集“百家”之长,成一家之言!微软提出全新预训练模型MPNet

编者按:近年来,预训练语言模型无疑成为了自然语言处理的研究热点。这些模型通过设计有效的预训练目标,在大规模语料上学习更好的语言表征来帮助自然语言的理解和生成。其中,BERT 采用的掩码语言模型 MLM 和 XLNet 采用的排列语言模型 PLM 是两种比较成功的预训练目标。然而,这两种训练目标各有优缺,具有较大的提升空间。为此,微软亚洲研究院机器学习组的研究员们,继去年面向自然语言生成任务推出预训练模型 MASS 之后,在自然语言理解任务上推出全新预训练模型 MPNet。它在 PLM 和 MLM 的基础上扬长避短,在自然语言理解任务 GLUE 和 SQuAD 中,超越 BERT、XLNet 和 RoBERTa 等预训练模型,取得了更好的性能。论文、代码和模型均已开放下载(见文末)。
继 BERT 在自然语言理解任务上取得了较大的精度提升后,预训练模型受到了广泛的关注。这些模型通过设计有效的预训练目标,在大规模语料上学习语言表征,以帮助下游自然语言处理任务,而预训练目标的好坏直接影响模型最终的性能。在众多的预训练目标当中,BERT 采用的掩码语言模型(Masked Language Modeling, MLM)和 XLNet 采用的排列语言模型 (Permuted Language Modeling, PLM) 是两种比较成功的预训练目标。
掩码语言模型 MLM 由 BERT 提出,它在序列中掩盖一些单词并用 [M] 替换,利用掩码后的序列预测出被掩码的单词。例如,给定序列 x=(x1,x2,x3,x4,x5),将 [x2,x4] 进行掩盖,基于掩码后的序列 (x1,[M],x3,[M],x5),MLM促使模型学习到好的语言表征以预测出 [x2,x4],如图 1(a) 左侧所示。
排列语言模型 PLM 由 XLNet 提出,它首先将句子打乱以构造出任意的排列,并利用自回归语言模型构建预测词之间的依赖关系。例如,给定序列 x=(x1,x2,x3,x4,x5),随机构造一个排列(x1,x3,x5,x2,x4),将 [x2,x4] 选为预测的单词。PLM 基于(x1,x3,x5)以自回归的方式预测 [x2,x4],如图 1(b) 右侧所示。
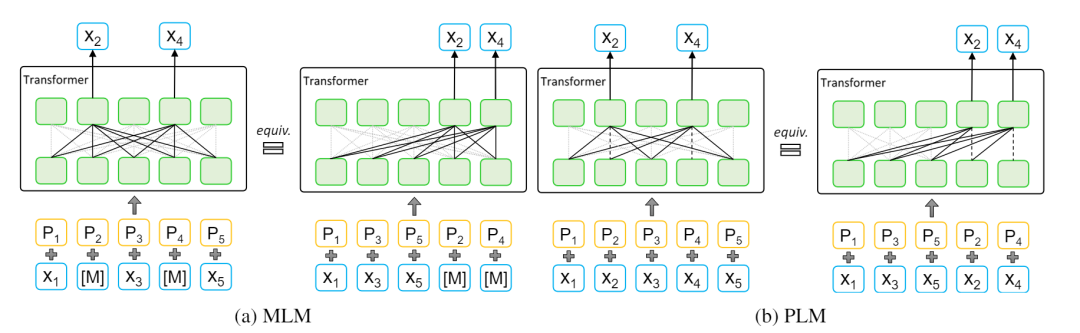
图1:(a) 掩码语言模型 MLM 和 (b) 排列语言模型PLM,(a) 和 (b) 右侧为 MLM 和 PLM 的统一视角。
通过比较 MLM 和 PLM,我们发现它们具有不同的优缺点:1)MLM 可以看到整个句子的位置信息,却不能建模预测单词之间的依赖,不利于建模句子中复杂的语义关系;2)PLM 虽然可以通过自回归建模预测单词之间的依赖关系,但却不能看到整个句子的位置信息,然而下游任务始终能看到整个句子的位置信息,这会导致预训练(pre-training)和微调(fine-tuning)之间的不一致。在文本中,我们吸取了 MLM 和 PLM 各自的优点,规避它们的缺点,设计出了更强的预训练模型 MPNet。
