斯坦福李飞飞新作登 PNAS:AI 与人类互动才能提高智能水平
![]()
来源:AI科技评论
本文为约4370字,建议阅读11分钟
本文介绍
了斯坦福大学计算机系的 Ranjay Krishna、Donsuk Lee、李飞飞、Michael Bernstein 提出了的一种新的研究框架:社会化人工智能。

![]()
人类从与他人的互动中学习,而目前的人工智能却常常只能在与社会隔离的环境中学习。所以当我们把一个智能体放到真实世界中时,它会不可避免地在遇到大量新的数据,无法应对不断变化的新需求。
如何将智能体从只有一堆书的房间里“解放”出来,让它在广阔的社会情境中学习,是一个新的挑战。
最近,斯坦福大学计算机系的 Ranjay Krishna、Donsuk Lee、李飞飞、Michael Bernstein 等人针对此问题提出了一种新的研究框架:
社会化人工智能
(socially situated AI),即智能体通过在现实社会环境中与人的持续互动来学习。论文“Socially situated artificial intelligence enables learning from human interaction”已发表在美国科学院院刊(PNAS)上。
![]()
论文地址:https://www.pnas.org/doi/epdf/10.1073/pnas.2115730119
在这项工作中,研究团队将社会化 AI 形式化为一个强化学习的过程,即智能体通过从社会互动中获取的奖励来学习识别有信息量的问题。在一个视觉问答任务的测试中,与其他智能体相比,社会化智能体识别新视觉信息的性能提高了 112%。
01. 社会化 AI 的强化学习框架
目前,在迭代扩展模型能力时,主动学习是最常用的一个框架。它的目标是优化一系列标注请求以获取新的数据,并将新数据将用于以尽可能少的请求来提高模型的性能。
主动学习已经被形式化为强化学习的过程,其中,真正的人类角色被移除,只假设存在一个能为所有请求提供标签的“预言机”。
尽管纯粹的主动学习方法也可以通过社会环境中的互动来收集新数据,但从用户角度看,他们并不原意充当“预言机”的角色来做重复提供标签的劳动,这就打破了主动学习的基本假设。
所以,我们必须探索智能体真正与人交互的学习方法。要开发社会化的 AI,智能体不仅要收集数据来学习新概念,还要学习
如何与人互动来收集数据
。
而且,智能体必须要在
交互学习
(interacting to learn)和
学习交互
(learning to interact)这两个目标之间进行权衡。这非常具有挑战性,因为智能体要遍历的可能交互空间是巨大的,只有一部分社会交互空间是有用的,并且信息交互空间还会随着智能体的学习进程而不断变化。
