即插即用!北大提出ACT:自适应聚类Transformer来提升DERT目标检测的速度
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达


ACT模块属于即插即用的模块,可降低DETR的计算资源!ACT使用局部敏感哈希(LSH)自适应地对查询特征并进行聚类,准确性和计算成本(FLOP)之间实现了良好的平衡。
1、简介
DERT中使用Transformer进行端到端目标检测,并实现与Faster-RCNN等两阶段目标检测可比的性能。但是,由于高分辨率的图像输入,DETR需要大量的计算资源来进行训练和推理。为了降低高分辨率输入的计算成本,本文提出了一种新型的变体,称为自适应聚类Transformer(ACT)。
ACT使用局部敏感哈希(LSH)自适应地对查询特征进行聚类,并使用原型键交互在查询键交互附近进行聚类。ACT可以将自注意力的二次O(N2)复杂度降低到O(NK),其中K是每层原型的数量。ACT可以是嵌入式模块,无需任何训练即可代替原始的自注意力模块。
2、设计动机
2.1、编码器注意力冗余
DETR中,每个位置的特征将使用注意力机制自适应地从其他空间位置收集特征信息。而语义上相似和空间上相近的特征会产生相似的注意力图,反之亦然。如下图Figure 1:
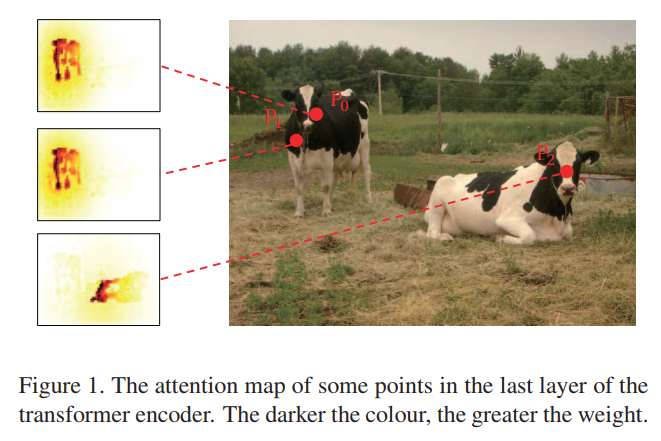
P0和P1的注意力图相似且包含冗余,而距离较远的P0和P3的注意图则完全不同。自注意力的冗余促使行为选择具有代表性的原型,并将原型特征更新传播给最邻近的位置。
2.2、编码器特征多样性
随着编码器的深入,各个特性将会相似,因为每个特性会互相收集信息。为了验证这个假设,文中计算了训练集中前100张照片中每一层特征到中心的平均距离。
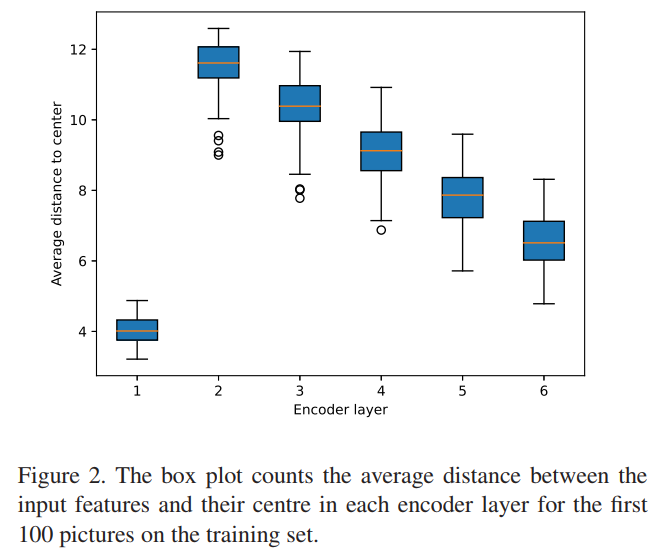