为了更好地吸取 MLM 和 PLM 的优点,我们将 MLM 和 PLM 纳入一个统一的视角下进行分析。预训练模型通常采用 Transformer 来学习句子表征。不同于 LSTM/CNN,Transformer 主要由自注意力机制和前馈网络构成,它对于顺序不敏感。一个单词加上对应位置信息之后,无论以哪种排列输入给 Transformer,都不会影响输出表征。对原始的 MLM(图1(a)左侧)来说,我们可以先打乱句子顺序再选择最后的几个单词进行掩盖预测(图1(a)右侧),这和原始 MLM 等价。这种新的 MLM 视角同 PLM 的视角(图1(b)右侧)一致。因此,无论哪种预训练目标(MLM还是 PLM),我们都可以将输入句子分为左侧的非预测部分和右侧的预测部分。
基于上述统一视角,我们可以看到 MLM 和 PLM 在非预测部分几乎一致,而不同的地方在预测部分。MLM 的优点是通过在预测部分引入掩码单词 [M] 以及对应的位置,让模型看到整个句子的位置信息,而 PLM 的优点是通过在预测位置引入自回归模型,来建模预测单词之间的依赖。如何能够同时吸收它们的优点,而不引入各自的缺点呢?在本文中,我们提出了新型的预训练模型 MPNet(Masked and Permuted Language Modeling),它能够在引入预测单词之间依赖的情况下看到整个句子的信息。
我们首先将 MLM 和 PLM 的非预测部分进行融合,例如,给定序列x=(x1,x2,x3,x4,x5,x6), 随机打乱得到序列 (x1,x3,x5,x4,x6,x2),我们选定右边的三个词 (x4,x6,x2) 为预测词,同时将非预测部分设为 (x1,x3,x5,[M],[M],[M]),对应的位置信息为 (p1,p3,p5,p4,p6,p2),而预测部分为 (x4,x6,x2) 以及位置信息 (p4,p6,p2)。如图2所示,我们通过引入输出单词依赖和输入位置补偿来结合 MLM 和 PLM 的优点。
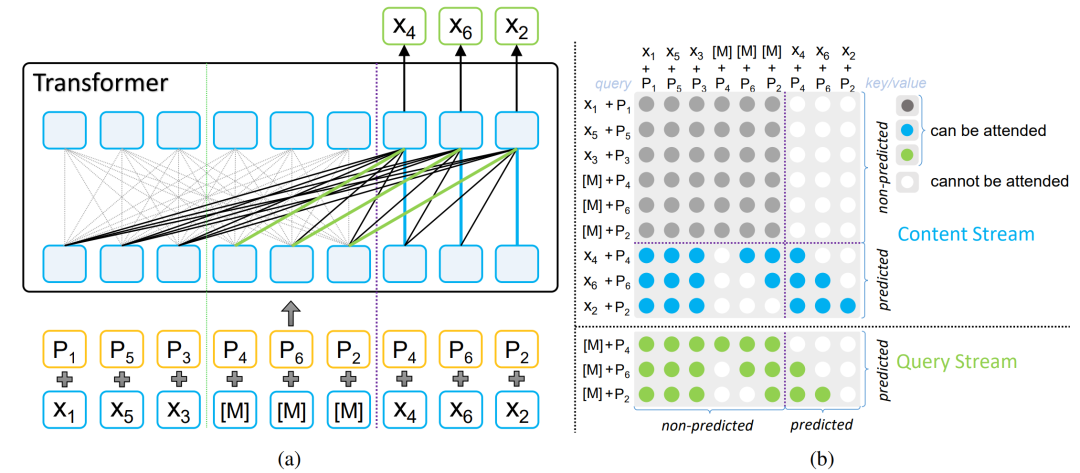
图 2:MPNet,(a) 是 MPNet 的结构图,(b)是 MPNet 中双流注意力机制的掩码示意。
输出单词依赖
为了建模预测单词之间的依赖,我们借鉴 PLM 中的双流自注意力机制(two-stream self-attention)来进行自回归预测。我们通过对双流中的 Query 流和 Content 流采用不同的注意力掩码,这能够让预测区域中的单词看到之前预测的单词。例如,当预测单词x6时,它可以看到非预测部分的 (x1+p1,x3+p3,x5+p5) 以及预测区域中前面的单词 (x4+p4),增加了 MLM 中缺少的依赖信息。
输入位置补偿
