该研究由中国人民大学GeWu实验室主导,发表在IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI),目前相关代码已开源。
随着互联网的发展,在能够轻易获取海量数据但标注困难的背景下,无监督学习的重要性不断上升并在近年得到了广泛关注。其中,如何能够让机器以无监督的方式建立对客观物体的认知是亟待解决的问题之一。
在人类的实践经验中,出色的多重感官让我们对周围的环境能够做出快速而准确的判断。根据有关研究表明,人类通过视觉和听觉获取了大脑从外界所接收信息的绝大部分(约占 90% 以上)。视觉,听觉,及其相互之间的关联关系在我们对外界的认知过程中起着至关重要的作用。例如,当在音乐厅享受音乐时,无论是悠扬的弦乐组,还是浑厚的管乐组,甚至藏在角落的三角铁,只要听到了声音,我们就可以毫不费力地判断出是哪个乐器在舞台的哪个角落奏鸣。这是因为一个我们在小时候学到的物理现象:声音是由物体振动产生的,那么不同乐器因为其所具有的不同的振动频率,导致其所发出的音色是不同的,而不同的声色帮助我们区别并认识不同的乐器。
由此可见,物体与其所发出声音之间的天然对应关系为模型的训练提供了自监督信号。并且,大部分物体在视觉和听觉上均具有类间差异大而类内差异小的物理性质。这一物理性质为模型通过表征聚合等方式习得类别判别能力提供了实际基础。基于这一现象,在该研究中,作者首先对复杂场景下的多声源定位任务进行了定义,为模型引入类别判别能力。再则,借助判别性声源定位任务实现对不同类别物体的认知,在无需人为标注的情况下,为解决典型视觉任务,如物体检测,提供了新思路。
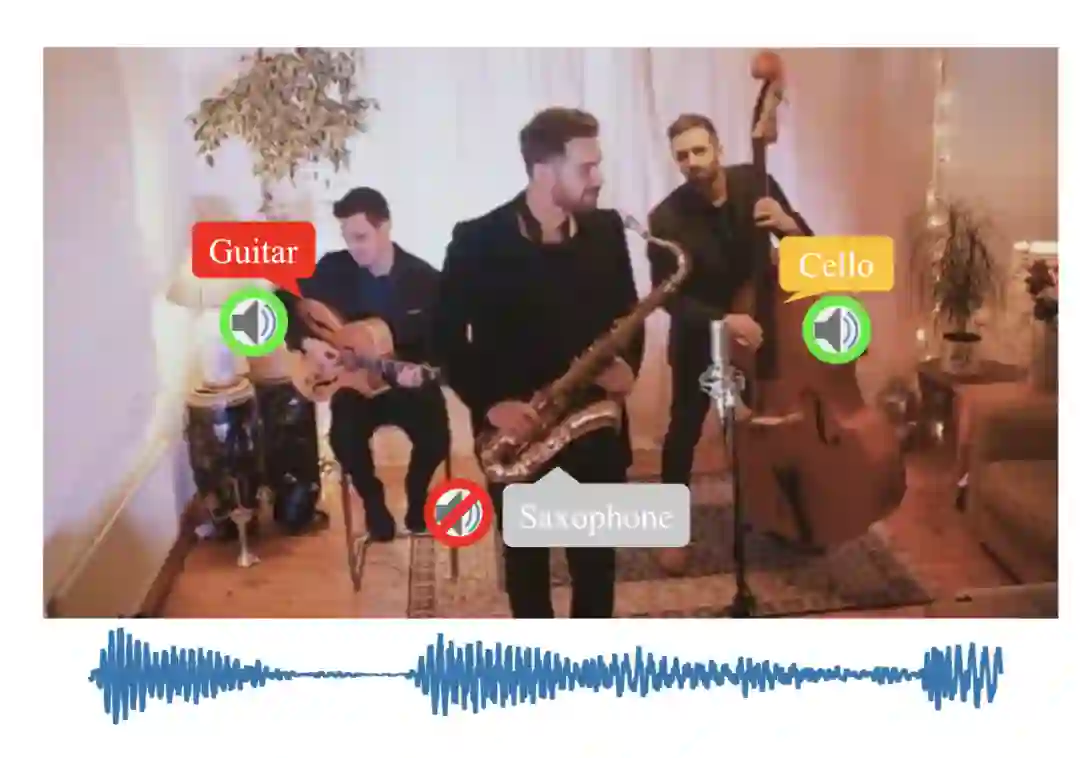
