期待已久的—YOLO V3
好久不见各位研友(研究好友,不是考研的小伙伴,嘿嘿)!最近,因为题主学校事情比较繁忙,没有花更多的时间在我们的平台,希望关注支持我们的您,原谅我们更新的速度,希望大家继续支持我们,谢谢!
刚结束自己的手头事情,就想到给大家更新点东西,然后就想到了YOLO V3的东西,因为之前自己有认真研读,发现确实了不起的框架,但是如果有对V1和V2了解的,一定很熟悉了,今天我就和大家来分享下最近的框架——YOLO V3。
论文:https://pjreddie.com/media/files/papers/YOLOv3.pdf
代码:https://github.com/pjreddie/darknet
要不先来简单回忆下YOLO系列的框架。YOLO算法,从V1到V2,再到现在的V3系列,算法的性能在不断改进,以至于现在成为了开源通用目标检测算法的佼佼者。
一直以来,在计算机视觉领域有一个问题待解决,那就是如何检测两个距离很近的同类的目标或不同类目标?大多数的算法都会对输入的图像数据进行尺度变化,缩放到较小的分辨率情况下,但是一般在这总情况下只会给出一个Bounding Box,主要由于特征提取过程中将这总情况人为是一个目标。(本来就很近,一放缩之间的近距离越发明显了),但是实际这是两个相同或不同的目标。这个难题就是目标检测领域内的一个挑战。
对小目标检测,有很多新的算法,但是YOLO V3版本却做到了,它对这种距离很近的目标或者小目标有很好的鲁棒性,虽然不能百分百检测,但是这个难题得到了很大程度的解决。
这也是为什么写这篇文章的目的,在于见证一下这个算法的神奇。其实,百分百的检测,在我看来事实上是不存在的。
YOLO的V1和V2都不如SSD的算法,主要原因是V1的448尺寸和V2版本的416尺寸都不如SSD的300,以上结论都是实验测试的,V3版本的416应该比SSD512好,可见其性能。
对官方YOLO做了实验,实验中,采用同一个视频、同一张显卡,在阈值为0.3的前提下,对比了V3和V2的测试效果之后,有了下面两个疑问:
V3和V2的测试性能可以有较大的提升,但速度却没有降低?
V3性能上为啥有这么大的改进?对小目标检测变得这么好?
如果看了V3论文的,应该很清楚结果,如下:
Loss不同:将YOLO V3替换了V2中的Softmax loss变成Logistic loss,而且每个GT只匹配一个先验框;
Anchor bbox prior不同:V2用了5个anchor,V3用了9个anchor,提高了IOU;
Detection的策略不同:V2只有一个detection,V3设置有3个,分别是一个下采样的,Feature map为13*13,还有2个上采样的eltwise sum,Feature map分别为26*26和52*52,也就是说,V3的416版本已经用到了52的Feature map,而V2把多尺度考虑到训练的data采样上,最后也只是用到了13的Feature map,这应该是对小目标影响最大的地方;
backbone不同:V2的Darknet-19变成了V3的Darknet-53,这与上一个有关。
另外V3还是用了一连串的3*3、1*1卷积,其中,3*3的卷积增加channel,而1*1的卷积在于压缩3*3卷积后的特征表示,这波操作很具有实用性。
V2日志信息:
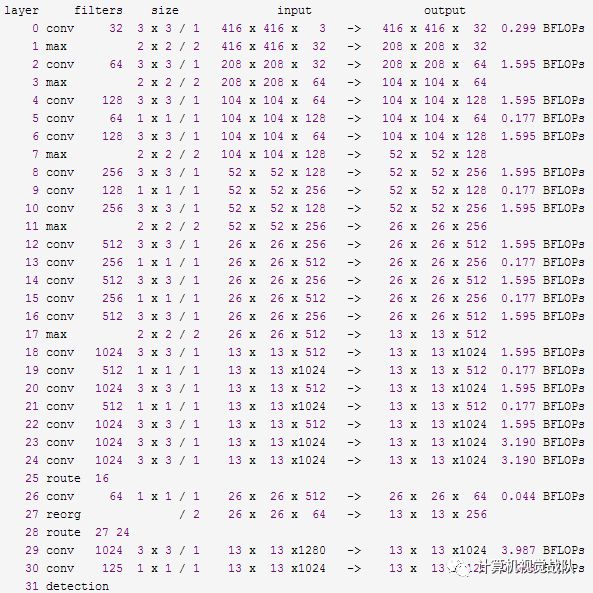
V3的日志信息:
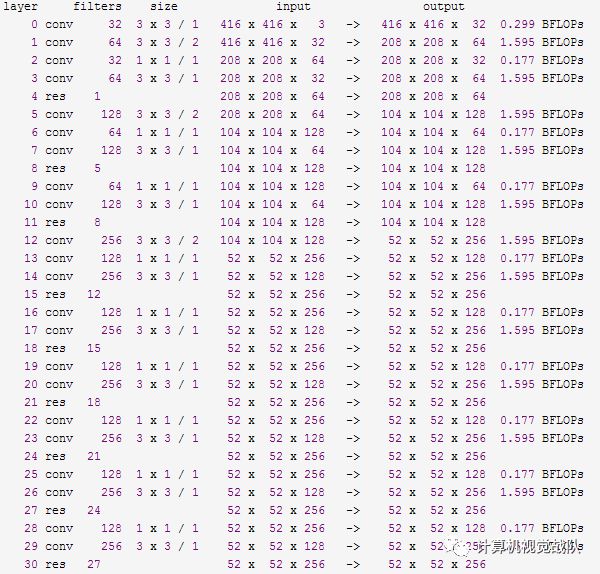



简单分析:
YOLO V2是一个纵向自上而下的网络架构,随着通道数目的不断增加,FLOPS是不断增加的,而V3网络架构是横纵交叉的,看着卷积层多,其实很多通道的卷积层没有继承性,另外,虽然V3增加了anchor centroid,但是对GT的估计变得更加简单,每个GT只匹配一个先验框,而且每个尺度只预测3个框,V2预测5个框,这样的话也降低了复杂度。
YOLO V3
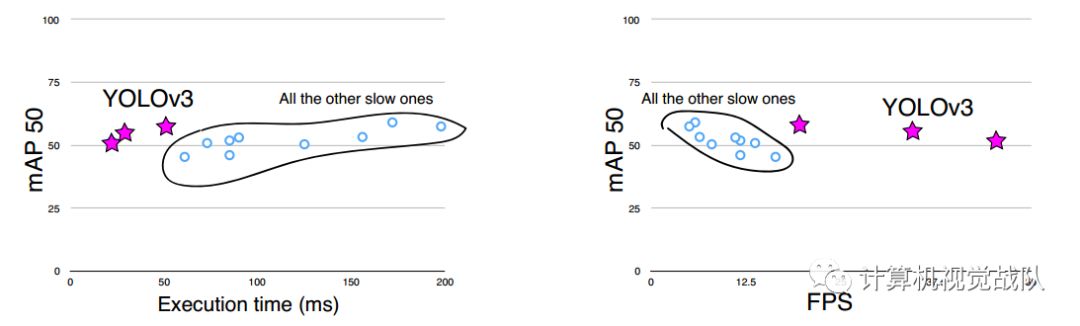
YOLO V3在Pascal Titan X上处理608x608图像速度达到20FPS,在 COCO test-dev 上 mAP@0.5 达到 57.9%,与RetinaNet的结果相近,并且速度快了4倍。 YOLO V3的模型比之前的模型复杂了不少,可以通过改变模型结构的大小来权衡速度与精度。 速度对比如下:
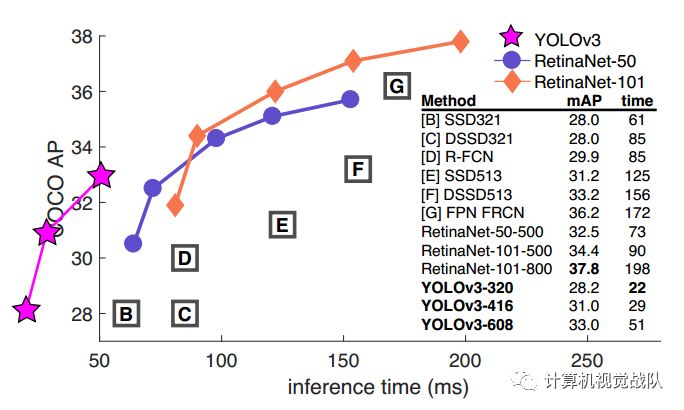
改进之处:
多尺度预测;
更好的基础分类网络和分类器。
