随机过程在数据科学和深度学习中有哪些应用?

(图源:https://www.europeanwomeninmaths.org/etfd/)
翻 译 | had_in(电子科技大学)
“The only simple truth is that there is nothing simple in this complex universe. Everything relates. Everything connects” — Johnny Rich, The Human Script
介绍
机器学习的主要应用之一是对随机过程建模。机器学习中一些随机过程的例子如下:
泊松过程:用于处理等待时间以及队列。
随机漫步和布朗运动过程:用于交易算法。
马尔可夫决策过程:常用于计算生物学和强化学习。
高斯过程:用于回归和优化问题(如,超参数调优和自动机器学习)。
自回归和移动平均过程:用于时间序列分析(如,ARIMA模型)。
在本文中,我将简要地向您介绍这些随机过程。
历史背景
随机过程是我们日常生活的一部分。随机过程之所以如此特殊,是因为随机过程依赖于模型的初始条件。在上个世纪,许多数学家,如庞加莱,洛伦兹和图灵都被这个话题所吸引。
如今,这种行为被称为确定性混沌,它与真正的随机性有着截然不同的范围界限。
由于爱德华·诺顿·洛伦兹的贡献(https://en.wikipedia.org/wiki/Edward_Norton_Lorenz),混沌系统的研究在1963年取得了突破性进展。当时,洛伦兹正在研究如何改进天气预报。洛伦兹在他的分析中注意到,即使是大气中的微小扰动也能引起气候变化。
洛伦兹用来描述这种状态的一个著名的短语是:
“A butterfly flapping its wings in Brazil can produce a tornado in Texas”(在巴西,一只蝴蝶扇动翅膀就能在德克萨斯州制造龙卷风 ) — Edward Norton Lorenz(爱德华·诺顿·洛伦兹)
这就是为什么今天的混沌理论有时被称为“蝴蝶效应”。
分形学
一个简单的混沌系统的例子是分形(如图所示)。分形是在不同尺度上不断重复的一种模式。由于分形的缩放方式,分形不同于其他类型的几何图形。
分形是递归驱动系统,能够捕获混沌行为。在现实生活中,分形的例子有:树、河、云、贝壳等。

图1:MC. Escher, Smaller and Smaller [1]
在艺术领域有很多自相似的图形。毫无疑问, MC. Escher是最著名的艺术家之一,他的作品灵感来自数学。事实上,在他的画中反复出现各种不可能的物体,如彭罗斯三角形和莫比乌斯带。在"Smaller and Smaller"中,他也反复使用了自相似性(图1)。除了蜥蜴的外环,画中的内部图案也是自相似性的。每重复一次,它就包含一个有一半尺度的复制图案。
确定性和随机性过程
有两种主要的随机过程:确定性和随机性。
在确定性过程中,如果我们知道一系列事件的初始条件(起始点),我们就可以预测该序列的下一步。相反,在随机过程中,如果我们知道初始条件,我们不能完全确定接下来的步骤是什么。这是因为这个过程可能会以许多不同的方式演化。
在确定性过程中,所有后续步骤的概率都为1。另一方面,随机性随机过程的情况则不然。
任何完全随机的东西对我们都没有任何用处,除非我们能识别出其中的模式。在随机过程中,每个单独的事件都是随机的,尽管可以识别出连接这些事件的隐藏模式。这样,我们的随机过程就被揭开了神秘的面纱,我们就能够对未来的事件做出准确的预测。
为了用统计学的术语来描述随机过程,我们可以给出以下定义:
观测值:一次试验的结果。
总体:所有可能的观测值,可以记为一个试验。
样本: 从独立试验中收集的一组结果。
例如,抛一枚均匀硬币是一个随机过程,但由于大数定律,我们知道,如果进行大量的试验,我们将得到大约相同数量的正面和反面。
大数定律指出:
“随着样本规模的增大,样本的均值将更接近总体的均值或期望值。因此,当样本容量趋于无穷时,样本均值收敛于总体均值。重要的一点是样本中的观测必须是相互独立的。”
--Jason Brownlee
随机过程的例子有股票市场和医学数据,如血压和脑电图分析。
泊松过程
泊松过程用于对一系列离散事件建模,在这些事件中,我们知道不同事件发生的平均时间,但我们不知道这些事件确切在何时发生。
如果一个随机过程能够满足以下条件,则可以认为它属于泊松过程:
事件彼此独立(如果一个事件发生,并不会影响另一个事件发生的概率)。
两个事件不能同时发生。
事件的平均发生比率是恒定的。
让我们以停电为例。电力供应商可能会宣传平均每10个月就会断电一次,但我们不能准确地说出下一次断电的时间。例如,如果发生了严重问题,可能会连续停电2-3天(如,让公司需要对电源供应做一些调整),以便在接下来的两天继续使用。
因此,对于这种类型的随机过程,我们可以相当确定事件之间的平均时间,但它们是在随机的间隔时间内发生的。
由泊松过程,我们可以得到一个泊松分布,它可以用来推导出不同事件发生之间的等待时间的概率,或者一个时间段内可能发生事件的数量。
泊松分布可以使用下面的公式来建模(图2),其中k表示一个时期内可能发生的事件的预期数量。
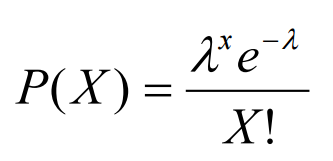
图2:泊松分布公式[3]
一些可以使用泊松过程模拟的现象的例子是原子的放射性衰变和股票市场分析。
随机漫步和布朗运动过程
随机漫步是可以在随机方向上移动的任意离散步的序列(长度总是相同)(图3)。随机漫步可以发生在任何维度空间中(如:1D,2D,nD)。

图3:高维空间[4]中的随机漫步
现在我将用一维空间(数轴)向您介绍随机漫步,这里解释的这些概念也适用于更高维度。
我们假设我们在一个公园里,我们看到一只狗在寻找食物。它目前在数轴上的位置为0,它向左或向右移动找到食物的概率相等(图4)。
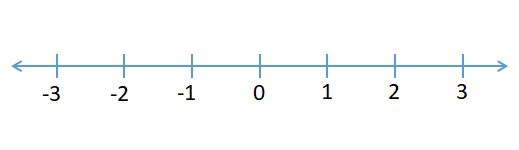
图4:数轴[5]
现在,如果我们想知道在N步之后狗的位置是多少,我们可以再次利用大数定律。利用这个定律,我们会发现当N趋于无穷时,我们的狗可能会回到它的起点。无论如何,此时这种情况并没有多大用处。
因此,我们可以尝试使用均方根(RMS)作为距离度量(首先对所有值求平方,然后计算它们的平均值,最后对结果求平方根)。这样,所有的负数都变成正数,平均值不再等于零。
在这个例子中,使用RMS我们会发现,如果我们的狗走了100步,它平均会从原点移动10步(√100 = 10)。
如前面所述,随机漫步用于描述离散时间过程。相反,布朗运动可以用来描述连续时间的随机漫步。
隐马尔科夫模型
隐马尔可夫模型都是关于认识序列信号的。它们在数据科学领域有大量应用,例如:
计算生物学(https://towardsdatascience.com/computational-biology-fca101e20412)。
写作/语音识别。
自然语言处理(NLP)。
强化学习
HMMs是一种概率图形模型,用于从一组可观察状态预测隐藏(未知)状态序列。
这类模型遵循马尔可夫过程假设:
“鉴于我们知道现在,所以未来是独立于过去的"
