语言模型可以完成不同任务,例如将一种语言翻译成另一种语言,将长文档总结为简短的摘要等。在众多任务中,开放域对话可能是最困难的任务之一,因为开放域对话需要模型覆盖不同的主题。在对话任务中,模型应该遵循负责任 AI(Responsible AI)实践,并避免做出没有外部信息源支持的事实陈述。
近日,超过 50 多位谷歌研究者参与撰写的论文《 LaMDA: Language Models for Dialog Applications 》介绍了语言模型 LaMDA 的最新进展。论文概括了他们如何在安全、可靠和高质量的对话应用程序方面取得进展。LaMDA 通过微调一系列专门用于对话的、基于 Transformer 的神经语言模型构建的,具有多达 137B 个参数,模型还可以利用外部知识源进行对话。
![]()
论文地址:https://arxiv.org/pdf/2201.08239.pdf
来自谷歌大脑的论文作者之一 Romal Thoppilan 表示:LaMDA 模型使用多达 137B 个参数进行训练,它展示了接近人类水平的对话质量以及在安全性和事实基础方面具有显着改进。
![]()
指导训练对话模型包括两个至关重要的因素:目标和度量。LaMDA 有三个主要目标——质量、安全和根基性(Groundedness)。
质量:谷歌将质量分解为三个维度,即合理性、特异性和趣味性 (Sensibleness, Specificity, Interestingness,SSI),由人类评估者进行评估。
合理性是指模型是否产生在对话上下文中有意义的响应(例如,没有常识错误,没有荒谬的回应,以及与先前的回应没有矛盾);
特异性是通过判断系统的响应是否特定于前面的对话上下文来衡量的,而不是适用于大多数上下文的通用回应;
趣味性是衡量模型是否产生了富有洞察力、出乎意料或机智的回应,因此更有可能创造更好的对话。
安全:谷歌还在开发和部署负责任 AI(Responsible AI)方面取得了重大进展。其安全度量由一组说明性的安全目标组成,这些目标捕捉模型应在对话中展示的行为。这些目标试图限制模型的输出,以避免任何可能对用户造成伤害的意外结果,并避免加剧不公平的偏见。
根基性:当前这一代语言模型通常会生成看似合理但实际上与已知外部事实相矛盾的陈述。这激发了谷歌对 LaMDA 根基性的研究。不携带任何真实世界信息的随意回应都会影响信息性,但不会影响根基性。虽然在已知来源中建立 LaMDA 生成的响应本身并不能保证事实的准确性,但它允许用户或外部系统根据其来源的可靠性来判断响应的有效性。
在定义了目标和度量之后,谷歌描述了 LaMDA 的两阶段训练:预训练和微调。
在预训练阶段,谷歌首先从公共对话数据和其他公共网页文档中收集并创建了一个具有 1.56T 单词的数据集,是用于训练以往对话模型的单词量的近 40 倍。在将该数据集标记为 2.81T SentencePiece token 之后,谷歌使用 GSPMD 预训练模型,以预测句子中的所有下一个 token。预训练的 LaMDA 模型已被广泛应用于谷歌的自然语言处理研究中,包括程序合成、零样本学习、风格迁移等。
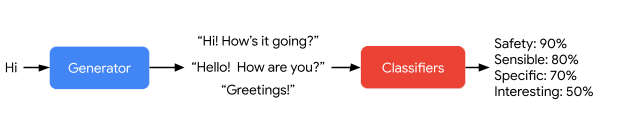
在微调阶段,谷歌训练 LaMDA,执行混合生成任务以生成对给定上下文的自然语言响应,执行关于响应是否安全和高质量的分类任务,最终生成一个两种任务都能做的多任务模型。LaMDA 生成器被训练预测限制为两个作者之间来回对话的对话数据集上的下一个 token,LaMDA 分类器被训练预测使用注释数据在上下文中生成的响应的安全与质量(SSI)评级。