如Figure 2所示,随着Layer的深入,特征距离会降低。这种观察得出特征会在每一层之间的分布自适应地确定原型的数量,而不是静态的聚类中心的数量。
3、论文方法
作者为了将类相似的查询特征组合在一起进而解决编码器注意力冗余问题,最开始想法是使用K-means对所有图像使用预定义的中心数量来聚类查询特性。实验发现K-means聚类会显著降低预先训练好的DETR的性能。同时编码特征多样性促使设计一种自适应聚类算法,可以根据每幅图像和每一层的特征分布对特征进行聚类。然后作者选择了一种Multi-round Exact Euclidean Locality Sensitivity Hashing (E2LSH)算法,该算法能够实现查询特征感知分布的聚类。
3.1、DETR主要框架
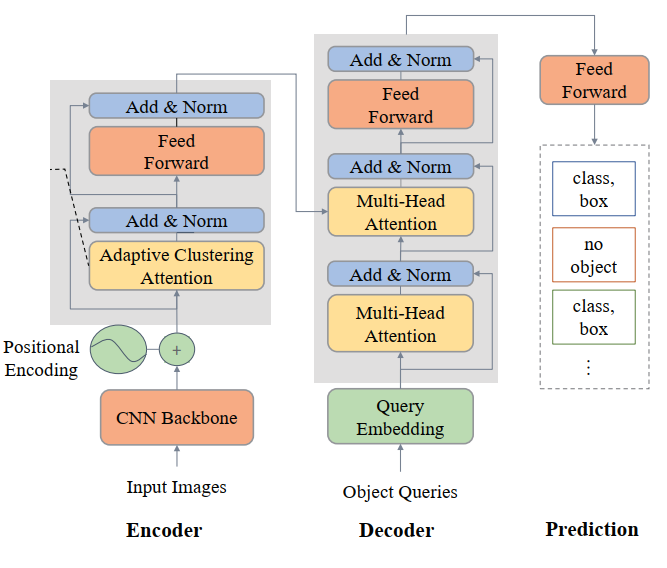
下图显示DETR的3个阶段:
3.1.1 编码阶段
在编码器中,使用imagenet预训练的ResNet模型从输入图像中提取二维特征。位置编码模块使用不同频率的正弦和余弦函数对空间信息进行编码。DETR将2D特性扁平化,并用位置编码补充它们,并将它们传递给6层transformer编码器。编码器的每一层结构相同,包括8头自注意模块和FFN模块。
3.1.2 解码阶段
解码器将一小部分固定数量并且已学习好的位置嵌入(称为对象查询)作为输入,并另外处理编码器的输出。该解码器也有6层,每层具有相同的配置:包括8-head自注意力模块、8-head co-attention模块和1个FFN模块。
3.1.3 预测阶段
DETR将解码器的每个输出传递给共享前馈网络,该网络预测检测(类和边界框)或无对象类。
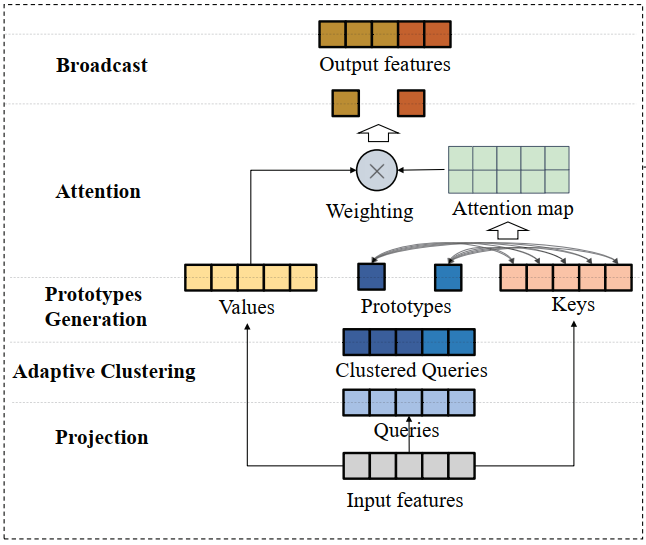
3.2、Adaptive Clustering Transformer
