注意力机制 | 图卷积多跳注意力机制 | Direct multi-hop Attention based GNN


1.Abstract
2.Introduction
在每一层中就能进行 long-range message passing;
attention的计算是与context有关的,DAGN通过聚集所有路径上的注意力score来计算注意力
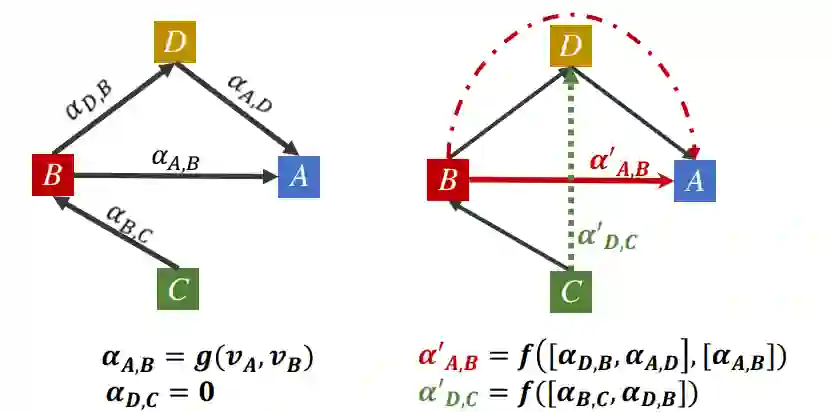
3.DAGN
3.1 Multi-hop Attention Diffusion
 的attention分数
的attention分数
 计算方式如下(
计算方式如下(
 和
和
 表示节点,
表示节点,
 表示边的种类):
表示边的种类):

 :
:
 进行softmax得到 attention matrix
进行softmax得到 attention matrix
 ,其中
,其中
 表示当从节点
表示当从节点
 向节点
向节点
 聚集信息时,在第
聚集信息时,在第
 层中的attention value。
层中的attention value。
 的幂,通过图扩散来计算multi-hop邻居的注意分数:
的幂,通过图扩散来计算multi-hop邻居的注意分数:

 是 attention decay factor,满足
是 attention decay factor,满足
 。该过程通过利用
。该过程通过利用
 来增加attention的感受野。在作者的实现中,利用了几何分布( geometric distribution )
来增加attention的感受野。在作者的实现中,利用了几何分布( geometric distribution )
 ,其中
,其中
 。该选择的原因是基于the inductive bias,为了使得远处的节点对应的weight应该较少;同时对与目标节点关系路径长度不同的节点权重应该相互独立。因此,本文定义了基于特征聚合的graph attention diffusion:
。该选择的原因是基于the inductive bias,为了使得远处的节点对应的weight应该较少;同时对与目标节点关系路径长度不同的节点权重应该相互独立。因此,本文定义了基于特征聚合的graph attention diffusion:

 进行信息聚合,本文通过定义一个数列
进行信息聚合,本文通过定义一个数列
 , 当
, 当
 时,该数列能收敛到
的值:
时,该数列能收敛到
的值:

 。很多真实世界网络具有小世界(small-world )特征,在这种情况下,较小的K值就足够。对于具有较大直径的图,选择较大的K和较小
。很多真实世界网络具有小世界(small-world )特征,在这种情况下,较小的K值就足够。对于具有较大直径的图,选择较大的K和较小
 。
。
3.2 Direct multi-hop Attention based GNN


