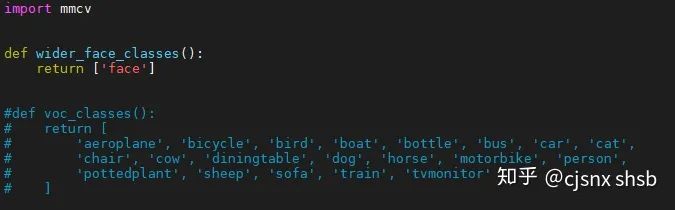
修改 voc_classes() 函数返回的标签,换成自己数据集的标签 保存退出
6 修改 faster_rcnn_r50_fpn_1x_coco.py
cd mmdetection/configs/faster_rcnn
我们这次选用faster_rcnn 模型训练,打开faster_rcnn_r50_fpn_1x_coco.py文件

faster_rcnn_r50_fpn_1xcoco.py文件里面调用了三个文件,第一个是模型配置文件,第二个是数据集配置文件,后来两个是配置学习率,迭代次数,模型加载路径等等,我们把原来COCO_detection.py 修改成VOC0712.py 文件
7 修改faster_rcnn_r50_fpn.py
cd /mmdetection/configs/_base_/models打开 faster_rcnn_r50fpn.py 文件 ,修改num_classes 数量,num_classes 的值等于类别数量,不需要加背景了
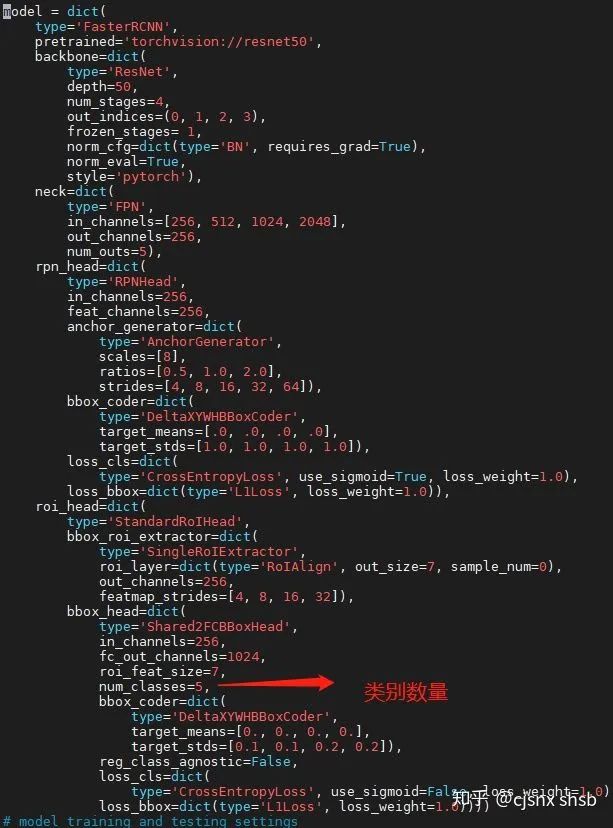
以上就是需要修改的内容,修改完成后开始训练模型
8 训练模型
python3 ./tools/train.py ./configs/faster_rcnn_r50_fpn_1x.py
训练完成后可以参考/mmdetection/demo/image_demo.py文件进行测试
以上就是使用自己的数据集集训练mmdetection faster_rcnn模型的所有内容
下载1
在CVer公众号后台回复:PRML,即可下载758页《模式识别和机器学习》PRML电子书和源码。该书是机器学习领域中的第一本教科书,全面涵盖了该领域重要的知识点。本书适用于机器学习、计算机视觉、自然语言处理、统计学、计算机科学、信号处理等方向。

PRML
下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4100人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!