为了能在预测单词的时候让模型看到整个句子的位置信息,我们在非预测部分增加了被预测单词的掩码及位置信息,也就是 ([M]+p4,[M]+p6,[M]+p2)。为了让每个单词在预训练过程中能够看到整个句子的位置信息,我们给预测单词补偿缺失的位置信息。例如,当预测单词 x6 时,它除了能看到原始非预测部分 (x1+p1,x3+p3,x5+p5) 以及之前已经预测的单词 (x4+p4) 外,还可以看到非预测区域中的 [M]+p6 以及 [M]+p2。通过这样的补偿操作,可以确保模型在预测每个单词的时候都能够看到整个句子的位置信息,增加了 PLM 中缺失的位置信息。
为了分析 MPNet 在设计上的优势,我们首先对比分析不同预训练目标对于输入信息的利用。假设我们预测15%的单词,那么各个目标对单词信息以及位置信息的利用率如表1所示。我们发现 MPNet 在位置利用和单词利用上,结合了MLM 和 PLM 的优点,分别达到了92.5%和100%,高于单独的 MLM 和 PLM。关于信息比例如何计算请参见论文。
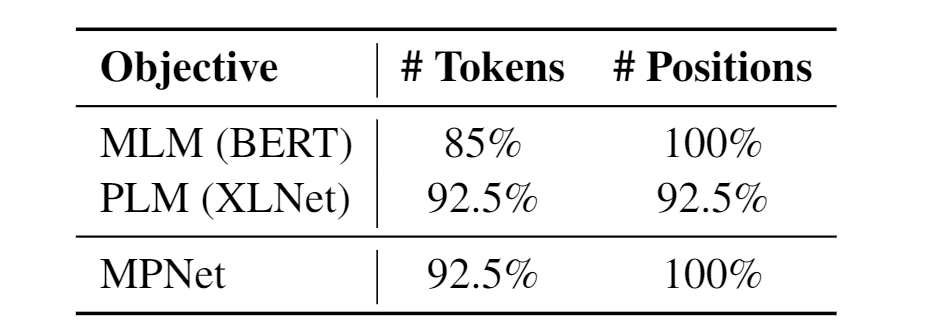
表 1 :不同预训练目标的信息利用率
接下来我们通过例子进行分析 MPNet 如何解决 MLM 不能建模预测单词的依赖问题,以及 PLM 不能看到整个句子位置信息的问题。假设我们的输入序列是[The,task,is,sentence,classification],而我们需要预测最后两个单词[sentence,classification]。那么 MLM、PLM 和 MPNet 的建模分解如表2所示。MLM 独立预测 sentence 和 classification 两个词,没法建模它们之间的依赖关系,有可能导致第二个词 classification 预测为 answering,就好像这两个词是去预测 question answering 一样。PLM 在预测 sentence 和 classification 两个词的时候没法观察到全局的位置信息,那么 PLM 在建模的时候有可能按照 [sentence, pair, classification] 三个单词的方向去建模。而 MPNet 能看到整句的位置信息,知道需要预测两个单词的答案,以及能依赖前面的单词进行预测,从而更好的往 [sentence, classification] 方向进行建模。

表 2:MLM、PLM 和 MPNet 的建模分解示例
我们在实验中采用 BERT-base 的模型配置,由12层 Transformer 构成,隐层大小为768,整个模型大约 110M 参数。我们在 160GB 语言数据上进行预训练,采用和 RoBERTa 相同的优化参数。MPNet 在 GLUE(表3)、SQuAD(表4)、RACE 和 IMDB 等数据集上都取得了比 BERT、XLNet 和 RoBERTa(同为 BERT-base 配置)更好的性能。
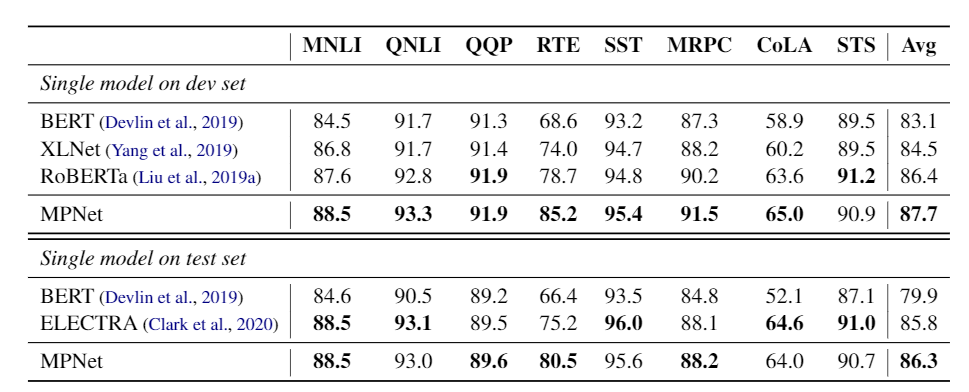
表 3:GLUE 的验证集和测试集结果
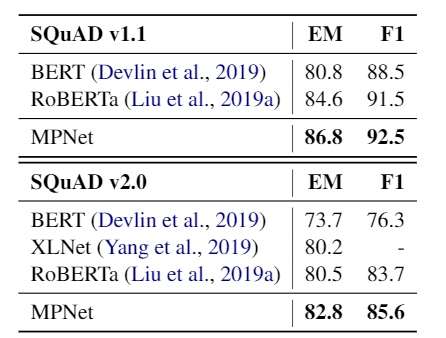
表 4:SQuAD 的验证集结果
