从数据结构到算法:图网络方法初探
机器之心原创
如果说 2019 年机器学习领域什么方向最火,那么必然有图神经网络的一席之地。其实早在很多年前,图神经网络就以图嵌入、图表示学习、网络嵌入等别名呈现出来,其实所有的这些方法本质上都是作用在图上的机器学习。本文将根据近两年的综述对图网络方法做一个总结,为初入图世界的读者提供一个总体的概览。
本文作者朱梓豪为中科院信工所在读硕士,主要研究方向为图神经网络、视觉问答、视觉对话等。
什么是图
图是一种常见的数据结构,用于表示对象及其之间的关系。其中,对象又称节点(node)或顶点(vertex),关系用边(edge)来描述。在数学上一般用 G=(V,E,A,X) 来表示,其中 V={v1,v2……,vn} 是节点集合,E=e_ij 表示边的集合,A 是大小为|V|×|V|的邻接矩阵,用于表示节点之间的连接关系,如果 e_ij∈E,则 A_ij=1,X 是大小为|V|×d 的特征矩阵,X 的第 i 行 X_i:表示第 i 个节点的属性特征,其中 d 是属性的维度。
为何需要在图上应用机器学习方法
图是一种描述和建模复杂系统的通用语言,在真实世界中无处不在。例如,Facebook、 Twitter 等社交媒体构成了人类之间的社交网络 (Social Network);人体中的蛋白质分子构成了生物网络 (Biological Network);各种移动终端构成了通信网络 (Communication Network);智能硬件之间构成了物联网 (Internet-of-Things) 、城市间的公路、铁路、航线构成了运输网络 (Transportation Network) 等等。因此也催化出一系列在图上进行数据挖掘的任务,如为用户推荐感兴趣的好友、判断蛋白质结构、预测交通流量、检测异常账户等等。但是真实图的数据量庞大,动辄上亿节点、而且内部拓扑结构复杂,很难将传统的图分析方法如最短路径、DFS、BFS、PageRank 等算法应用到这些任务上。鉴于机器学习在图像、文本领域的广泛应用,一部分研究者尝试将机器学习方法和图数据结合起来,逐渐成为机器学习领域的一股热潮。
网络表示学习、图嵌入的定义
俗话说「巧妇难为无米之炊」,再强大的机器学习算法也需要数据进行支持。在同样的数据集和任务上,由于特征的不同,同一个算法的结果也可能会有天壤之别。由于特征的选择对结果的决定性作用,很多数据挖掘方面的研究工作把重心放到了针对特定的数据由人工设计出有价值的特征上。
深度学习本质上是一种特征学习方法,其思想在于将原始数据通过非线性模型转变为更高层次的特征表示,从而获得更抽象的表达。与人工设计特征不同,深度学习会自动从数据中学习出特征表示,所以又称为表示学习(Representation Learning)。如图像分类,输出的一张高维的图片,经过一系列的卷积池化等操作,低层可以抽取出低级的特征(轮廓、颜色)、较深的层会根据低级特征学习到更高级的特征,然后变换成一个向量通过全连接层进行分类,这个向量就是输入图像的特征表示。