多尺度预测
每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3中尺度。
尺度1:在基础网络之后添加一些卷积层再输出box信息;
尺度2:从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息,相比尺度1变大两倍;
尺度3:与尺度2类似,使用了32x32大小的特征图。
分类器-类别预测:
YOLO V3不使用Softmax对每个框进行分类,主要考虑因素有两个:
Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类;
Softmax可被独立的多个logistic分类器替代,且准确率不会下降。 分类损失采用binary cross-entropy loss。
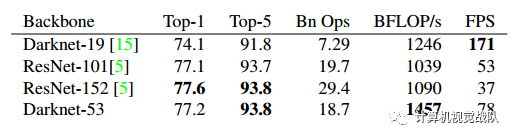
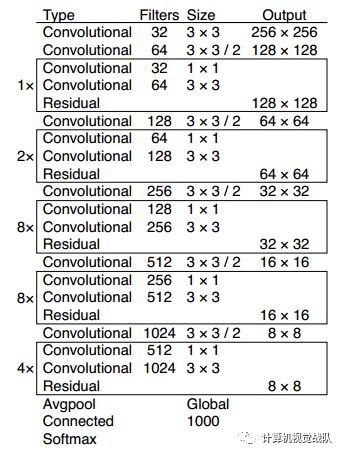
基础网络 Darknet-53
仿ResNet, 与ResNet-101或ResNet-152准确率接近,但速度更快.对比如下:
YOLO V3网络结构如下:
边框预测

优缺点分析:
优点:
快速,pipline简单,背景误检率低,通用性强。
YOLO V3对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。 但相比RCNN系列物体检测方法,YOLO V3具有以下缺点:
缺点:
识别物体位置精准性差,召回率低。
在每个网格中预测两个bbox这种约束方式减少了对同一目标的多次检测(R-CNN使用的region proposal方式重叠较多),相比R-CNN使用Selective Search产生2000个proposal(RCNN测试时每张超过40秒),YOLO仅使用7x7x2个。
实验结果:

自己也在数据集上做了一些实验:
用的数据集也是最近比较火的数据集——王者荣耀游戏数据。
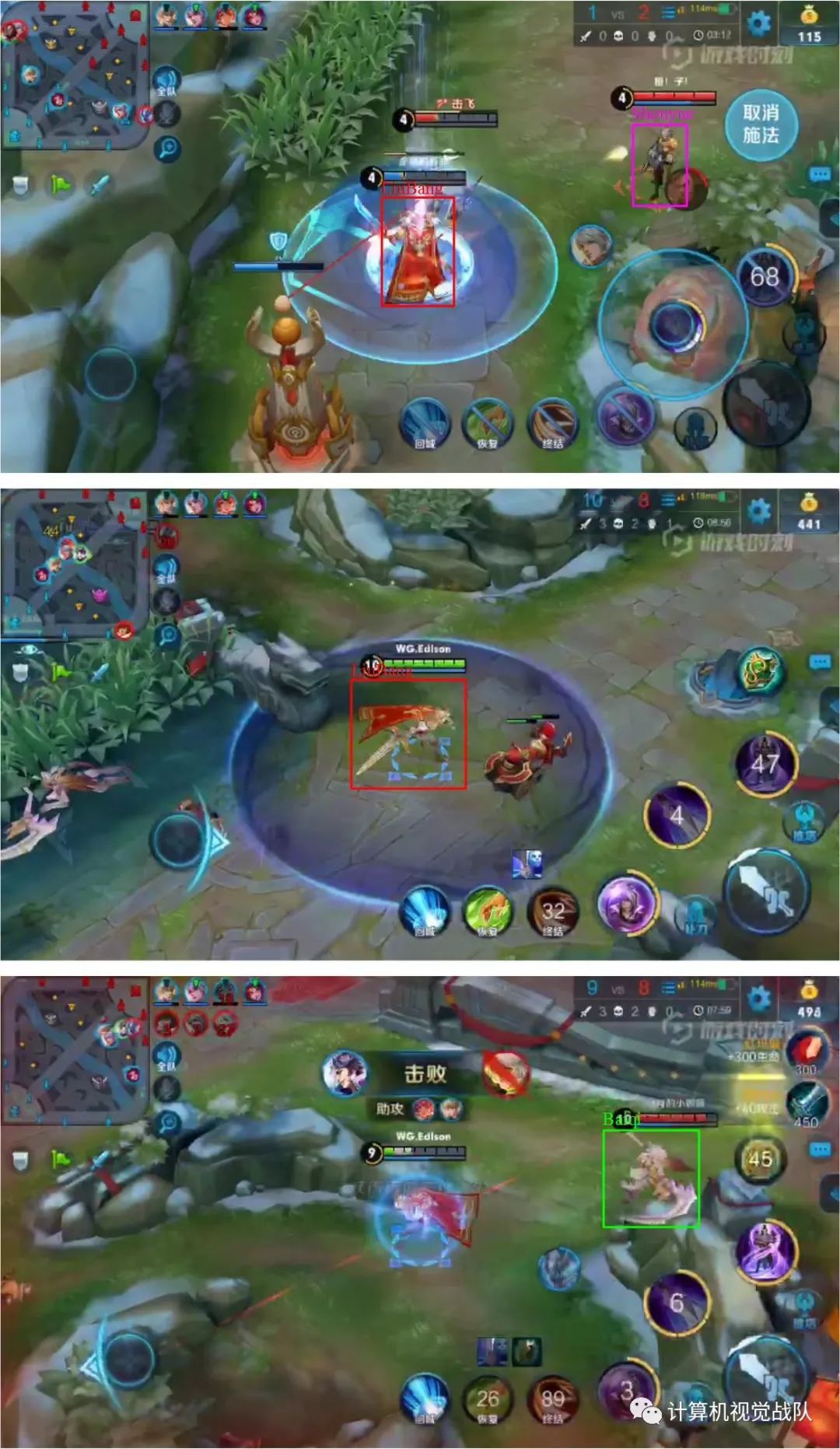
有兴趣的朋友,后续会将这个视频实时检测放在平台共享栏目,谢谢大家今天的阅读,谢谢!
如果感兴趣,请长按二维码关注,谢谢!