在强化学习中,我们将可能的交互形式化为行动空间,将反馈形式化为奖励,需要数亿次交互才能获得具有信息量和亲社会的交互的子空间,这让很多研究人员望而却步。所以,目前从与人类交互中学习的方法,通常只局限于人工标注或者小的工作空间(如只有几十个动作的游戏和仿真环境)。
为此,研究团队将社会化的 AI 形式化为一个迭代强化学习问题。
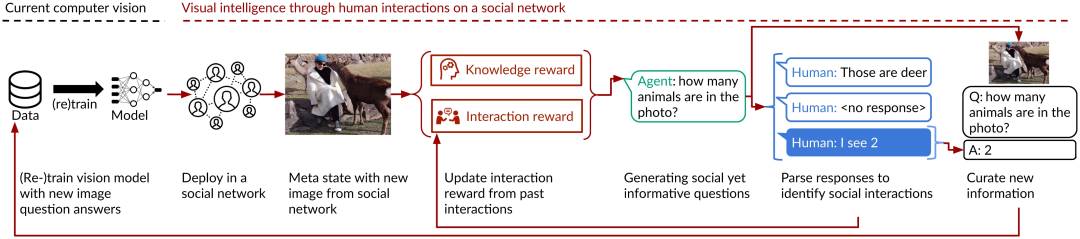
![]()
图注:社会化 AI 的强化学习框架
其框架描述如下:
一个智能体被放置在社会环境 E=(S,A,P,P0) 当中,它的目标是收集数据,以尽可能少的交互来优化模型的性能;
S 是环境状态,如对话智能体的对话历史,或机器人智能体在三维世界中当前位置;
A 是智能体可以发起的与人交互的可能空间,如对话智能体可以询问的一组语句,或机器人智能体可以执行的一组动作。
P:S × A → S 是过渡动力学(transition dynamics),如使用过渡函数(transition function)编码人们对智能体历史行为的反应以及环境的变化。
最后,P0 是初始状态分布的概率测度。
总结而言,这样一个迭代强化学习的过程包括三个重要的方面:
改进底层模型、发现社会规范、更新交互策略
。它们贯穿着智能体的整个生命周期。
其中,智能体在人们可能会或可能不会做出信息回应的社会环境中与人进行互动,从而改进底层模型。只有当人的回应包含对智能体有用的新信息时,回应才是有用的。因此,智能体必须与环境中数十万人的单次交互,从中选择能够引发对模型有用的新概念的社会互动。
为了平衡智能体的交互学习和学习交互两个目标,我们可以引入
知识奖励
(knowledge reward)来引导智能体进行交互以获得有用的新概念;同时采用交互奖励(interaction reward)来引导智能体进行符合环境中社会规范的交互。
在使用新概念改进模型的基础上,智能体会更新其策略,开始学习如何就人们有兴趣回应的新概念提出问题,来改进自身性能还比较差的部分。
02. 从问答互动中改进视觉模型
为了验证社会化 AI 框架在计算机视觉中的实用性,作者在照片
共享社交网络应用 Instagram 上部署了一个社会化智能体,它向人们提出自然语言问题,并从人的回应中提取答案,收集视觉知识。
这种使用自然语言来获取视觉知识的方法,可以用来测试很多计算机视觉识别任务,如对象检测(“图像中有什么?”)、细粒度识别(“花瓶里是什么花?”)、属性分类(“这张桌子是用什么材料做的?”)、知识库推理(“这份食物是素食吗?”)和常识推理(“这张照片是在冬天拍摄的吗?”)等等。