一个很自然的想法就是,既然直接在图上直接应用机器学习方法比较困难,那么能否先将节点或边用低维向量表示出来,然后在这些向量上应用已经很成熟的机器学习算法。这种将图中节点嵌入到低维欧式空间中的方法就叫做图嵌入(Graph Embedding)。
其实、图嵌入、网络嵌入、图表示学习、网络表示学习这些名词指的的都是同一个概念。给定图$G=(\mathbf{V,E,A,X})$,图嵌入需要学习从节点到向量的映射:$f:v_i\to \mathbf{y}_i \in R^d$,其中$d<<|V|$,$f$需要尽可能的保留住节点的结构信息和属性信息。
图嵌入方法的分类
图数据最大的特点在于节点之间存在着链接关系,这表明图中节点之间并非完全独立。除了节点间的链接关系,节点自身也可能含有信息,比如互联网中网页节点对应的文本信息,这些特性使得图嵌入需要考虑很多的因素。从训练所需的信息来看,一般有三种主要的信息源:图结构、节点属性和节点标签,可基于此分成无监督图嵌入和半监督图嵌入;还有一种是根据输入数据的不同进行划分,比如按照边的方向性、是否是异构网络等性质。然而这两种划分依据并不合适,因为当前图嵌入算法的主要区别在于算法类型,同一算法类型下的框架都是相似的,因此本文基于 Hamilton 等 [1] 和 Goyal 等 [2] 两篇关于图嵌入的综述,将图嵌入方法概括为基于矩阵分解的图嵌入、基于随机游走的图嵌入、基于神经网络的图嵌入(即图神经网络)。
基于矩阵分解的图嵌入
基于矩阵分解的方法是将节点间的关系用矩阵的形式加以表示,然后分解该矩阵以得到嵌入向量。通常用于表示节点关系的矩阵包括邻接矩阵、拉普拉斯矩阵、节点转移概率矩阵、节点属性矩阵等。根据矩阵的性质不同适用于不同的分解策略。主要包括 Local Linear Embedding(LLE)[3]、Laplacian Eigenmaps[4]、SPE[5]、GraRep[6] 等。
LLE 算法其实是流形学习的一种,LLE 算法认为每一个数据点都可以由其邻域节点的线性加权组合构造得到。降维到低维空间后,这种线性关系仍然得到保留。Laplacian Eigenmaps 和 LLE 有些相似,直观思想是希望相互间有关系的点(在图中相连的点)在降维后的空间中尽可能的靠近。为了使得输入图的嵌入是低维表示并且保留图全局拓扑结构,Shaw 等 [5] 提出在欧式空间中嵌入图的结构保留嵌入方法(SPE,Structure Preserving Embedding),学习由一组线性不等式约束的低秩核矩阵,用于捕获输入图结构。SPE 在图的可视化和无损压缩方面获得明显改善,优于 Laplacian Eigenmaps 等方法。Cao 等 [6] 认为考虑节点之间的 k 阶关系对把握网络的全局特征非常重要,考虑越高阶的关系,得到的网络表示效果会越好。GraRep 通过 SVD 分解分别学习节点的 k 阶表示,然后将其结合起来作为最终的表示,这样可以很好地捕捉到远距离节点之间的关系。