3.2.1 确定哈希原型
因为LSH是一个解决最近邻搜索问题的不错的解决方案,所以使用Locality Sensitivity hash(LSH)自适应地聚合那些欧氏距离较小的查询。通过控制哈希函数参数让所有的向量距离小于 的以一个大于p的概率落入相同的hash bucket。
文章选择精确欧几里得局部性敏感哈希(E2LSH)作为哈希函数:
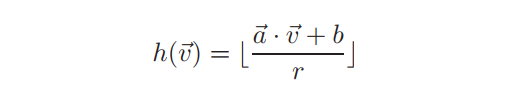
其中 是哈希函数, 是超参数, 是随机变量,且满足 , ;本文则应用L轮LSH来增加结果的可信度:
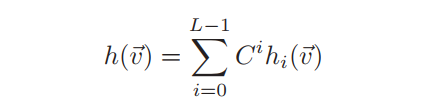
下图Figure 4显示了哈希函数的原理。每个哈希函数 可以看作是一组具有随机法向量 和偏移量 的并行超平面。超参数r控制超平面的间距。r越大,间隔越大。此外,L哈希函数将空间划分为多个单元格,落入同一个单元格的向量将获得相同的哈希值。显然,欧氏距离越近,两个向量落在同一个单元格中的概率就越大。

为了获得原型,首先计算每个查询的哈希值。然后,将具有相同哈希值的查询分组到一个集群中,该集群的原型是这些查询的中心。具体将 定义为查询, 定义为原型,其中 是集群的数量。设 表示 所属的聚类指标。第 个聚类的原型:
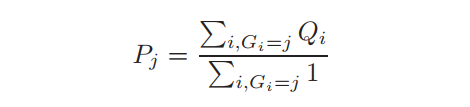
3.2.2 估计注意力输出
在原型确定后,每一组查询都由一个原型表示。因此,只需要计算原型和键之间的注意力映射。然后获得每个原型的目标向量,并将其广播到每个原始查询。于是便得到了对注意力输出的估计。与精确的注意量计算相比,减少了计算的复杂性
到
,其中C为原型数,其大于N,将自适应确定。
具体定义K为键,V为值。通过下面的方程得到了注意力输出的估计数:
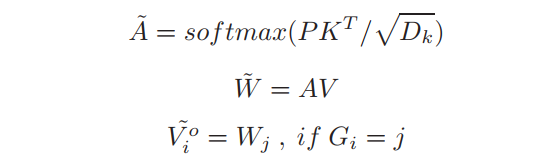