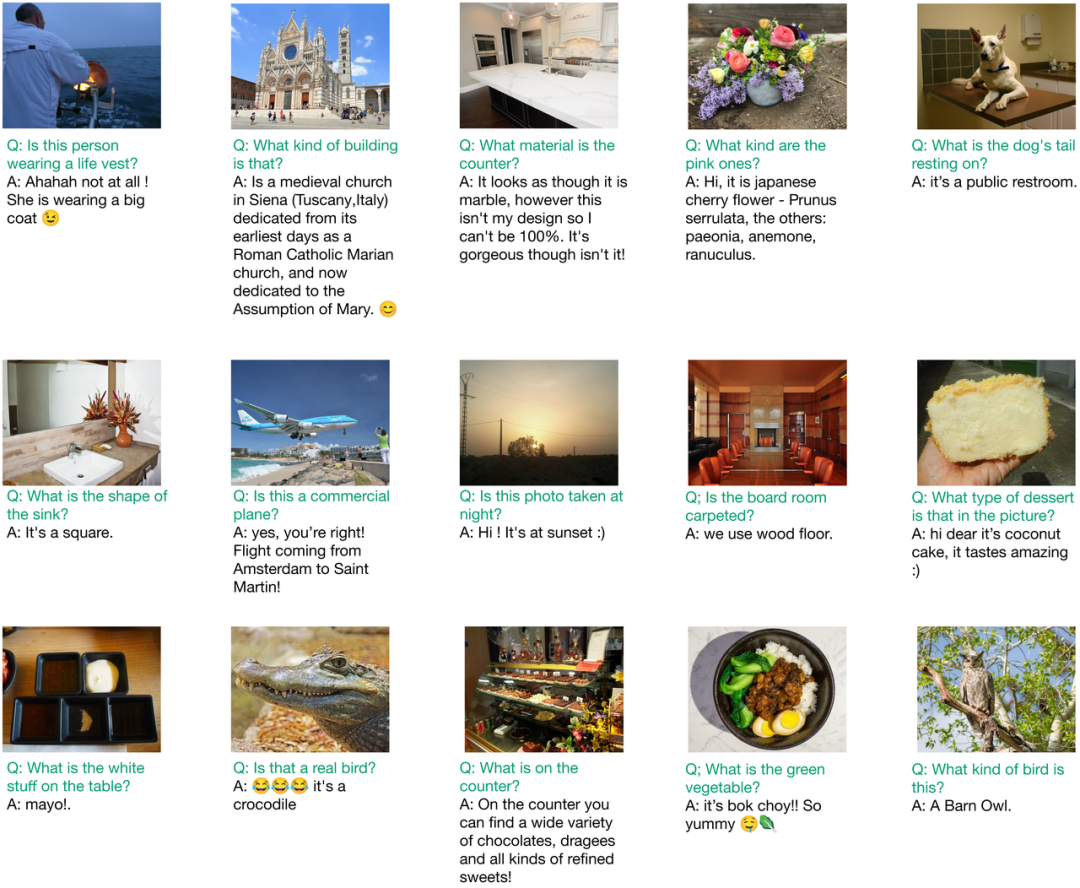
在这项工作中,研究团队设计了一个计算机视觉问答模型,其输入是一张图像和相应的自然语言问题,输出是一个自然语言答案。智能体提出的问题非常多样,如下图。
![]()
图注:社会化智能体在社交媒体上发起的互动示例
智能体的目标是从与人的交互中获得数据,提高模型识别视觉概念的能力。为了达到这个目标,智能体需要一些“奖励”。如上文所述的框架,作者引入了知识奖励和互动奖励。
知识奖励衡量模型的在识别任务中的确定性。在刚开始,识别模型不知道如何识别任何概念,但随着看到的特定概念的增长,它会对自己的判断更加肯定。比如,如果人们帮助智能体将图像中的动物识别为鹿,那么它的不确定性就会减少。
交互奖励则引导智能体的行为符合社区规范。如在社交网络中,人们更喜欢回答较短的问题、提供事实知识以及回避含糊不清的问题。所以智能体的每一次交互都会被标记为积极(产生了新信息)或消极(未获得新信息),从而被不断训练成亲社会的。
最后,是如何寻找有用的语言交互问题。这是一个组合性的搜索问题。一种直接的方法可以将智能体的策略设计成一个从图像到提问的生成模型。随着模型性能的提升,信息交互的空间会不断变化,因此组合搜索过程需要反复重复。
为了使搜索过程更易于处理,作者使用现有的信息最大化变分自动编码器来学习现实中人与人交互的表示:通过重新配置策略将输入图像映射到表示空间中,并通过设计解码器从表示空间映射到单词序列。
03. 更少的交互,更高的识别准确率
在社会化 AI 的框架中,智能体同时有两个目标:一个
发起社交互动
,让人们根据信息数据作出回应;另一个是通过
收集有用的数据来改进其基础模型
。
这两个目标也成了智能体的评估指标。
首先,为了评估该智能体获得回应的能力,我们需要测量对它所提问题的信息回应率(Informative Response Rate),也就是它收到问题答案(即获得有用的交互)的交互百分比。较高的信息回应率意味着对智能体对隐性社会规范有更好的理解,而较低的信息回应率则意味着人们不给予回应,这会减慢甚至停止智能体的学习进程。
其次,为了评估智能体识别新的视觉概念的能力,研究人员使用由 Amazon Mechanical Turk 的注释器收集的 50104 个社交媒体图像、问题和答案,构成测试集,来评估视觉识别模型的准确率。
此外,为了对照和比较使用社会化 AI 框架所涉及的社会化智能体与其他智能体的区别,作者还部署了一个仅使用交互奖励的人类偏好智能体,一个仅使用知识奖励的主动学习智能体,以及一个基线智能体。