基于随机游走的方法
随机游走方法已经被用来近似图的许多属性,包括节点中心性和相似性等。当图的规模特别大或者只能观察到部分图的时候,随机游走就变得非常有用。有研究者提出了利用图上随机游走来获取节点表示的嵌入技术,其中最著名的就是 DeepWalk[7] 和 node2vec[8]。
DeepWalk 是基于 word2vec 词向量提出来的。word2vec 在训练词向量时,将语料作为输入数据,而图嵌入输入的是整张图,两者看似没有任何关联。但是 DeepWalk 的作者发现,预料中词语出现的次数与在图上随机游走节点被访问到底的次数都服从幂律分布。因此 DeepWalk 把节点当做单词,把随机游走得到的节点序列当做句子,然后将其直接作为 word2vec 的输入来得到节点的嵌入表示。其框架如图 1 所示,首先采用随机游走的方法产生标准的输入序列,用 SkipGram 模型对序列建模得到节点的向量表示,然后使用分层 softmax 解决节点高维度输出问题。DeepWalk 模型的提出为图嵌入提出了一种新的研究思路,也算是引发了对图嵌入研究的热潮。
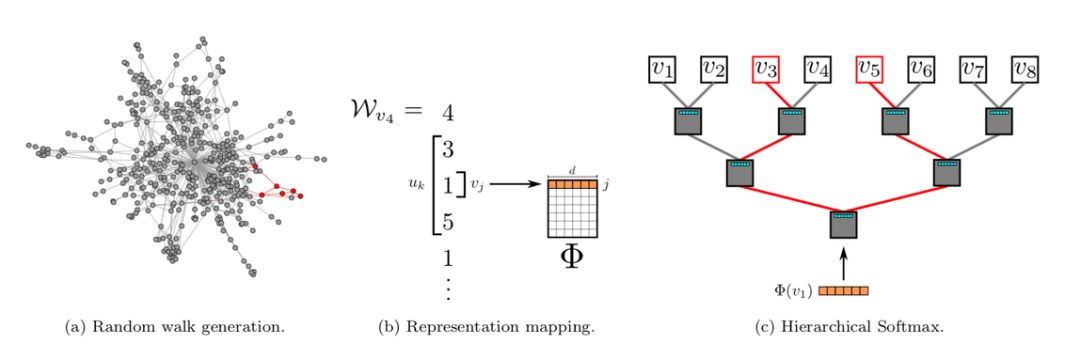
图一
node2vec 通过改变生成随机游走序列的方式改进了 DeepWalk 算法。DeepWalk 是按照均匀分布随机选取随机游走序列的下一个节点。node2vec 同时考虑了广度优先搜索 (BFS) 和深度优先搜索 (DFS)。Grover 等发现,广度优先搜索注重刻画网络中的局部特征,而深度优先搜索能更好地遍历整个网络,反映了节点间的同质性。特别地,node2vec 引入 search bias 函数来平衡这两种采样方式,通过参数 p 和 q 来调整下一步的跳转概率。
其他基于随机游走的方法还包括 Walklets、LsNet2vec、TriDNR、HARP、DDRW 等等。
基于神经网络的图嵌入(图神经网络)
还有一类方法是将神经网络和图结合起来的图表示学习方法,也是最近一年来最火的方向之一,我们统称为图神经网络。机器之心已经为其做过了全面的介绍,具体请参见:深度学习时代的图模型,清华发文综述图网络 、清华大学图神经网络综述:模型与应用、图神经网络概述第三弹:来自 IEEE Fellow 的 GNN 综述。主要将其分为图卷积网络、图注意力网络、图生产网络、图时空网络、图自编码器。又可以分为基于谱的方法和基于空间的方法。由于基于谱的方法需要分解矩阵特征向量,因此绝大多数新提出的方法都是基于空间,也就是如何传播并聚合节点和边的信息。图像和文本本质上是有规则的格栅结构的图,因此,很自然想到可以将已经在 CV、NLP 领域成功应用的模型拓展到图上,如词向量和图卷积。最近,也出现了基于胶囊的图神经网络和基于图像语义分割 U-Net 模型的 Graph U-Net。