其中,softmax函数逐行应用, 表示 所属的聚类指数。
3.2.3 误差控制
对于 和 两个向量,令 。假设 和 落在同一个哈希桶中的概率是 那么就可以证明:
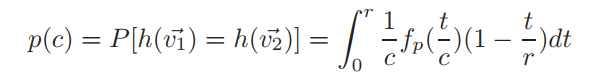
其中, 是均值为0,方差为1的正态分布的概率密度函数。
ACT独立应用L轮哈希, 和 的碰撞概率为 。显然, 与c呈单调递减,因此,当两个查询的距离小于 。对于给定的置信度可以通过调整超参数L和r来控制查询与其原型在同一簇内的距离,估计误差会随着L的增加和r的减少而减小。
3.2.4 多任务知识蒸馏
虽然ACT可以在不经过再训练的情况下降低DETR的计算复杂度,但多任务知识蒸馏(MTKD)可以通过更少的微调时间进一步提高ACT,并在性能和计算之间取得更好的平衡。
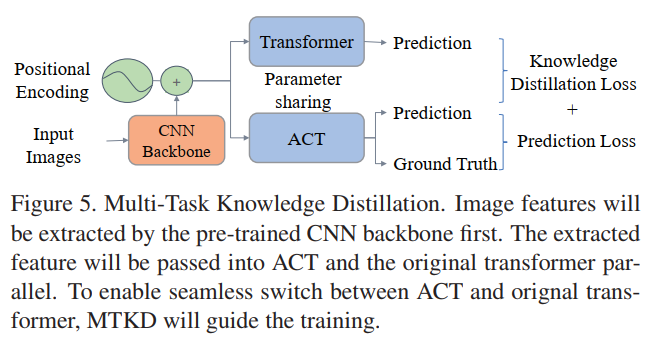
如下图所示图像特征将首先通过预训练好的CNN主干进行提取。提取的特征将通过ACT与Tranformer并联。为了在ACT和原始的transformer之间实现无缝切换,MTKD将用于约束训练。训练损失表示为:
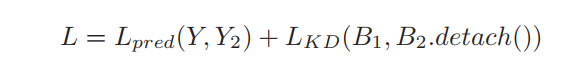
式中,其中
为Ground Truth,
为ACT预测的Bounding Box,
, Y2为DETR预测的Bounding Box和完整预测。
是Ground Truth与DETR预测之间的原始loss。
是知识蒸馏的损失,它使ACT和DETR预测的Bounding Box之间的L2距离最小化。
训练损失的目的是结合完全预测和近似预测之间的知识转移对原始Transformer进行训练,实现ACT和transformer之间的无缝切换。知识转换器包括区域分类和回归蒸馏。回归分支比分类分支对由ACT引入的近似误差更敏感。因此,只转移Bounding Box回归分支的知识。实验观察到通过只Bounding Box回归分支的训练收敛速度要快得多。
