通俗易懂的Attention、Transformer、BERT原理详解

原创 · 作者 | TheHonestBob
学校 | 河北科技大学
研究方向 | 自然语言处理
一、写在前面
网上关于这部分内容的好文章数不胜数,都讲的特别的详细,而今天我写这篇博客的原因,一是为了加深对这部分知识的理解,二是希望博客内容能够更多的关注一些对于和我一样的新同学难以理解的细节部分作一些自己的描述,三也是为了写一下我自己的一些思考,希望能和更多的人交流。这篇文章主要内容不在于原理的详细描述,期望的是对那些原理有了整体的认识,但是总是感觉似懂非懂的朋友们有所帮助。所以内容偏向于可能对于大佬来说很简单,但是对于刚刚接触NLP的朋友来说可能不了解的部分。希望有缘的朋友看到不吝赐教。
二、Attention原理详解
1、概述
在开始Attention之前,希望大家对RNN系列网络结构要比较熟悉,如果有不太清楚的朋友可以查看我之前写的一篇博客循环神经网络RNN、LSTM、GRU原理详解,简单清晰的描述了RNN的网络结构和前后向传播过程,主要原因在于虽说Attention方法发展到现在已经不仅仅是应用到NLP领域,在CV领域以及其他领域都大放异彩,也是为了这篇博客能够真正的让大家更加容易的理解这一部分内容。据我了解,Attention最早的应用还是谷歌为了提升seq2seq架构的机器翻译效果提出的,而seq2seq的编解码阶段也是用的RNN系列算法,所以对RNN系列有清楚的了解,对理解Attention原理是有很重要的意义,进而对理解Transformer大家族,都是很有帮助的,个人的猜测很多刚刚接触的朋友在看完别人的文章以后仍然会觉得似懂非懂的原因也就在于知识的断层吧。
2、Attention结构原理
首先给出一篇对Attention描述比较详细的论文请点击,主要是我觉得这篇论文中有详细的计算公式,当然这篇论文也提出了很多Attention机制的改进方案,有条件的同学值得细读,还有一篇是发表在ICRL上的请点击,这篇发表时间比上一篇要早,应该算是最早提出Attention机制的论文吧,同样有条件的童鞋细读一下。正式开始之前我还是多说一些,虽然看起来有点像废话,哈哈哈但是我觉得仍然有必要多说几句,对RNN系列算法有清晰认识的朋友都知道,RNN其中一个比较严重的缺点就是长时依赖问题,虽说后来有了LSTM等一系列变种方法来缓解这个问题,但是当序列很长的时候,解码阶段的LSTM也无法很好的针对最早的输入序列进行解码,基于此,Attention机制就被提出来了。如果对RNN不是太清楚的建议可以看看我之前的博客,接下来我们进入这部分的主题。
本文同样是以Attention在seq2seq中的应用方法来描述算法原理,对于seq2seq部分需要有些了解,其实seq2seq算法很简单,简单的说就是根据已知的输入,通过模型转换,以此来得到我们想要的结果,神奇的是,深度学习的确能够做到这一点。
首先我们先来看一下没有Attention的seq2seq模型:

我们知道不管是编码还是解码,使用的都是RNN,编码阶段除了自己上一时刻的隐层输出外,还有当前时刻的输入字符,而解码的时则没有这种输入,那么一种比较直接的方式就是将编码端得到的编码向量作为解码模型的每一个时刻的输入特征。 当然其实编码器选择LSTM的话,也可以直接用最终的语义向量C作为输入。 我们从图中可以看出,编码向量都是等权重输入的,也就是每一个时刻输入的编码向量是一样的。
下图是一个应用了Attention机制的seq2seq模型:

从这个图中我们就能够看出,解码阶段输入的编码向量是带权输入,这个编码向量的权重是根据不同的解码时刻进行动态的变化,当然除了编码向量输入外,还有解码的上一时刻的隐层输出
 和最终输出
和最终输出
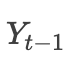 ,其中
是需要embedding,在训练的时候是真实值,预测的时候是预测值,当然这里也是可以改进的,在TF源码中是采用的论文中的这种方式,当然这个涉及的是seq2seq的知识,此处不展开。
至此Attention的原理很简单,就是在解码的时候能够得到一条针对不同解码时刻的特定编码向量
(这句话虽然拗口但是很重要),而这个过程中最重要的就是每一个隐层的输出
,其中
是需要embedding,在训练的时候是真实值,预测的时候是预测值,当然这里也是可以改进的,在TF源码中是采用的论文中的这种方式,当然这个涉及的是seq2seq的知识,此处不展开。
至此Attention的原理很简单,就是在解码的时候能够得到一条针对不同解码时刻的特定编码向量
(这句话虽然拗口但是很重要),而这个过程中最重要的就是每一个隐层的输出
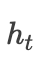 的权重
的权重
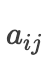 怎么计算,那么我们接下来看一下实现过程。
怎么计算,那么我们接下来看一下实现过程。
先给出公式:
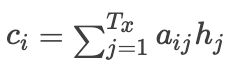
其中i表示的是解码阶段的第 时刻, 表示的是编码阶段的第j时刻,
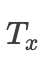 表示的是编码阶段的时间步长。
那么
就表示的是解码的第
时刻的第
个编码隐层权重。
这个公式说明了解码的第
时刻的输入编码向量是如何得到的,也可以看出最重要的是这个
如何求得。
表示的是编码阶段的时间步长。
那么
就表示的是解码的第
时刻的第
个编码隐层权重。
这个公式说明了解码的第
时刻的输入编码向量是如何得到的,也可以看出最重要的是这个
如何求得。
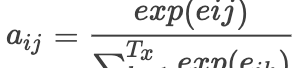
其中
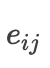 是对应权重
的能量函数或者说是得分函数,
是对应权重
的能量函数或者说是得分函数,
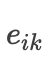 是第k个权重对应的能量函数,我们从公式中可以看出,其实权重
就是对能量函数进行softmax归一化之后的结果,那么问题的重点又转移到了能量函数的求解,在此说明一下最终求得的attention权重
是第k个权重对应的能量函数,我们从公式中可以看出,其实权重
就是对能量函数进行softmax归一化之后的结果,那么问题的重点又转移到了能量函数的求解,在此说明一下最终求得的attention权重
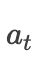 的长度是和时间step是一致的,这点很重要。
的长度是和时间step是一致的,这点很重要。
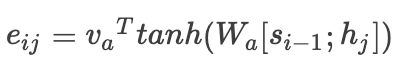
其中
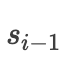 指的是解码阶段的前一个隐层输出,这个公式在上面我提到的论文中有三种方式计算方式,公式如下:
指的是解码阶段的前一个隐层输出,这个公式在上面我提到的论文中有三种方式计算方式,公式如下:

其实在TensorFlow的源码中,采用的是第三种计算方式。
至此我们的Attention最核心的权重
就计算出来了,那么我们接下来对整个过程进行一下梳理,流程如下图:

右边的灰色框框里面就是Attention机制的计算流程,根据上面的公式倒推回去看,应该就能够很清楚的看明白了,注意一点是上图仅仅是解码阶段。 我们不应该把Attention机制看做是一个单独的算法,应该把它看做是一个方法,只要你掌握了Attention的本质,完全可以发挥自己的想象合理运用Attention机制取得理想的效果。 最后顺便提一下soft-attention和hard-attention的区别,soft-attention就是我们上述的attention机制,解码阶段对编码的每一时刻的输出进行加权平均的方法,可以直接求取梯度; 而hard-attention选择编码的输出状态是采用的蒙特卡罗抽样的方法,这部分有需要的朋友可以深入一下。
3、个人对Attention机制的一些理解
首先对于这个机制的名字我知道的就有两个,一个叫Attention,一个叫对齐模型。其实我更倾向于叫它软特征提取。因为其本质也就是在每一个解码时刻,选出对当前影响最大的特征值。其实我觉得这样去认知attention机制对于我们把attention机制应用于NLP其他任务或者是其他领域都是有很大帮助的,例如CV领域,当然我现在并不知道CV领域是如何使用attention机制的,但是基于此的理解可以猜想到应用方法,比如分辨一张图片是猫还是狗,通过我们的卷积提取特征之后,我们使用attention机制,就可以把那些猫独有的特征重点捕获了,不仅仅捕获了更有价值的特征信息,而且还可以降低共有特征对模型分类效果的影响,甚至是图像本身的一些噪音影响。甚至可以基于此让那些权重低于阈值的参数在推理的时候进行截断,在某些场景下也可以达到减少推理时间的作用,当然这里希望和我们深度学习中的过拟合区别一下,是有一定不同的。其次是通过求解能量函数的过程个人认为我们在文本相似度获取匹配的时候是否也可以采取这样的方式。当然了这些仅仅是个人的YY,切不可当做知识点,只是想以此举例能让刚接触的朋友能够多一个方面去理解,所谓仁者见仁。
三、Transform原理详解
1、概述
RNN固有的顺序性,导致模型不能并行,当然所谓的并行指的是一条样本不能同时被处理,因为特征之间是有前后依赖的。不过attention机制的有效性是显而易见的,那么有没有一个更好的方法来解决缺陷,保留优势呢?于是Transform诞生了,紧跟着是BERT的诞生,至此NLP领域也开启了CV领域的ImageNet时代(迁移学习时代)。更加强大的特征提取能力为复杂的NLP任务提供了强有力的语义向量表示,让NLP更进一步的走进了每一个人的生活。当然attention只是Transformer模型结构的一部分,但是也是最为关键的一部分,对于Transformer的论文,我之前已经翻译好了,有需要的朋友可以查看我之前的翻译Attention is all you need论文翻译。
2、Transformer结构原理
既然Transformer是attention的升级版本,那么肯定和attention有着一样的地方,所以在介绍Transformer之前需要对以下3个参数进行解释:
Q(Query):对应我们上述attention机制中解码端的前时刻的隐层输出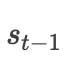
K(Key):对应我们上述attention机制中的编码端的所有隐层输出。
V(Values):对应我们上述attention机制中的编码向量C。
允许我吐槽一下,网上大多数大佬的Transformer文章,对于这三个参数的解释对刚接触的小伙伴而言可以说是一点都不友好,解释不清楚这三个参数,后面所有精彩的讲解都是枉然。
有了上面的解释,我们再来回顾一下大佬们的解释:相当于我们拿着查询向量Q去对应的K里面查询到对应的V。也就是说模型根据已有上一时刻的隐层信息Q,通过和编码器的每一个隐层的输出K加权平均(也就是attention)之后得到了我当前时刻的编码向量V。我相信这样一解释应该就能够明白了QKV是什么了。当然了在Transformer中是self-attention,怎么个self法呢,其实我们知道在前面我们所讲的attention机制下的QKV都是自回归产生的(也就是当前时刻的输出依赖上一时刻的输出称之为AR),而在self-attention中QKV都是由模型的input和相应的矩阵相乘得到的,所以论文中说self-attention是自编码的(AE),因为在self-attention中不需要像RNN中那样一步步的生成,这也是所谓的Transformer具有可并行化的原因所在,当然对于并行化我在前文已经提到了。
整体结构
首先给出论文中的整体模型结构:

毕竟是attention的变种,逃不出端到端的框架(这句话的意思不是说self-attention机制只能用在端到端的框架里,只要你愿意可以用到任何需要提取特征的地方),在论文当中,左边是6层Encoder,右边是6层的Decoder,Decoder中的第一层是Masked Multi-Head Attention层,至于为什么要遮蔽,主要是由于我们的语言模型建模都是基于字词级别的,要得到一个句子,肯定只能从左往右的解码每一个字词,对于未来的信息要遮蔽掉,至于为什么不能直接预测一条句子,大概率是字词之间的信息更丰富吧。
Input Embedding
对Transformer有了解的朋友都知道这里有位置信息的嵌入,下图就是论文中给出的位置编码公式:

首先先解释一下各个参数: pos是每一个token在序列中的位置,2i和2i+1表示的是基数每一个token位置向量的偶数维度和奇数维度,其中所有位置下标都是从0开始的,
 是词向量的维度,同时也是位置编码的维度。
是词向量的维度,同时也是位置编码的维度。
论文中说对于一个固定K值,
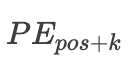 都可以表示为
都可以表示为
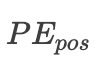 的线性函数,这句话是什么意思呢,其实也就是说间隔K的两个token之间的位置关系是线性相关的,接下来我们进行推导来看看是如何线性相关的,为了书写简单,对上述公式进行简化:
的线性函数,这句话是什么意思呢,其实也就是说间隔K的两个token之间的位置关系是线性相关的,接下来我们进行推导来看看是如何线性相关的,为了书写简单,对上述公式进行简化:
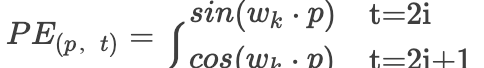
那么我们的
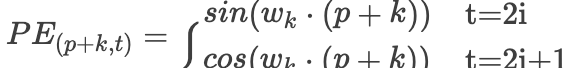
由于我们三角函数有如下转换:
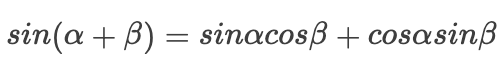
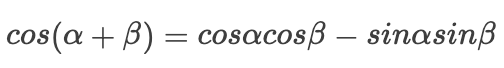
则有:
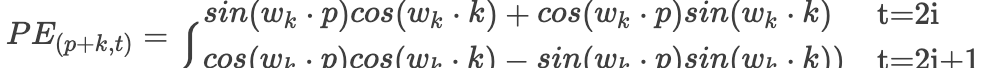
其中由于我们的k值是一个定值,所以上述表达式中和k有关的项就是常数,是不是就是关于
 的线性函数了,当然其实对于transformer这样的自编码模型而言,由于缺失了token的位置信息,而位置信息的重要性在序列学习任务中是至关重要的,这也说明了位置编码方式的好坏也会直接影响到位置编码信息的合理性,所以其实对于位置编码部分已经有了很多改进,此处以后有机会研究一下再来单独写一篇博文。
的线性函数了,当然其实对于transformer这样的自编码模型而言,由于缺失了token的位置信息,而位置信息的重要性在序列学习任务中是至关重要的,这也说明了位置编码方式的好坏也会直接影响到位置编码信息的合理性,所以其实对于位置编码部分已经有了很多改进,此处以后有机会研究一下再来单独写一篇博文。
Transformer层
这部分本来自己写了一些的,后来发现有大佬写的非常好了,而且也把我想要写的前馈神经网络和残差连接也写进去了,我就直接附上大佬的文章连接吧。通过对RNN和attention的深入理解,其实再去看看网上的文章、论文以及源码,特别是一些对NLP发展历程中相关改进的论文都不再觉得是一件困难的事情了,也不会产生一种以前的模型哪里不好,为什么要改,这样改的优势是什么,为什么要这样改的疑问了。
残差连接

对于残差网络其实结构很简单,跳跃几层之后再把x加进去。 都说残差网络有效的解决了梯度消失的问题,解决了网络退化的问题,但是为什么有效呢,我们还是通过公式来看一看残差的有效性,首先我画了一个简单的计算图,其中都是全连接的方式,为了图形看起来干净,简化了一下,当然画的有点丑,哈哈哈,我们以此为例来计算一下:

当我们不用残差连接的时候,也就是略去图中虚线的部分,则前向传播如下:
顺便提一下,如果对梯度下降原理不是很清楚的童鞋可以参考我以前的博客梯度下降算法原理及其计算过程
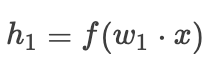
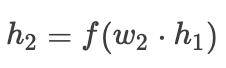
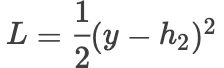
则梯度为:
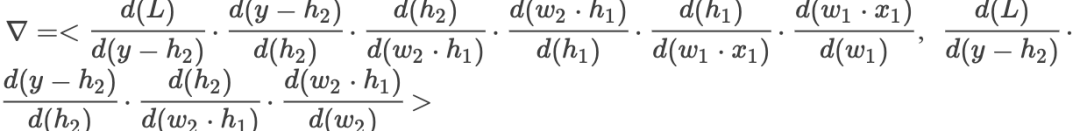
为激活函数, 为隐层输出, 为损失函数, 是梯度。
等我们采用了残差连接之后,前向传播如下:
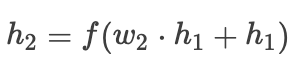
则梯度为:
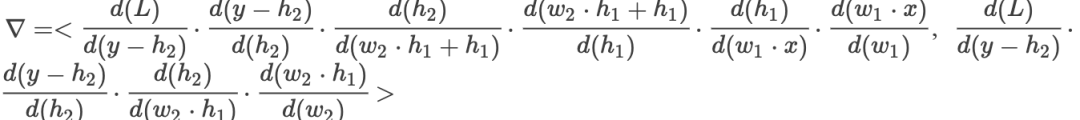
其中有
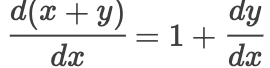
通过对比我们发现第一种情况下,如果每一个偏导数的值都很小,那么在很深的网络结构中就会导致梯度值很小,也就是梯度消失,参数将无法更新,而加入了残差之后,再网络层次很深的时候,每个偏导数都会加1,因此误差仍然可以传播,有效解决了梯度消失的问题。
至于网络退化的问题,首先要明确网络退化的概念是由于在反向传播的过程中绝大多数的参数矩阵都停止了更新,使得网络没有了继续学习的能力,因为参数不更新,就说明新样本对网络训练不起作用,也就是没有学习到新样本的特征。 对于网络退化个人还没有去深入学习,个人认为需要去从矩阵的秩等特性去分析导致参数停止更新的原因。
3、个人理解
其实对于Transformer而言,最主要的改进就在于并行化和获取长序列的语义信息,能够并行化的原因在于self-attention所需要的QKV三个向量是由输入的三种线性变换得到了,而不是像传统的RNN那样需要完成所有的时间步骤,而对于能够获得更长的语义信息在于self-attention计算是因为每一个Q都可以和原始的K相乘得到对应的V,而不是传统attention那样,Q、K由于在RNN中前向传播而导致长距离传递的信息丢失。当然了后来Transformer-XL被提了出来,包括最近谷歌大佬们又提出了新的内核Synthesizer来替代Transformer,此处贴出论文地址,不得不服大佬们的创造力。细细品味这些大作,深入理解之后会对我们有很多其他的一些启发,例如Transformer中的位置编码方式,既然深度学习现在拥有了很强大的特征提取能力,那么对于如何能够加入更多类型的特征进入我们的数据,也显得尤为重要。
四、BERT原理详解
1、概述
其实到了这里,一路走来,BERT好像也没有以前的那么神秘了,BERT利用了Transformer的编码器,如果有需要的童鞋可以看看我之前的BERT论文翻译。BERT在模型结构上没有太多的新意,能够取得好的效果,个人认为第一主要是依赖强有力的特征提取器Transformer,其二就是两个自监督的语言模型。BERT开启了NLP领域的ImageNet的开端,通过大规模的语料对网络预训练,初始化参数,然后在预训练的基础上使用少部分的专业领域预料进行微调,从而达到客观的效果,首先看一下BERT的整体结构:

从图中我们可以看到,BERT的整体结构是多个Transformer结构堆栈起来的,每一列的Transformer都是相同的操作,都是序列的完整输入,和Transformer没有太大的区别。 下面我们主要来看看BERT中运用的语言模型和一些具体的任务是怎样完成的,以此能够启发我们在算法开发中能有更多的解决方案。
2、BERT中的语言模型
MLM语言模型
在bert中为了训练输入的参数,采用了自监督的方式在大规模预料上进行预训练,对于词级别采用的MLM( Masked LM ),主要过程和方式如下:
1.随机masked掉输入序列中所有token的15%,使用[MASK]标记,在词表中是需要有[MASK]标记的,然后训练的目标就是去预测这些token。
2.论文中最后也提到了,由于[MASK]标记在预测的时候是不存在的,为了减轻训练和预测之间的不匹配,对于所谓的不匹配个人的理解是,虽然一个序列中只遮蔽15%的token,但是在大规模的预料中,百分比虽然不多,但是基数不容小觑,相当于模型在训练的时候学习了一些[MASK]的特征进去,其实15%也不少了,那么为什么作者不少遮蔽一点token呢,显而易见的是,mask操作的目的就是为了自监督模型进行训练,如果太少的话,岂不是意义不大了,那么作者采用了什么措施来缓解这个问题呢?答案就是对其中的15%mask掉的token采取如下策略:
(1)80%的概率用[MASK] token(2)10%的概率用随机token(3)10%的概率不替换token。
那为什么这样做就能解决上面的问题呢,在同样遮蔽15%的token的条件下,降低了20%[MASK]标记出现的概率,那对于后面的随机token和不替换操作是为了什么呢?其实因为如果剩下的20%都用随机token的话,会造成错误的学习,因为你给网络的样本就是错的,本来你要预测‘天’token,你随机给的是一个‘地’token,也就是人为的错误样本,所以有10%的概率使用原来的token,而且随机替换产生的错误仅仅是15%*10%=1.5%,其实这对于模型来说问题不大,翻不起太大的浪花,就像你工作用的Python语言,但是你的JAVA语言的知识认知是错误的,但是对你而言造成不了什么影响,毕竟你也不用JAVA。那么可能你会问,不替换和一开始就不替换有区别吗?答案是有区别,因为对于模型而言你完全不知道输入的到底是不是真实的token,所以模型只能根据上下文去预测,从而达到训练的目的。就像你的一个不靠谱的朋友跟你说今天在路上捡到了100块钱,你不知道他说的是真是假,你只能根据一些其他的依据来判断他说的话可信度有多高。这是对于词级别的,下面我们来说说句子级别的。
NSP语言模型
对于句子级别的任务,BERT同样也给出了一个行之有效的方法(后来有论文验证NSP任务似乎并不是那么必不可少,此处暂不讨论这个问题),就是根据上一句子预测下一句子是否为真。为什么要提出这个预训练任务呢,主要也是很多譬如问答、推理之类的任务,更多的是要学习句子之间的关系,这是语言模型无法做到的,因为语言模型根据token预测token,是在句子内部进行学习的。而NSP就是为了获取句子之间的依赖关系,NSP任务可以在单语料库中进行自监督学习,50%的概率下一句是真实的,50%的概率是从语料库中随机选取的。当然论文中也提到了,使用文档级别的语料是远远优于无序句子的语料,这一点很明显。和MLM语言模型很异曲同工,自监督是其最大的优势。
微调
BERT可以认为是一个半监督的过程,有了自监督的预训练过程之后,在我们的实际使用过程中,还需要我们的专业领域数据对模型参数进行微调,以此来更好的适用于我们的网络,接下来简单的介绍一下论文中出现的几种任务,首先给出总体任务图。