注意力机制的在图嵌入的应用
有一部分研究者将注意力 (attention) 机制引入到了图神经网络中。注意力机制的本质是从人类视觉注意力机制中获得灵感。大致是我们视觉在感知东西的时候,一般不会是一个场景从到头看到尾全部都看,而是根据需求观察特定的一部分。这意味着,当人们注意到某个目标或某个场景时,该目标内部以及该场景内每一处空间位置上的注意力分布是不一样的。而且当我们发现一个场景经常在某部分出现自己想观察的东西时,我们就会进行学习在将来再出现类似场景时把注意力放到该部分上。更通用的解释就是,注意力机制是根据当前的某个状态,从已有的大量信息中选择性的关注部分信息的方法,其实就是一系列 注意力分配系数。
基于注意力机制的 GNN 的思想是在计算每个节点的表示的时候,首先计算其和邻居节点之间的注意力系数,为重要的邻居节点分配较大的权重,在聚合的过程中将不同的重要性分配给邻域内不同的节点。
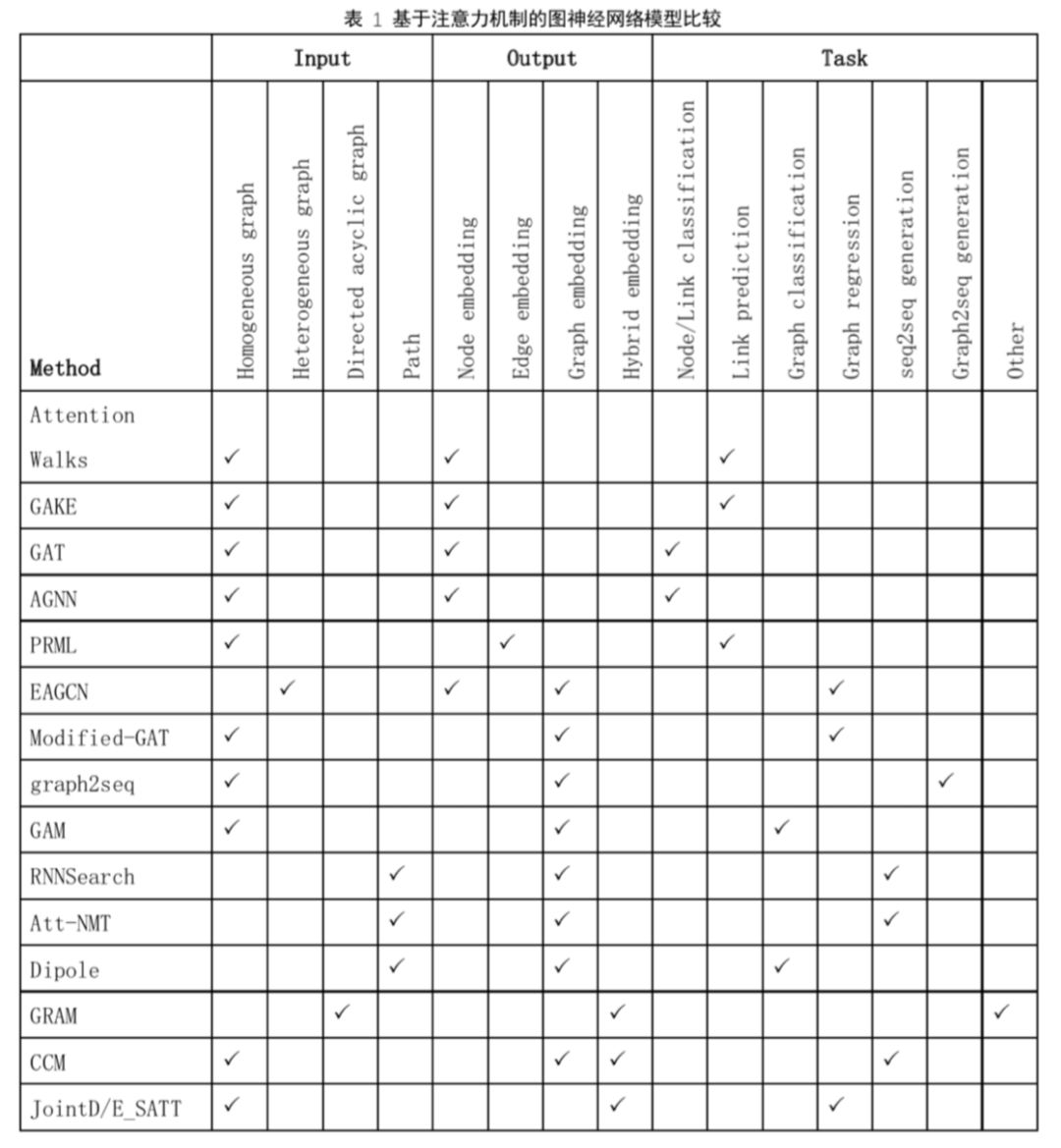
表 1 按照输入、输出、任务对近两年发表的基于注意力机制的图神经网络模型进行汇总比较,下面对几个具有代表性的模型进行概述,具体内容请参照论文《Attention Models in Graphs: A Survey》[9]。
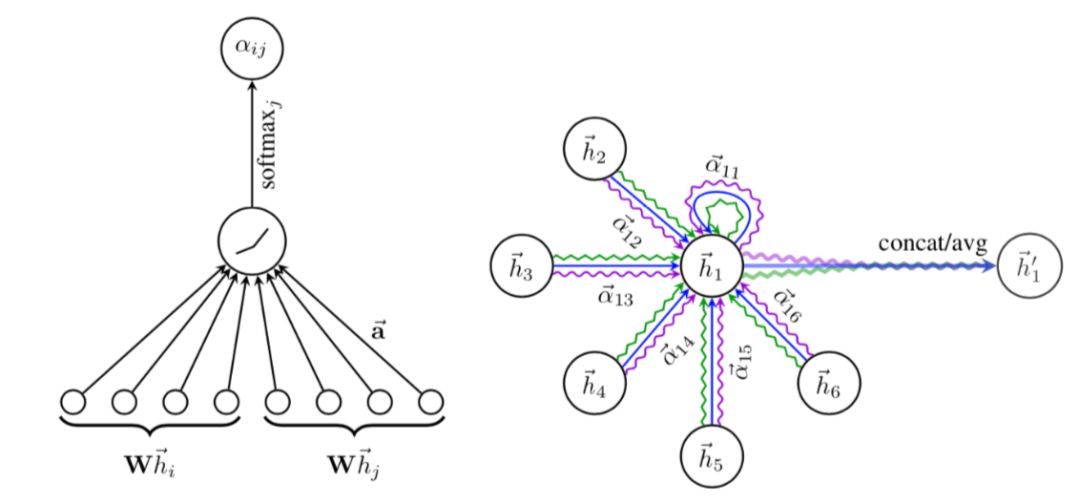
Yoshua Bengio 的 MILA 团队在 2018 年提出了图注意力网络 (Graph Attention Networks, GAT)[10],论文中定义了 Graph attention 层,通过叠加不同的 attention 层,可以组成任意结构的图神经网络,其架构如图所示,最终要的步骤就是计算节点 i 的邻居节点对其的注意力系数$\alpha_{ij}$, 这里还是用了多头注意力机制,图中不同的颜色代表不同的头。
不同于 GAT 是节点分类,DAGCN[11] 用于图分类任务。模型中包括两个 attention 单元,一个是和 GAT 一样,用于图卷积得到节点的表示,另一个是基于 attention 的池化操作,得到整个图的表示,然后将图表示输入到一个 MLP 得到整个图的分类。作者认为,经典的 GCN 每一层都只能捕获第 k-hop 邻域的结构信息,只有最后一层的 H 被用下一步的预测,随着网络层数的增多,会丢失大量的信息。作者提出的 attention 层的思想是不仅要依赖于第 k-hop 的结果, 还要从前面每一个 hop 捕获有价值的信息。
综合各种图注意力网络的论文来看,最主要的区别在于如何定义和实现注意力机制。第一类是学习 attention weights:
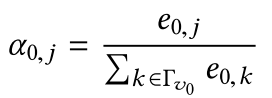
