CVPR 2020 | 用完全可训练的深度学习方式处理图匹配问题

编辑 | 丛 末

在计算机视觉领域,基于学习的图匹配方法已经有十多年的发展和探索史,近几年发展和普及速度更迅速。然而,以往的基于学习的算法,无论有无深度学习策略,都主要集中在节点学习和/或边缘仿射的生成上,而对组合求解器的学习关注较少。
亮风台及其合作伙伴提出了一个完全可训练的图匹配框架,在该框架中,仿射学习和组合优化求解并不像以往的许多技术那样被明确地分开。团队首先将两个输入图之间建立节点对应的问题转化为从一个已构造的分配图中选择可靠节点的问题。随后,采用图网络块模块对图进行计算,形成各节点的结构化表示。最后为每个节点预测一个用于节点分类的标签,并在排列差分和一对一匹配约束的正则化下进行训练。
1、图匹配问题
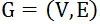 表示,其中
表示,其中
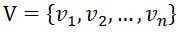 和
和
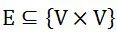 分别表示节点集和边缘集。图通常由一个对称邻接矩阵
分别表示节点集和边缘集。图通常由一个对称邻接矩阵
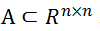 表示,当且仅当
表示,当且仅当
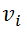 与
与
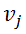 之间存在边时,
之间存在边时,
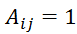 。通常将非负实值权重
。通常将非负实值权重
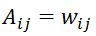 与所有节点对相关联,将邻接矩阵泛化为加权图。这种概括对于许多应用程序捕获节点之间的结构关系很重要。在本文的其余部分中,除非另有说明,否则所有提及的邻接矩阵均以实数值加权。
与所有节点对相关联,将邻接矩阵泛化为加权图。这种概括对于许多应用程序捕获节点之间的结构关系很重要。在本文的其余部分中,除非另有说明,否则所有提及的邻接矩阵均以实数值加权。
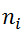 为的图
为的图
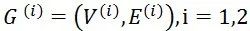 ,不失一般性我们假设
,不失一般性我们假设
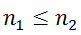 。图匹配问题可以表示为找到一个节点对应关系
。图匹配问题可以表示为找到一个节点对应关系
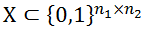 以支持如下的全局一致性:
以支持如下的全局一致性:
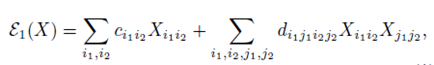
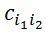 表示
表示
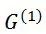 中第
中第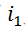 个节点与
个节点与
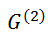 中第
中第
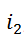 个节点的一致性,
个节点的一致性,
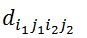 表示中边
表示中边
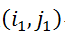 与
中边
与
中边
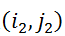 的一致性。匹配矩阵代表了匹配结果,即当且仅当中第个节点匹配中第个节点时
的一致性。匹配矩阵代表了匹配结果,即当且仅当中第个节点匹配中第个节点时
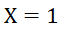 。在实际应用中,经常将图匹配约束为一一匹配,即
。在实际应用中,经常将图匹配约束为一一匹配,即
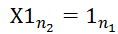 且
且
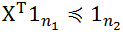 ,其中
,其中
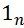 表示n个元素为1的列向量。
表示n个元素为1的列向量。
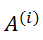 表示图
表示图
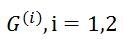 的邻接矩阵,用于加权图匹配[1,18]的更常用公式定义为:
的邻接矩阵,用于加权图匹配[1,18]的更常用公式定义为:
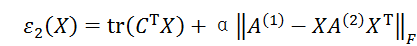
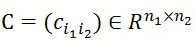 是节点间的不相似矩阵,
是节点间的不相似矩阵,
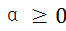 为平衡节点一致性与边一致性的权值,表示矩阵的Frobenius范数。
为平衡节点一致性与边一致性的权值,表示矩阵的Frobenius范数。
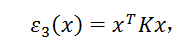
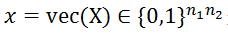 是匹配矩阵X的向量化形式,
是匹配矩阵X的向量化形式,
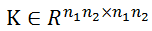 是图匹配亲密矩阵,定义为:
是图匹配亲密矩阵,定义为:
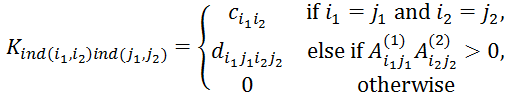
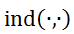 是将节点对应关系映射到整数索引的双射函数。
是将节点对应关系映射到整数索引的双射函数。
2、匹配作为节点标注问题
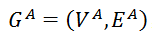 ,两个图与之间的图匹配问题可以解释为分配图上的节点标注问题。
,两个图与之间的图匹配问题可以解释为分配图上的节点标注问题。
 视为一个节点
视为一个节点
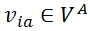 ,每个矩阵元素
,每个矩阵元素
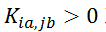 对应于一条边
对应于一条边
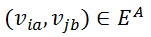 且其属性为
且其属性为
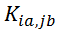 。图1为一个由亲密矩阵K构造的分配图示例,其中与之间每个候选匹配对应于分配图
。图1为一个由亲密矩阵K构造的分配图示例,其中与之间每个候选匹配对应于分配图
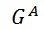 中
的一个节点。因此,与之间的原始图匹配问题等同于选择图中的可靠节点。
中
的一个节点。因此,与之间的原始图匹配问题等同于选择图中的可靠节点。
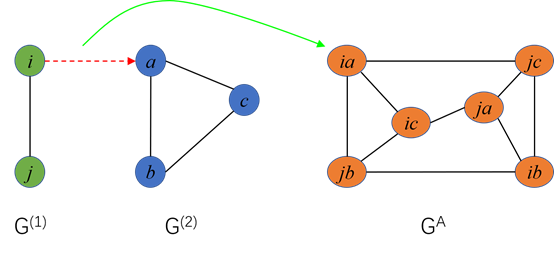