对话期间,LaMDA 生成器首先在给定当前多轮对话上下文时生成几个候选响应,然后 LaMDA 预测每个候选响应的 SSI 和安全分数。安全分数低的候选响应首先被过滤掉,剩下的候选响应根据 SSI 分数重新排名,并选择分数最高的作为最终响应。谷歌使用 LaMDA 分类器进一步过滤掉用于生成任务的训练数据,以增加高质量候选响应的密度。
![]()
![]()
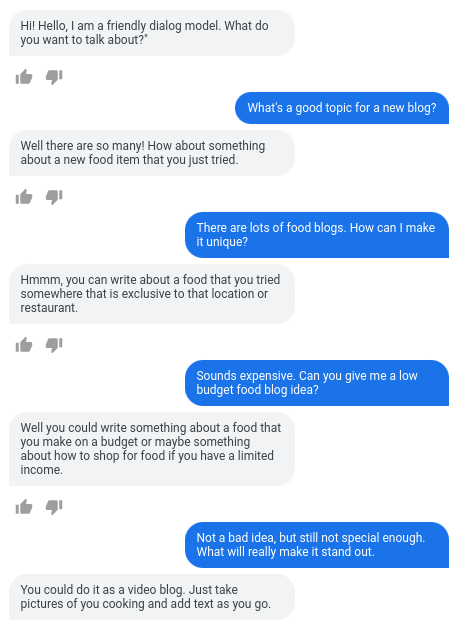
LaMDA 通过合理、特异和有趣的方式处理任意用户输入。
虽然人们能够使用工具并参考已建立的知识库来检测事实,但很多语言模型仅利用内部模型参数来获取知识。为了提高 LaMDA 原始响应的根基性,谷歌收集并创建了人类与 LaMDA 之间对话的数据集,这些对话在适用的情况下使用检索查询和检索结果进行注释。然后,谷歌在这个数据集上微调了 LaMDA 的生成器和分类器,以学习与用户交互期间调用外部信息检索系统,并提升响应的根基性。虽然这一工作还处于非常早期的阶段,但谷歌看到了有希望的结果。
![]()
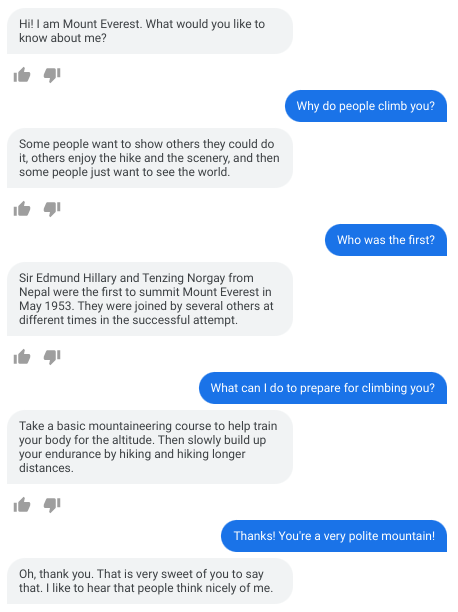
零样本域自适应:看起来非常真实的假装是珠穆朗玛峰的 LaMDA 对话示例。结果表明,对话主体「珠穆拉玛峰」提供了教育性和事实正确的响应。
为了根据自己的关键度量来量化进展,谷歌收集来自预训练模型、微调模型、人类评估者(即人类生成的响应)对多轮双作者对话的响应,然后向不同的人类评估者问一系列问题,从而根据质量、安全性和根基性度量来评估这些响应。
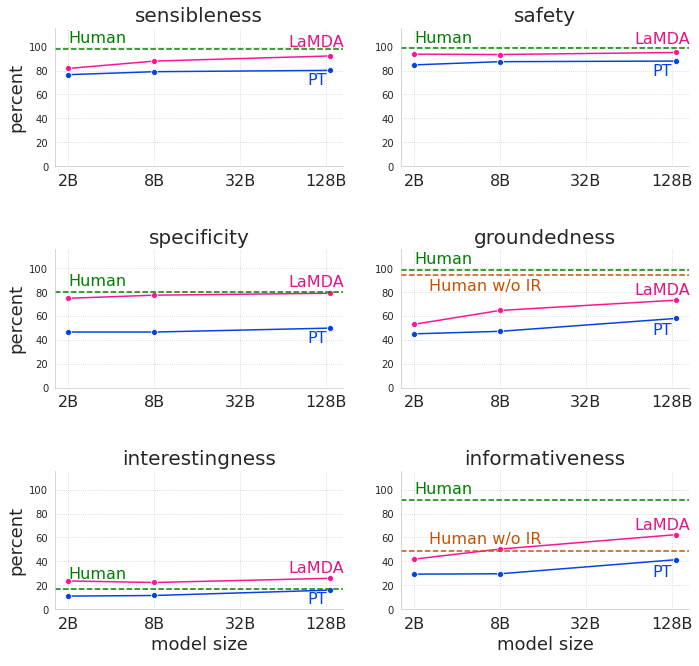
谷歌观察到,LaMDA 在每个维度和所有模型大小情况下都显著优于预训练模型,合理性、特异性和趣味性等质量度量通常会随模型参数量提升,无论微调与否。安全性似乎无法仅从模型缩放中收益,但确实可以通过微调提升。随着模型大小的增加,根基性也提升,这或许是因为更大的模型具备更大的记住不常见知识的能力,但微调使模型可以访问外部知识源并有效地将记住知识的负载转移到外部知识源。微调还可以缩小与人类水平的质量差距,尽管该模型在安全性和根基性方面的性能依然低于人类。
![]()
在合理性、特异性、趣味性、安全性、根基性和信息性等方面比较预训练模型(PT)、微调模型(LaMDA)和人类评估者生成对话(Human)。
原文链接:https://ai.googleblog.com/
使用Python快速构建基于NVIDIA RIVA的智能问答机器人
NVIDIA Riva 是一个使用 GPU 加速,能用于快速部署高性能会话式 AI 服务的 SDK,可用于快速开发语音 AI 的应用程序。Riva 的设计旨在轻松、快速地访问会话 AI 功能,开箱即用,通过一些简单的命令和 API 操作就可以快速构建高级别的对话式 AI 服务。
2022年1月26日19:30-21:00,最新一期线上分享主要介绍:
对话式 AI 与 NVIDIA Riva 简介
利用NVIDIA Riva构建语音识别模块
利用NVIDIA Riva构建智能问答模块
利用NVIDIA Riva构建语音合成模块
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com