因此,在处理隐马尔可夫模型时,我们只需要知道我们的当前状态,以便预测下一个状态(我们不需要任何关于前一个状态的信息)。
要使用HMMs进行预测,我们只需要计算隐藏状态的联合概率,然后选择产生最高概率(最有可能发生)的序列。
为了计算联合概率,我们需要以下三种信息:
初始状态:任意一个隐藏状态下开始序列的初始概率。
转移概率:从一个隐藏状态转移到另一个隐藏状态的概率。
发射概率:从隐藏状态移动到观测状态的概率
举个简单的例子,假设我们正试图根据一群人的穿着来预测明天的天气是什么(图5)。
在这种例子中,不同类型的天气将成为我们的隐藏状态。晴天,刮风和下雨)和穿的衣服类型将是我们可以观察到的状态(如,t恤,长裤和夹克)。初始状态是这个序列的起点。转换概率,表示的是从一种天气转换到另一种天气的可能性。最后,发射概率是根据前一天的天气,某人穿某件衣服的概率。
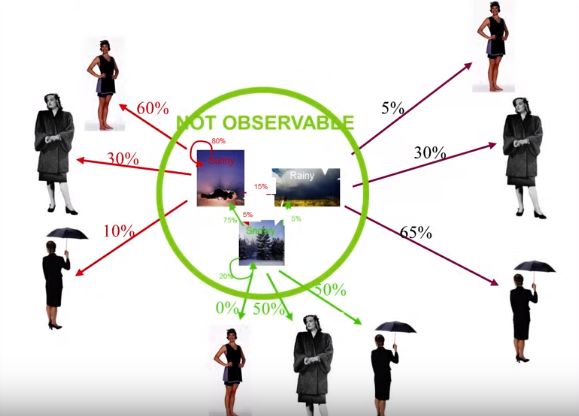
图5:隐马尔可夫模型示例[6]
使用隐马尔可夫模型的一个主要问题是,随着状态数的增加,概率和可能状态的数量呈指数增长。为了解决这个问题,可以使用维特比算法(https://web.stanford.edu/~jurafsky/slp3/A.pdf)。
如果您对使用HMMs和生物学中的Viterbi算法的实际代码示例感兴趣,可以在我的Github代码库中找到它(https://github.com/pierpaolo28/Artificial-Intelligence-Projects/blob/master/Computational%20Biology/Tutorials/Tutorial%202/Tutorial%202.ipynb)。
从机器学习的角度来看,观察值组成了我们的训练数据,隐藏状态的数量组成了我们要调优的超参数。
机器学习中HMMs最常见的应用之一是agent-based情景,如强化学习(图6)。

图6:强化学习[7]中的HMMs
高斯过程
高斯过程是一类完全依赖自协方差函数的平稳零均值随机过程。这类模型可用于回归和分类任务。
高斯过程最大的优点之一是,它们可以提供关于不确定性的估计,例如,给我们一个算法确定某个项是否属于某个类的确定性估计。
为了处理嵌入一定程度上的不确定性的情况,通常使用概率分布。
一个离散概率分布的简单例子是掷骰子。
想象一下,现在你的一个朋友挑战你掷骰子,你掷了50个trows。在掷骰子公平的情况下,我们期望6个面中每个面出现的概率相同(各为1/6)。如图7所示。
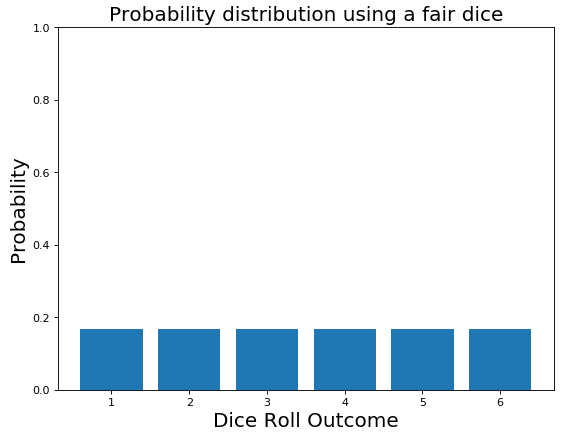
图7:掷骰子公平的概率分布
无论如何,你玩得越多,你就越可以看到到骰子总是落在相同的面上。此时,您开始考虑骰子可能是不公平的,因此您改变了关于概率分布的最初信念(图8)。
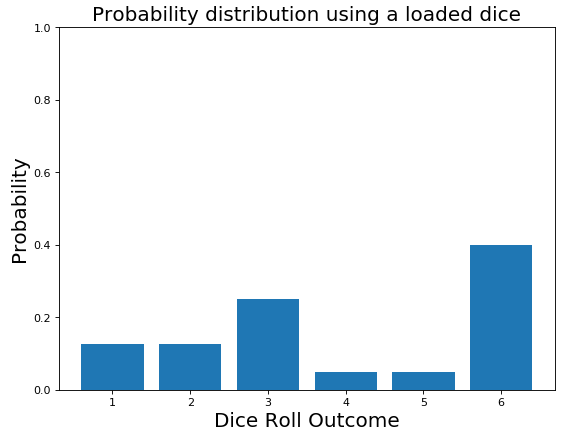
图8:不公平骰子的概率分布
这个过程被称为贝叶斯推理。
贝叶斯推理是我们在获得新证据的基础上更新自己对世界的认知的过程。
我们从一个先前的信念开始,一旦我们用全新的信息更新它,我们就构建了一个后验信念。这种推理同样适用于离散分布和连续分布。
因此,高斯过程允许我们描述概率分布,一旦我们收集到新的训练数据,我们就可以使用贝叶斯法则(图9)更新分布。
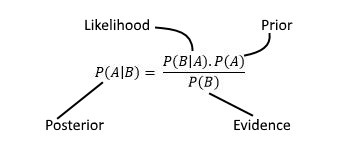
图9:贝叶斯法则[8]
自回归移动平均过程
自回归移动平均(ARMA)过程是一类非常重要的分析时间序列的随机过程。ARMA模型的特点是它们的自协方差函数只依赖于有限数量的未知参数(对于高斯过程是不可能的)。