主要是通过 softmax 函数实现的,同时还需要一个基于节点属性可训练的计算节点 j 和节点 0 相关性的函数,例如 GAT 的实现方式为:
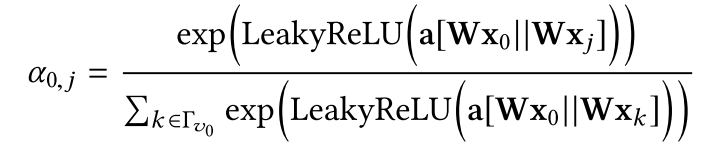
其中 W 是将节点属性映射到隐空间的可训练的参数矩阵,||表示串接。
第二类基于相似度的 attention,同样,给定相应的属性或特征,第二种注意力的学习方法与上面的方法类似,但有一个关键的区别是更多的注意力集中在具有更多相似隐藏表示或特征的节点上,这在文献中也经常被称为对齐。以 AGNN 中的公式为例:
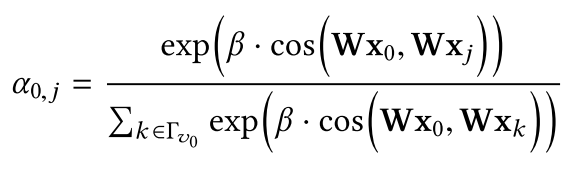
其中 cos 来计算余弦相似度,可以看到和上式非常相似。不同之处在于,模型显式地为彼此相关的对象学习类似的隐藏嵌入,因为注意力是基于相似性或对齐的。
前两种注意力主要集中在选择相关信息以整合到目标对象的隐藏表示中,而第三种注意力的目的略有不同,叫做基于注意力的游走。举例来说,在一个输入图上执行一系列游走,并使用 RNN 对访问的节点信息进行编码,从而构造一个子图嵌入。RNN 的 t 时刻的隐藏状态对 1 到 t 访问的节点进行编码。Attention 就是一个函数$f』(h_t)=r_{t+1}$, 输入的是 t 时刻的隐藏状态,输出一个 rank vector,告诉我们下一步我们应该优先考虑哪种类型的节点。
框架
这里简单的介绍一下 Hamilton 在论文 [1] 中提出的一种图嵌入 encoder-decoder 框架(如图),可以将大多数的图嵌入方法用这个框架来表示。在这个框架中,我们围绕两个关键的映射函数组织了各种方法:一个 encoder(它将每个节点映射到一个低维向量) 和一个 decoder(它从已知的嵌入中解码关于图的结构信息)。encoder-decoder 背后的直觉想法是这样的:如果我们能从低位嵌入表示中学会解码高维图信息,如节点在图中的全局位置或节点的局部邻域结构,那么原则上,这些嵌入应包含下游机器学习任务所需的所有信息。
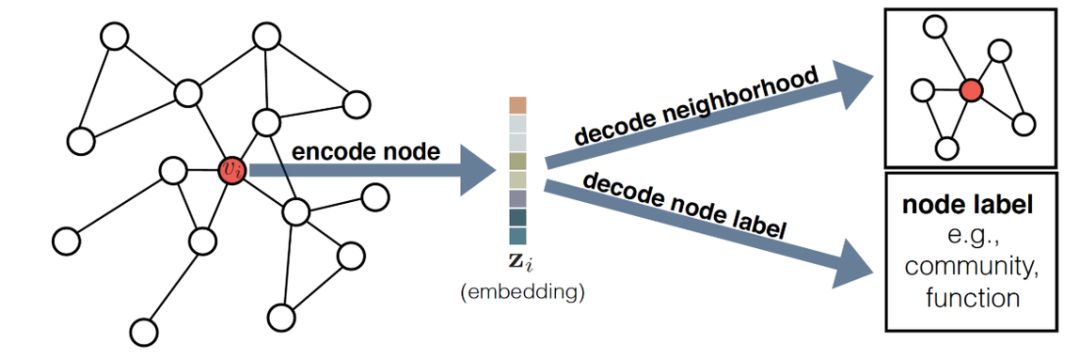
encoder 是一个函数:
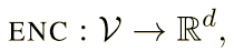
将节点 i 映射到嵌入向量$z_i \in R^d$。decoder 是接受一组节点嵌入并从这些嵌入中解码用户指定的图统计数据的函数。例如,decoder 可能根据节点的嵌入预测节点之间是否存在边,或者可能预测图中节点所属的社区。原则上,有许多 decoder 都是可以使用的,但是在大多数工作中使用的是成对 decoder:
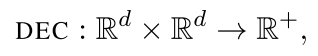