为了能够进一步分析 MPNet 在获取全局位置和建模预测单词之间的依赖关系,以及验证 MPNet 中每个模块设计的有效性,我们做了一系列消融实验来对比分析,如表5所示。我们发现在 MPNet 的基础上去掉位置补偿(position compensation),去掉预测部分的随机排列(permutation)以及进一步去掉预测词之间的依赖关系(output dependency),在 GLUE 和 SQuAD 任务上都会导致明显的模型精度损失,这也验证了 MPNet 在获取全局位置信息和建模预测词之间依赖上的有效性。
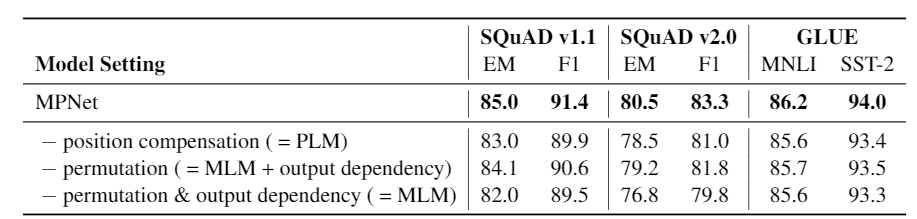
表5:消融实验
从表5我们还能发现以下几个现象:1)PLM 相比 MLM 的确取得了不错的效果提升;2)PLM 没有完全解决 MLM 的问题,因为从表中可以看到直接在 MLM 中引入预测词之间的依赖(MLM + output dependency)比 PLM 的效果更好;3)PLM 在解决 MLM 的预测词之间依赖问题的同时,丢掉了 MLM 中的句子全局位置信息。因此,MPNet 通过吸收 MLM和 PLM 的优点,规避各自的问题,取得了更高的精度。相比先前的预训练模型 BERT、XLNet 以及 RoBERTa,在相同的模型配置下,MPNet 在对比的数据集上都取了显著的效果提升。
我们接下来会在更大规模的模型配置下预训练 MPNet,并将 MPNet 应用到更多的自然语言理解任务上。目前论文、代码以及预训练模型都已开源:
论文链接:
https://arxiv.org/pdf/2004.09297.pdf
代码和模型链接:
https://github.com/microsoft/MPNet
微软亚洲研究院机器学习组的研究员们一直致力于预训练模型的研究,之前的研究工作包括:
[1] 面向自然语言生成任务的预训练模型 MASS
MASS: Masked Sequence to Sequence Pre-training for Language Generation
https://arxiv.org/pdf/1905.02450.pdf
[2] 通过堆叠加速BERT模型训练的 StackingBERT
Efficient Training of BERT by Progressively Stacking
https://proceedings.mlr.press/v97/gong19a/gong19a.pdf
[3] 预训练和微调两阶段蒸馏框架 LightPAFF
LightPAFF: A Two-Stage Distillation Framework for Pre-training and Fine-tuning
https://openreview.net/pdf?id=B1xv9pEKDS
我们还正在开展一系列的预训练模型研究工作,包括如何构建更快更轻量的预训练模型,敬请期待!
本文作者:宋恺涛、谭旭、秦涛、陆建峰、刘铁岩
你也许还想看:


感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