4、实验
4.1、Ablation Study
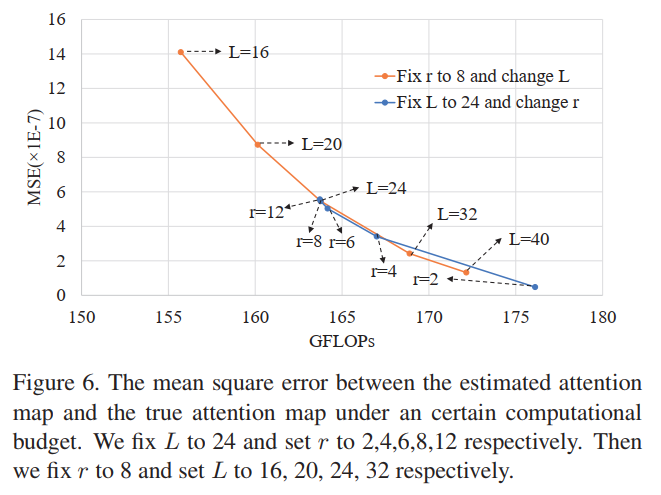
透过上图可以看出估计误差随着L的增大和r的减小而减小,与前面分析一致。同时,当r大于6时,继续增大r对估计误差和FLOPs影响不大。当r是小于或等于6,继续降低r失败将导致更大的增加而较小的减少错误;因此最终论文选择了r=8来进行实验。
4.2、Final Performance
透过下图可以看出K-mean对于原始DERT的性能损失太大,而本文提出的ACT在L=32是基本可以达到DERT的性能,而基于知识蒸馏的ACT-MTKD在精度和速度上又有了进一步的提升:
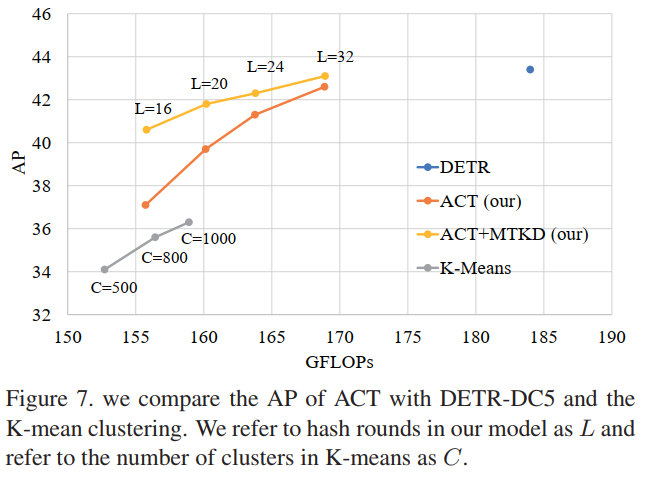
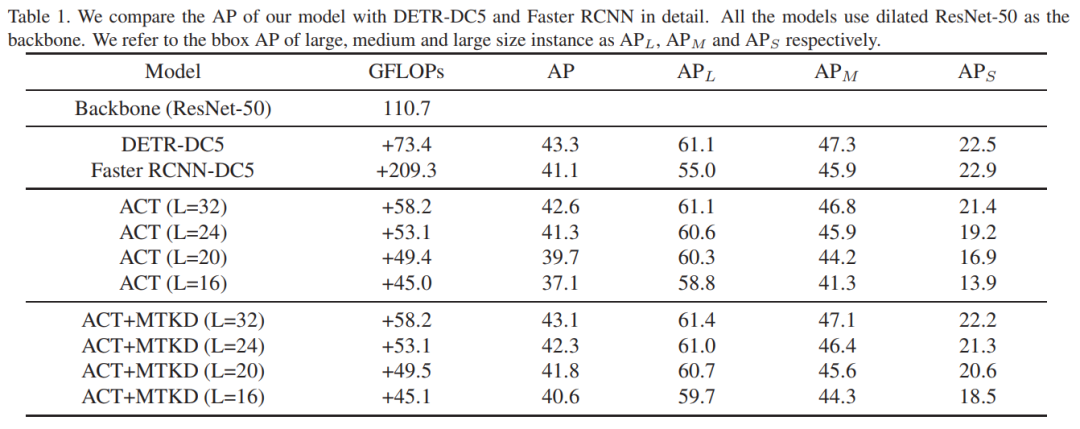
从下表可以看出,基于知识蒸馏的ACT在L=32时与原始DERT-DC5相当,但是其GFLOPs比DERT-DC5更低:
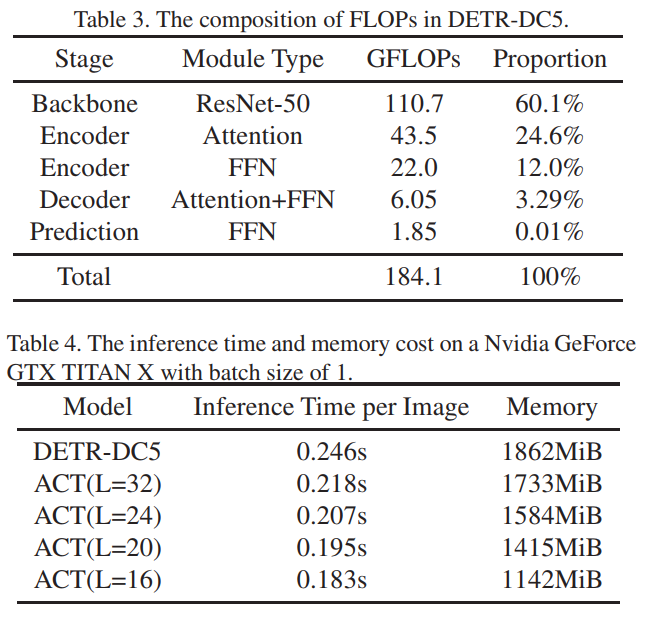
4.2、自适应聚类的可视化结果

参考
[1] End-to-End Object Detection with Adaptive Clustering Transformer
论文PDF下载
后台回复:ACT,即可下载上述论文PDF
目标检测综述下载
后台回复:目标检测二十年,即可下载39页的目标检测最全综述,共计411篇参考文献。
下载2
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4000人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!