当我们将成对 decoder 应用于一对嵌入$(z_i,z_j)$时,我们得到了原始图中$v_i$和$v_j$之间相似性的重构,目标就是最小化重构后的相似性和原图中相似性的误差:
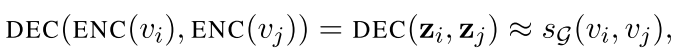
其中其中 SG 是一个用户定义的、在图 G 上的的节点间相似性度量。换句话说,目标是优化 encoder-decoder 模型,可以从低维节点嵌入 z_i 和 z_j 中解码出原始图中 SG(v_i, v_j) 成对节点相似性。例如可以设 SG(v_i, v_j)=A_{ij},如果节点相邻则定义节点的相似度为 1,否则为 0。或者可以根据在图 G 上的固定长度随机游走 v_i 和 v_j 共线的概率来定义 SG。在实践中,大多数方法通过最小化节点对集合 D 上的经验损失 L 来实现重构目标:
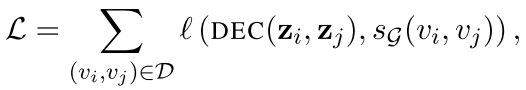
优化了上述目标函数后,我们就可以使用经过训练的 encoder 为节点生成嵌入,然后可以将其用作下游机器学习任务的特征输入。下表展示了常用图嵌入方法的 encoder-decoder 框架描述。

总结
图嵌入是指将图中节点用低维稠密向量来表示,从一开始的基于矩阵分解的方法逐渐出现了基于随机游走的方法,后来又演化出基于神经网络的方法也是我们经常听到的图神经网络。图嵌入目前还面临着一些挑战,例如如何在超大规模图上高效进行分析,如何应对真实世界中不断变化的动态图,如何对图神经网络的黑盒模型进行解释,以及如何建模异质图。目前在图网络领域也涌现出一些新的方向,例如如何针对图网络进行对抗攻击使其模型性能大幅下降,相反的就是如何提高模型的鲁棒性;如何将人工设计网络架构转变为由机器自动设计,这对应着网络结构搜索问题(NAS),以及如何将图网络和计算机视觉、自然语言处理等方向结合起来。这些都是很有价值也有意思的方向,感兴趣的读者可以进行更深度的研究。
参考文献:
[1] Hamilton, William L., Rex Ying, and Jure Leskovec. "Representation learning on graphs: Methods and applications." arXiv preprint arXiv:1709.05584 (2017).
[2] Goyal, Palash, and Emilio Ferrara. "Graph embedding techniques, applications, and performance: A survey." Knowledge-Based Systems 151 (2018): 78-94.
[3] Roweis, Sam T., and Lawrence K. Saul. "Nonlinear dimensionality reduction by locally linear embedding." science 290.5500 (2000): 2323-2326.
[4] Belkin, Mikhail, and Partha Niyogi. "Laplacian eigenmaps and spectral techniques for embedding and clustering." Advances in neural information processing systems. 2002.
[5] Shaw, Blake, and Tony Jebara. "Structure preserving embedding." Proceedings of the 26th Annual International Conference on Machine Learning. ACM, 2009.
[6] Cao, Shaosheng, Wei Lu, and Qiongkai Xu. "Grarep: Learning graph representations with global structural information." Proceedings of the 24th ACM international on conference on information and knowledge management. ACM, 2015.
[7] Perozzi, Bryan, Rami Al-Rfou, and Steven Skiena. "Deepwalk: Online learning of social representations." Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014.
[8] Grover, Aditya, and Jure Leskovec. "node2vec: Scalable feature learning for networks." Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2016.
[9] Lee, John Boaz, et al. "Attention models in graphs: A survey." arXiv preprint arXiv:1807.07984 (2018).
[10] Veličković, Petar, et al. "Graph attention networks." arXiv preprint arXiv:1710.10903 (2017).
[11] F.Chen,S.Pan,J.Jiang,H.Huo,G.Long,DAGCN:DualAttention
Graph Convolutional Networks, arXiv. cs.LG (2019).