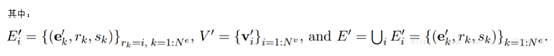
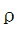 ,和4个更新函数
,和4个更新函数
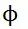 ,
,
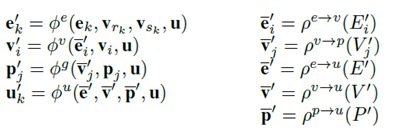
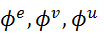 和
聚合函数
和
聚合函数
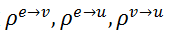 是从原始GN框架而来的,而更新函数
是从原始GN框架而来的,而更新函数
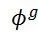 和聚合函
数
和聚合函
数
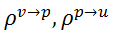 是在我们群组敏感的GN模块中新提出的。
是在我们群组敏感的GN模块中新提出的。

1、模拟2D点集
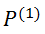 和
和
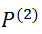 ,其中包含
,其中包含
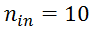 个内部点,然后将
个内部点,然后将
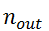 个离群点添加到这两个集合中。
在平面的给定区域中随机选择
个离群点添加到这两个集合中。
在平面的给定区域中随机选择
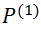 中的内点。
然后,我们对齐添加高斯白噪声
中的内点。
然后,我们对齐添加高斯白噪声
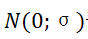 干扰,然后旋转和平移整个点集,从而获得中的对应内点。
每组的离群点是从与内点相同的区域中随机选择。
中点坐标的范围是
干扰,然后旋转和平移整个点集,从而获得中的对应内点。
每组的离群点是从与内点相同的区域中随机选择。
中点坐标的范围是
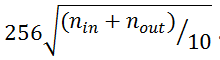 。
给定两对点
。
给定两对点
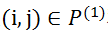 和
和
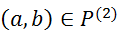 ,其边的亲密度计算为:
,其边的亲密度计算为:
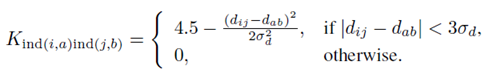
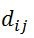 (及
(及
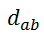 )表示点i和j(及a和b)之间的欧几里得距离,参数d控制亲密度对变形的敏感性。
在整个实验中,我们将d设置为5。
)表示点i和j(及a和b)之间的欧几里得距离,参数d控制亲密度对变形的敏感性。
在整个实验中,我们将d设置为5。
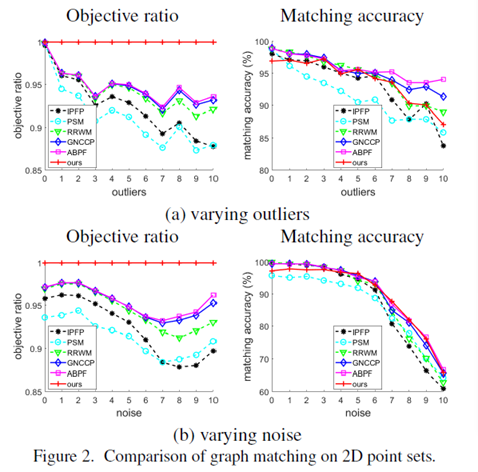
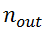 (图2(a))和噪声参数
(图2(a))和噪声参数
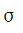 (图2(b))比较两种不同设置下算法的性能。
(图2(b))比较两种不同设置下算法的性能。
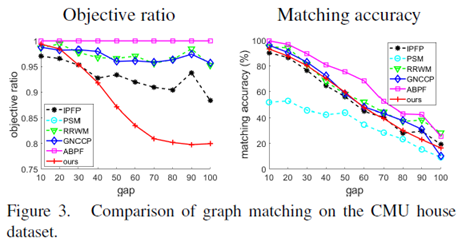
2、CMU House数据集
中的边(i,j)和中的边(a,b)之间的边亲和度为
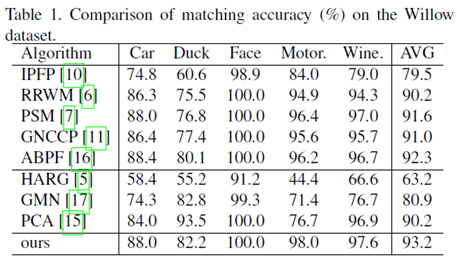
3、Willow数据集
 关联,其中dij是节点vi和vj之间的欧氏距离,而是边(i,j)与水平线之间的绝对角度,即
关联,其中dij是节点vi和vj之间的欧氏距离,而是边(i,j)与水平线之间的绝对角度,即
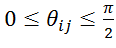 。
随后,计算中的边(i,j)和中的边(a,b)之间的边亲和度为:
。
随后,计算中的边(i,j)和中的边(a,b)之间的边亲和度为:
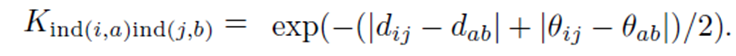
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiangbaoshang@yanxishe.com

登录查看更多
相关内容
Arxiv
9+阅读 · 2018年5月11日



相关VIP内容
相关资讯
相关论文
Arxiv
9+阅读 · 2018年5月11日