在该研究中,作者以判别性声源定位为基础实现了构建物体类别认知的目标,并将其应用在其他经典视觉任务中,如物体检测。声源定位任务的目标为:输入一段视频及其对应的音频(一般指单通道音频),模型能够定位出画面中发声物体的位置。先前的声源定位任务所涉及的场景相对较单一,主要聚焦在单声源或具备先验知识(如画面中物体均发声且个数已知)的多声源场景中。但在现实生活中,如鸡尾酒会,不仅常常同时具备多个物体,而且发声与不发声物体往往交织在一起。此外,现有声源定位工作仅停留在对发声物体的定位上,而缺乏在发声物体的类别判别方面的探索。因此,该研究希望在无需额外先验知识的情况下解决更加贴近生活场景的包含不发声物体的判别性多声源定位任务。
![]()
图 1 真实的多声源场景常常包含多种物体且存在不发声物体。
受人类视音感知能力的启发,提出了判别性多声源定位任务:不仅定位出发声物体的位置而且辨别其类别。
提出了两阶段的学习框架。在单声源场景中学习物体的视音表征,并迁移至多声源场景下解决包含不发声物体的判别性多声源定位任务。
通过解决判别性声源定位任务构建对不同类别物体视觉表征的认知,并将其迁移到其他经典视觉任务中,如物体检测等。
![]()
论文链接:https://ieeexplore.ieee.org/document/9662191
项目主页:
https://gewu-lab.github.io/CSOL_TPAMI2021/
![]()
首先,由于判别性多声源定位是相对困难的任务,该研究提出按照从易到难,逐步迁移的思路。从单声源定位任务开始,通过在简单的场景下对物体的视觉表征有一定认知之后,迁移到更为复杂的多声源场景中。根据声音是由物体的振动产生的这一规律可知,视觉和听觉之间天然存在着一一对应关系,已有许多先前的研究利用该视音一致性作为自监督信号对网络进行预训练。在声源定位,特别是单声源定位任务中,借助视音一致性自监督信号能够以判断输入的音频和视频信号是否匹配作为目标进行训练,进而得到画面中对音频信号响应较大的区域,即为发声物体所在区域。这一过程利用了场景级别的视音一致性作为自监督信号。
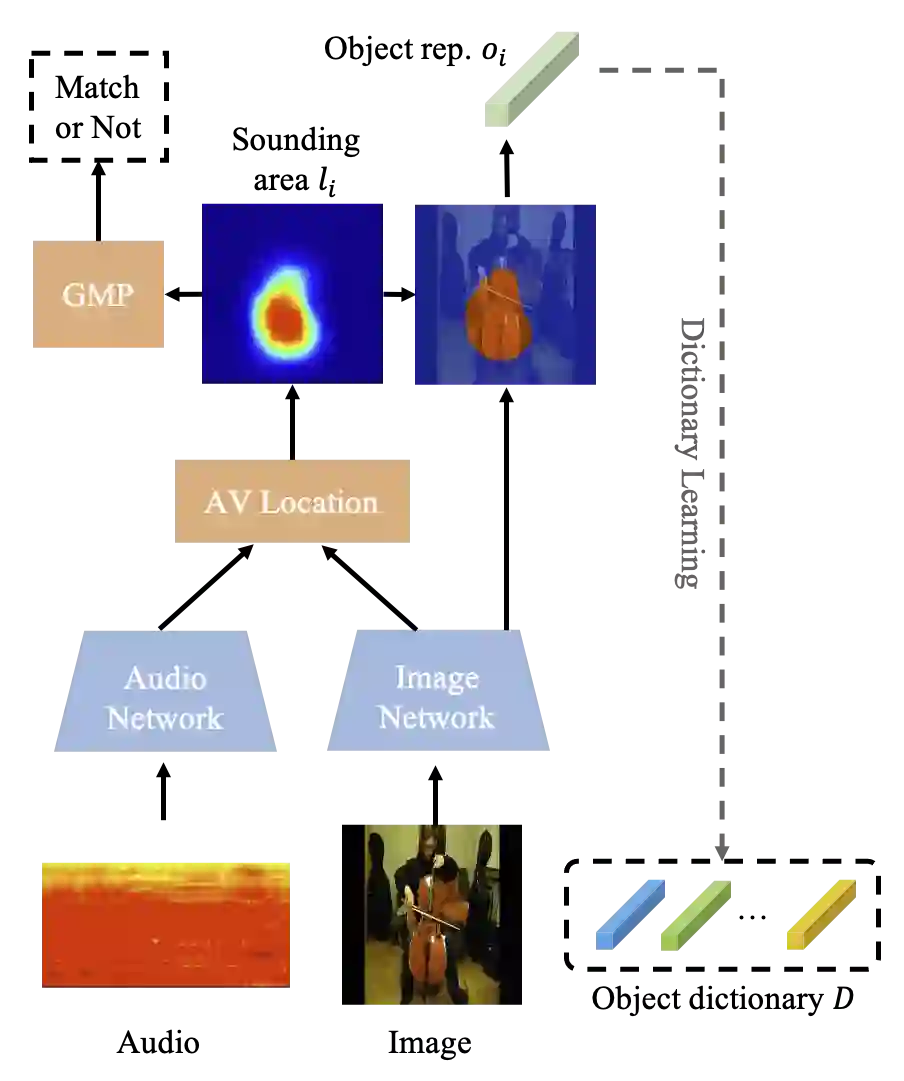