这个基线智能体不使用预训练的交互表示作为动作空间,它允许微调解码器的参数,使用整个组合词汇空间作为动作空间。而且,它同时使用交互奖励和知识奖励,并额外添加了语言建模奖励,以鼓励它生成语法正确的语言。
所有这些智能体都使用近端策略梯度(proximal policy gradients)进行训练,而且都使用相同数量的数据进行初始化,并具有相同的策略和解码器架构。
实验进行了 8 个月,每个智能体可以发起至少 20 万次交互。当它们与人交互、并收集新的视觉知识时,信息回应率和识别准确率的变化结果表明,社会化智能体整体上优于其他智能体。
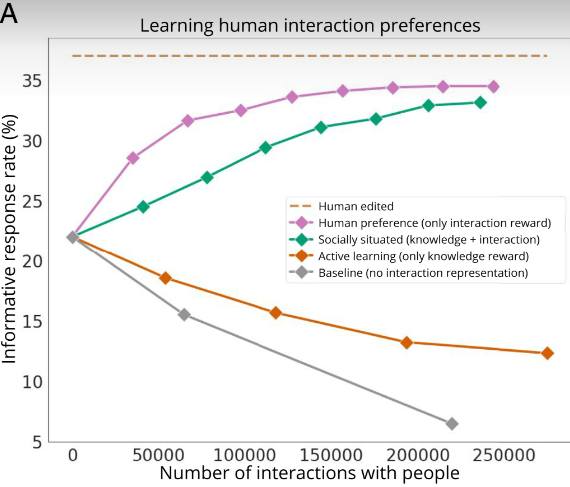
信息回应率更高
如下图,在 236000 次互动中,社会化智能体的信息回应率从最初的 22% 提高到 33%,相对提高了 50%。相比之下,主动学习和基线智能体在每次迭代后获得的回应较少,分别为 6% 和 12.3%。
![]()
图注:信息回应率与发起的交互次数的关系。社会化智能体(绿色)和人类偏好的智能体(紫色)都使用交互奖励,在交互次数提高的同时信息回应率也更高;其他智能体的信息回应率随着交互次数的增加而下降,这是因为交互会阻碍它们的数据采集。
具体来看,基线智能体在尽力探索所有可能的语言交互组合空间时,不可避免地会产生不连贯的问题,这导致了回应率的下降,并产生一个恶性循环,从而无法识别有用的交互。回应率下降到 6% 以后,研究人员将其终止。
主动学习智能体的弊端则在于它会提出更长、更难的问题,无法引起热人们的兴趣。例如,要回答“这些工具是为左撇子还是右撇子设计的?”这个问题,还得知道有关特定工具的知识以及是否可以用任何一只手操作。
人类偏好智能体的回应率最高,但它的提问又太简单了。比如,它会问“这件衬衫是什么颜色的?”
可以看到,当前实验中智能体的最高回应率是 33%,那么这一数值还有多少上升空间呢?研究人员又进行了一项实验,聘请标注人员来人工编辑问题,以增加智能体获得回应的可能性。最终,智能体获得了 37% 的回应率,这代表了人类从既定社会环境中获得回应的平均能力。所以,智能体还有 4% 的社交能力提升空间。
识别准确率更高
再来看这些智能体在使用收集的数据来改进视觉模型方面表现如何。
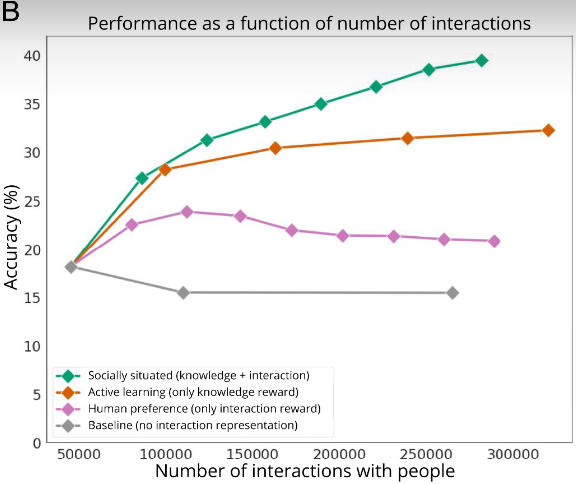
与其他智能体相比,社会化智能体能使用更少的交互来提高识别准确率。它在 236000 次交互中实现了 39.44% 的模型性能(下图 B),从中收到了 70000 条回应(下图 C)。
