李飞飞新作登PNAS!AI与人类互动23万次,智能水平提高112%
![]()
新智元报道

新智元报道
【新智元导读】与人类互动23万次后,AI的视觉识别能力提高了112%。
社会化人工智能(socially situated AI),即智能体通过在现实社会环境中与人的持续互动来学习。

社会化 AI 的强化学习框架
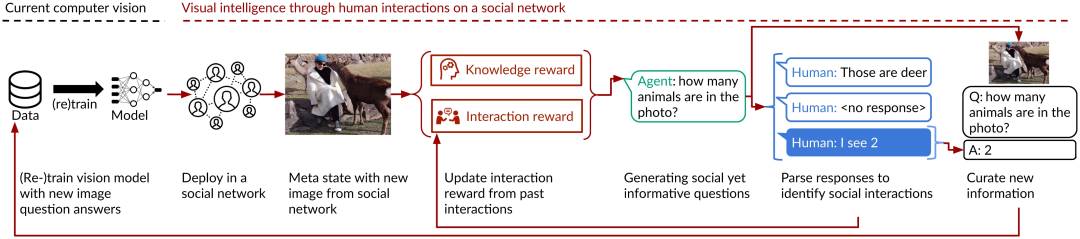
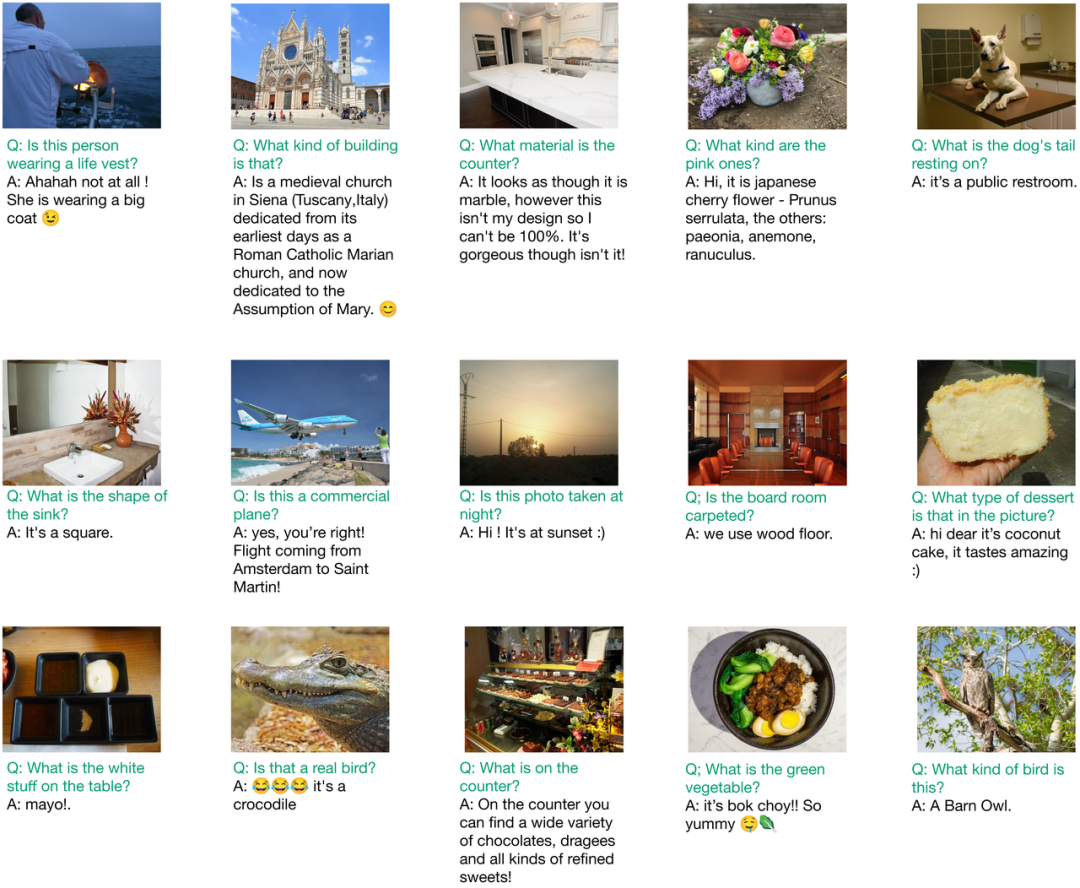
从问答互动中改进视觉模型
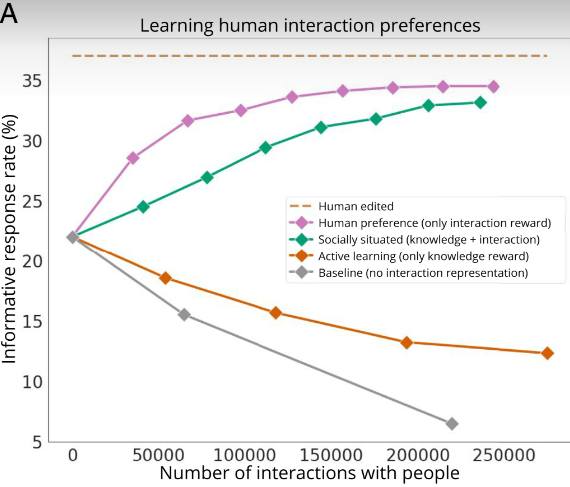
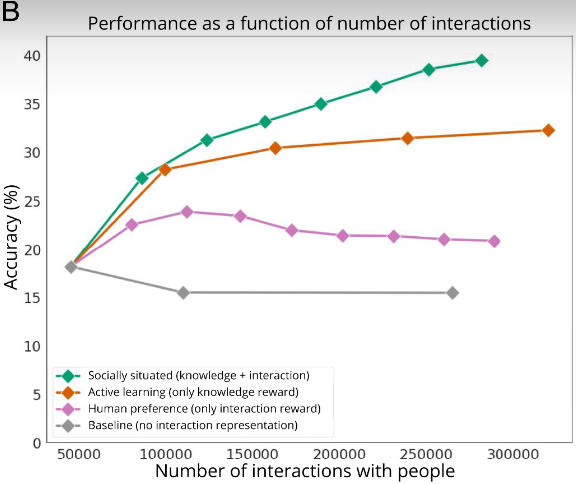
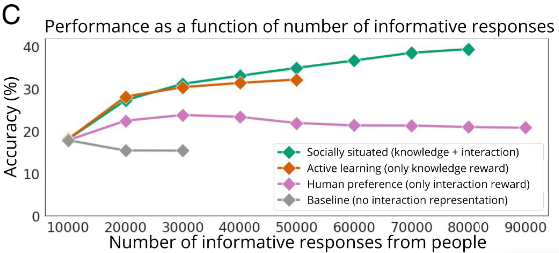
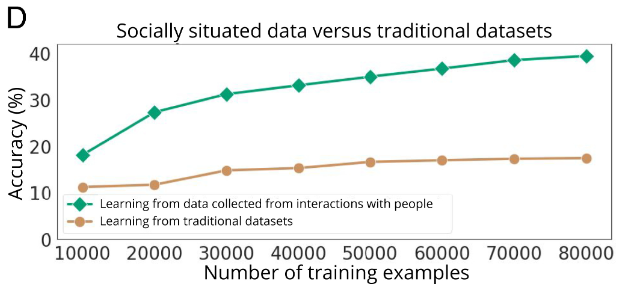
更少的交互,更高的识别准确率


登录查看更多
相关内容

专知会员服务
28+阅读 · 2019年10月23日


相关VIP内容
专知会员服务
28+阅读 · 2019年10月23日
相关资讯