缩略词ARMA可以分为两个主要部分:
自回归=模型利用了预先定义的滞后观测值与当前滞后观测值之间的联系。
移动平均=模型利用了残差与观测值之间的关系。
ARMA模型利用两个主要参数(p, q),分别为:
p = 滞后观测次数。
q = 移动平均窗口的大小。
ARMA过程假设一个时间序列在一个常数均值附近均匀波动。如果我们试图分析一个不遵循这种模式的时间序列,那么这个序列将需要被差分,直到分割后的序列具有平稳性。
这可以通过使用一个ARIMA模型来实现,如果你有兴趣了解更多,我写了一篇关于使用ARIMA进行股票市场分析的文章(https://towardsdatascience.com/stock-market-analysis-using-arima-8731ded2447a)。
谢谢阅读!
参考文献
[1] M C Escher, “Smaller and Smaller” — 1956.访问: https://www.etsy.com/listing/288848445/m-c-escher-print-escher-art-smaller-and
[2] 机器学习中大数定律的简要介绍。Machine Learning Mastery, Jason Brownlee. 访问: https://machinelearningmastery.com/a-gentle-introduction-to-the-law-of-large-numbers-in-machine-learning/
[3] 正态分布,二项分布,泊松分布 , Make Me Analyst. 访问: http://makemeanalyst.com/wp-content/uploads/2017/05/Poisson-Distribution-Formula.png
[4] 通用维基百科. Accessed at: https://commons.wikimedia.org/wiki/File:Random_walk_25000.gif
[5] 数轴是什么?Mathematics Monste. 访问: https://www.mathematics-monster.com/lessons/number_line.html
[6] 机器学习算法: SD (σ)- 贝叶斯算法. Sagi Shaier, Medium. 访问: https://towardsdatascience.com/ml-algorithms-one-sd-%CF%83-bayesian-algorithms-b59785da792a
[7] DeepMind的人工智能正在自学跑酷,结果非常令人惊讶。The Verge, James Vincent. 访问: https://www.theverge.com/tldr/2017/7/10/15946542/deepmind-parkour-agent-reinforcement-learning
[8] 为数据科学专业人员写的强大的贝叶斯定理介绍。KHYATI MAHENDRU, Analytics Vidhya. Accessed at: https://www.analyticsvidhya.com/blog/2019/06/introduction-powerful-bayes-theorem-data-science/
via https://towardsdatascience.com/stochastic-processes-analysis-f0a116999e4