与此同时,基于声源定位得到的定位图能够为排除复杂变化的背景干扰提供帮助,提取出较为干净的物体视觉表征。并且,考虑到同一类别的物体的视觉表征具有一致性,通过将相似的视觉表征聚集,而后提取该聚集类别的代表性视觉表征是可行的。基于这一思想,该研究提出用聚类的方法对基于单声源定位得到的所有样本的视觉表征进行聚类。聚类的每一个簇被认为能够代表一种语义类别的视觉表征的集合。同时,针对每个簇提取该类别的代表性视觉表征并打上伪标签,便能构建相应的物体视觉表征字典,为解决多声源定位任务做铺垫。
![]()
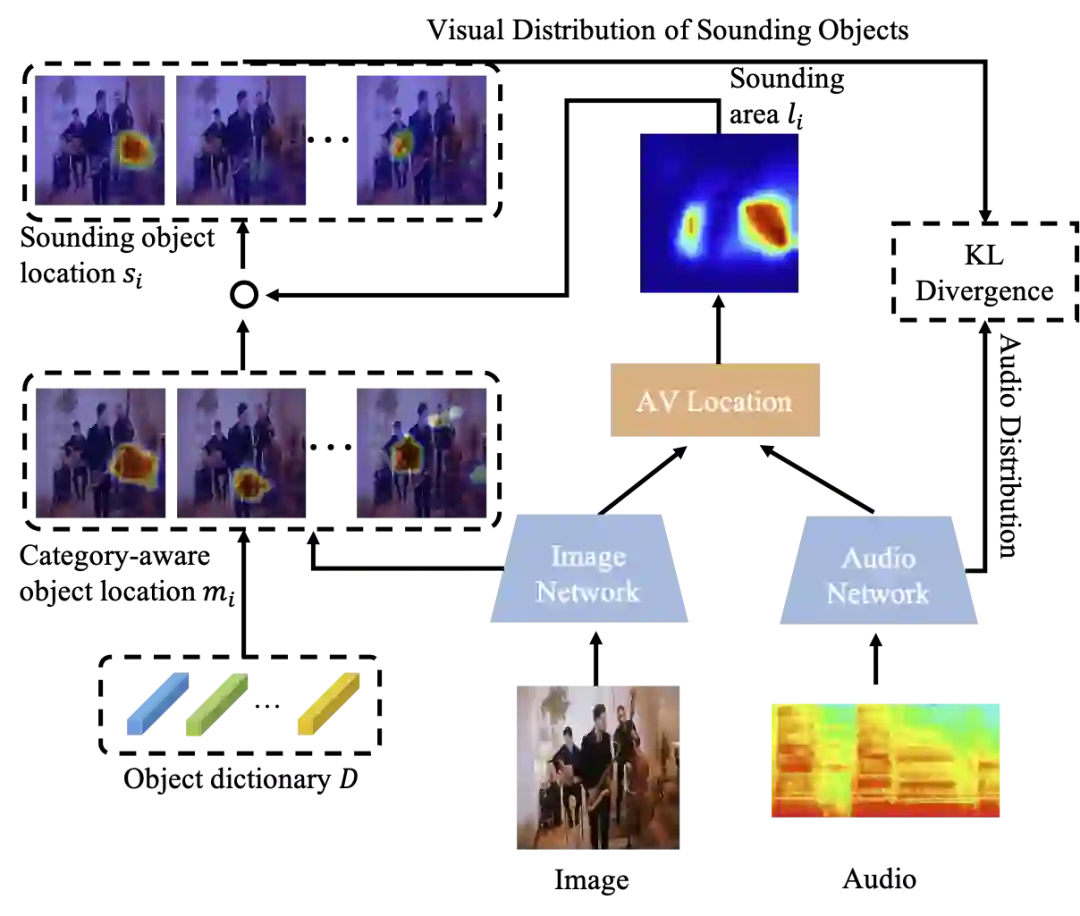
在第二阶段的多声源定位中,该研究递进地先从视觉上定位出画面中存在的物体,再进一步根据听觉信息过滤不发声物体。画面中存在物体的判断借助了一阶段中对物体视觉表征学习及所构建的不同类别物体视觉表征字典。具体来说,对于某帧多声源场景下的视频,经过视觉网络提取其特征图后,再将字典各个类别的视觉表征与该特征图的各个部分进行内积操作判断相似性。对于某一类别而言,若特征图中存在对该类别视觉表征响应比较大的区域,则可认为该区域存在这一类别的物体。此时,画面中存在的物体能够被初步定位。进而,对于不发声物体的过滤,该研究首先利用场景级别的视音一致性进行粗略的声源定位得到画面中的大致发声区域,而后将基于画面中存在物体的定位结果与发声区域进行哈达玛积,过滤掉不发声的物体,同时细化发声物体的定位结果。
此时,经定位和过滤之后,便达到了在定位图中过滤不发声物体,保留发声物体的目标。并且,根据定位结果所得到的发声物体视觉表征与音频表征构成了更细粒度的类别级别的视音一致性,能够作为自监督信号帮助训练,最终达成多声源定位的目标。
![]()
图 4 在多个真实与合成数据集上的可视化定位结果。绿色框:发声物体,红色框:不发声的物体。
![]()
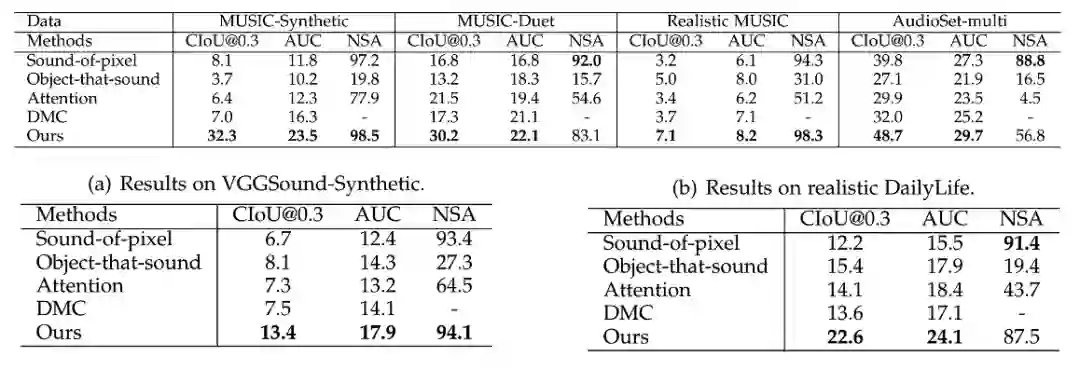