![]()
图注:视觉模型性能与智能体发起的交互次数之间的关系。社会化智能体和主动学习智能体(橙色)都使用知识奖励来收集有用数据,但主动学习智能体本身缺少交互,要达到同样性能,它需要更多交互。
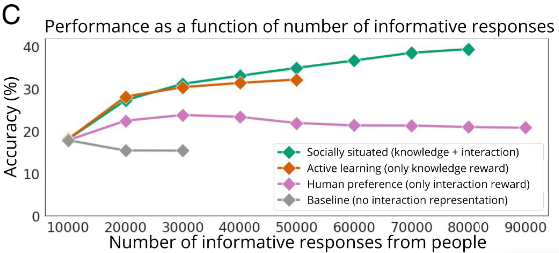
![]()
图注:视觉模型性能与来自人的回应数量的关系。社会化智能体需要权衡知识与交互两种奖励,其准确率的提高与主动学习智能体相当,而后者只能最大化知识奖励。
相比之下,主动学习智能体共发起了 274893 次交互,但仅收到 30000 条回应,并且性能开始饱和,达到 31.4%,回应率也下降到 12.3%。
这再次表明,在某些社会环境中,
纯粹的主动学习方法是不可行的
。
而人类偏好智能体每次交互虽然都会收到更多回应,但它收集的数据并没有改善视觉模型。因为它倾向于收集一小部分问题的答案,因此它的底层视觉模型开始过拟合,最后只生成与时间相关或与颜色相关的输出。
基线智能体也暴露出它的问题,即不连贯,收集的数据也没有用。
获取比传统数据集更多的新信息
最后,研究团队对使用社会化智能体收集的数据进行的训练与使用现有数据集中的数据进行的训练作了比较。
结果表明,前者的识别准确率远高于后者,这说明社会化智能体可以获得传统数据集中不存在的新信息。
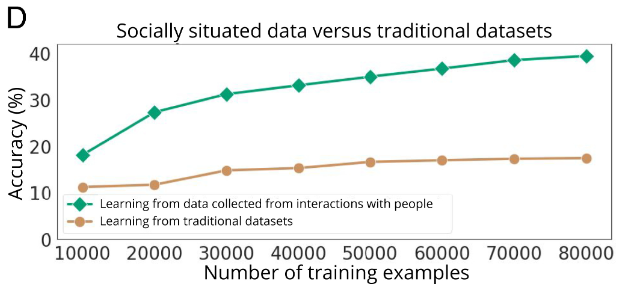
![]()
图注:从社会互动中收集的数据与从传统数据集中的数据进行训练的准确率比较。使用来自现有数据集的相同数量的标签进行训练,仅将准确度从 11.24% 提高到 17.45%;而使用来自社会互动的数据进行训练时,准确度从 18.13% 提高到 39.44%。
总结一下,这项研究的重要创新之处在于它提出了一个智能体从与人的交互中学习的形式框架,并通过使用语言交互的视觉模型验证了该框架的实用性。作者相信,这项工作将有助于更广泛的交互式智能体的研究。


论文地址:https://www.pnas.org/doi/epdf/10.1073/pnas.2115730119
图注:视觉模型性能与来自人的回应数量的关系。社会化智能体需要权衡知识与交互两种奖励,其准确率的提高与主动学习智能体相当,而后者只能最大化知识奖励。

登录查看更多
相关内容

Arxiv
15+阅读 · 2020年3月31日
Arxiv
23+阅读 · 2019年11月5日



相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2020年3月31日
Arxiv
23+阅读 · 2019年11月5日