 ,layer normalization和residual connection。
,layer normalization和residual connection。
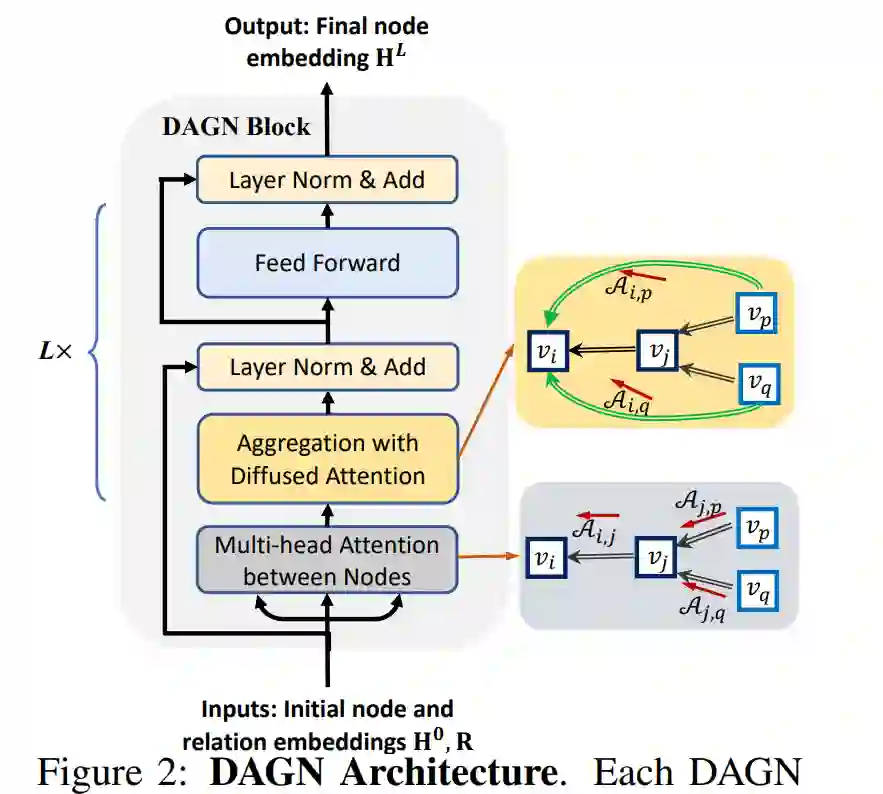
4.Experiments
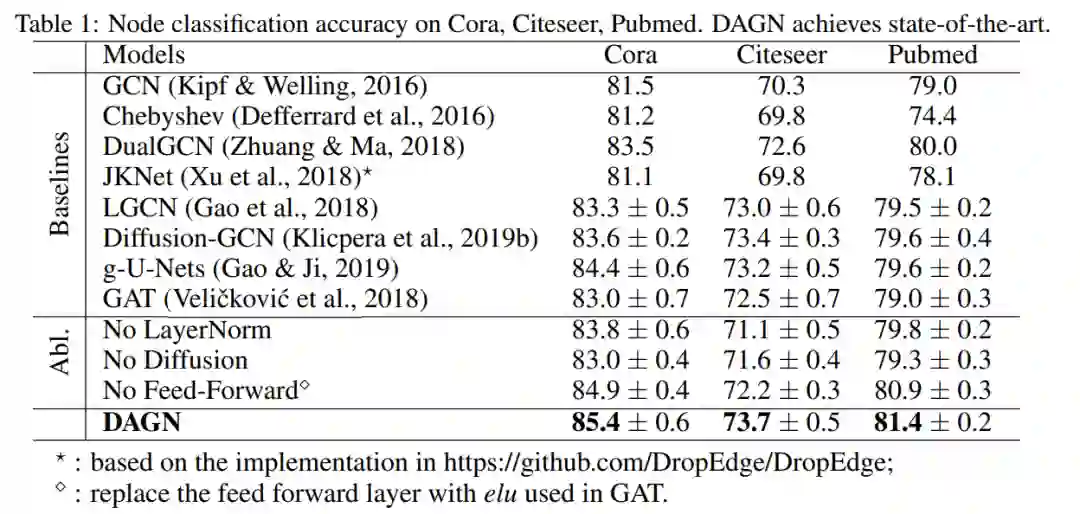
4.1Node classification

4.2. Knowledge graph completion

4.3 Model Analysis
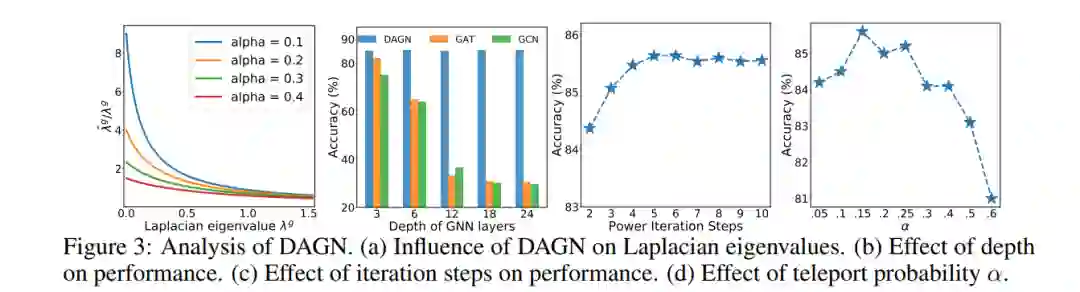
在DAGN中,较小特征值被amplfied,对应着graph中的large-scale structure;较大特征值被suppressed,对应着graph中带有noise信息的特征向量;
由于 over-smoothing problem,GCN和GAT会随着层数的增加而性能下降;而DAGN在18层时能取得最好的性能;
最优K值与最大节点平均最短路径距离( the largest node average shortest path distance )相关,这能帮助选择最佳的K;
相对于GAT,DAGN的Attention Distribution分布有larger discrepancy,说明更能分辨出重要的节点
4.4 Personal Thoughts
将GAT扩展到多跳邻居,节点能获取更多信息
利用一种近似的方法来计算多跳的attention,使得复杂度任然保持较低
实验比较充实,结果证明在各个任务都能取得the state of art
原文指出:DAGN = GAT + diffusion + layer normalization + residual connection,在Cora分类中,DAGN=85.4,GAT = 83,而DAGN - diffusion = 83 ,没有进行GAT+layer normalization 或 residual connection的实验
由于论文还没被接受,没有代码公开
个人感觉里面有一些细节没讲清楚
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