文中在涵盖了音乐、日常生活场景等广泛类别的多个真实及合成数据集上进行了多声源定位的实验,并分别进行了可视化及定量分析。在可视化定位图中,每张图展示了一类物体的定位结果,且发声物体有较大响应,而不发声物体未响应或响应很低。可以看到,尤其在合成的含有不发声物体的复杂多声源场景中,该方法具有较大优势。并且,该方法进一步在声源定位的基础上具有辨别出物体的类别能力。
![]()
图 6 在 ImageNet 子集上的无监督物体检测结果。
除了场景复杂性更高、更贴近生活之外,该研究通过将先前的声源定位任务拓展到具有类别敏感性的判别性声源定位,达到了帮助模型认知不同类别物体及其视觉表征的目标。这一特点为视觉领域其他典型任务,如物体检测,向无监督方向的发展提供了新的角度。对于无监督物体检测任务来说,两个关键问题分别是物体边界框的构建和类别伪标签的生成,而判别性声源定位任务与其不谋而合。首先,无需额外代价,声源定位任务所提供的定位图便能转换为物体大致的边界框。其次,判别性声源定位为画面中的发声物体分配了类别伪标签。
在拓展实验中,该研究利用单声源定位所得到的定位图构造物体的边界框,并与物体的类别伪标签一起作为监督信号,在无需物体检测标注的情况下训练物体检测器。ImageNet 子集上的可视化及定量实验结果表明,该无监督物体检测思路具有一定的可行性,尤其是在吉他等体积较大的物体类别上。这一实验验证了这种从判别性声源定位任务出发挖掘物体视觉知识并迁移到视觉领域其他任务上的思路具有应用前景。
总的来说,该研究从人的多重感官认知出发,考虑了声音是由物体的振动产生的这一物理现象,利用视音之间的对应关系及大部分物体在视音表征上类间差异大而类内差异小这一性质,引入并解决了具有挑战性的判别性多声源定位的任务。并且,该研究进一步将所学习到的物体视觉知识迁移到包括物体检测在内的其他视觉任务中,为用无监督方法解决典型视觉问题提供了新方向。这一研究启发我们充分利用多种模态的信息,尤其是视音模态之间的联系,认知、学习不同物体的知识,重新思考多模态背景下传统任务的解决。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com