MNLI (Multi-Genre Natural Language Inference): 给定一对句子,目标是预测第二句子和第一个句子是相关的、无关的还是矛盾的。
QQP (Quora Question Pairs): 判断两个问句是否是同一个意思。
QNLI (Question Natural Language Inference): 样本是(question,sentence)在一段文本中sentence是否是question的答案。
STS-B (Semantic Textual Similarity Benchmark): 给出一对句子, 使用1~5的评分评价两者在语义上的相似程度。
MRPC (Microsoft Research Paraphrase Corpus): 句子对来源于对同一条新闻的评论. 判断这一对句子在语义上是否相同。
RTE (Recognizing Textual Entailment): 是一个二分类问题, 类似于MNLI, 但是数据量少很多。
SST-2 (The Stanford Sentiment Treebank): 单句的二分类问题, 句子的来源于人们对一部电影的评价, 判断这个句子的情感。
CoLA (The Corpus of Linguistic Acceptability): 单句的二分类问题, 判断一个英文句子在语法上是不是可接受的。
SQuAD (Standford Question Answering Dataset): 给定一个问题和一个来自包含答案的Wikipedia段落,任务是预测答案在段落中所在的位置。
CoNLL-2003 NER 命名实体识别任务,应该是大家最熟悉的了,预测每个字的标签是什么。
对于 SQuAD 任务其实论文中详细解释了的,大家可以直接看我翻译的论文即可。
总体来说对于(a)(b)中的任务,我们取得的是最终CLS标记的值。 对于(c)中的任务主要是预测start和end标记所在的最大值,且是start的id值小于end的id值,其中start是答案所在段落中的起始位置,end是结束位置。 对于NER任务,自然是取得每一个输出的值,因为每一个token都对应着一个标记。 在BERT的源码当中也给出了一个二分类的代码示例,我们可以依照这源码进行修改来训练我们的任务。
3、个人理解
其实BERT给我最重要的启发是自监督,由于目前的深度学习都是监督学习,使得数据成本非常高,也因此对模型训练造成了约束。而自监督学习能够很好的解决当我们的任务需求不高的时候,可以很容易的获取数据和完成一个基础模型训练,能够很好的协助完成我们的主要任务,GPT3最近也是火了一把,号称是微调都省了,直接拿着输出的特征就可以使用,总共使用了1700亿的参数量,反正我是惊呆了,个人感觉这种巨无霸不如XLnet、RoBERTa、ALBERT、XLNet等,网上相关文章也有大佬写的很好,个人知识面有限,贴上连接意思意思。这篇博客我也花了一些时间才写到这里,白天工作,晚上熬夜写,脑袋有点慌了,暂且写到这里吧,实在是写不动了,希望对大家有所帮助,记得点个赞哟。
本文由作者授权AINLP原创发布于公众号平台,欢迎投稿,AI、NLP均可。由于公众号排版问题可能导致部分公式显示不清楚,可以去原文阅读,原文链接,点击"阅读原文"直达:
https://blog.csdn.net/TheHonestBob/article/details/106535620

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




