学员分享 | 小哥哥和用YOLOv3做目标检测的故事「文末送课」

点击上方蓝字关注


前言
嗨,七友们,小七最近收到一位学员分享的个人成长笔记,他可是小七家的忠实粉丝吆,笔记内容写的很详细,和大家分享一哈,希望对你们有所帮助喔~~
小哥哥现在在一家央企的研究院做算法工程师实习生,前一阵子刚参加了我们的深度学习集训营,他说收获颇多噢,集训营结束后,现在参加了一个车辆检测的比赛,和大家分享下他参加比赛中对算法的一些理解和个人的心得体会。

01
比赛介绍:
1、名称:中国华录杯之交通卡口车辆信息精准识别
2、竞赛简介: 任务很简单的,把所有车子从图片中揪出来,嘿嘿,第一名奖金30w哟
3、比赛链接:
http://www.dcjingsai.com/common/cmpt/%E4%BA%A4%E9%80%9A%E5%8D%A1%E5%8F%A3%E8%BD%A6%E8%BE%86%E4%BF%A1%E6%81%AF%E7%B2%BE%E5%87%86%E8%AF%86%E5%88%AB_%E7%AB%9E%E8%B5%9B%E4%BF%A1%E6%81%AF.html

02
躺过各种乱七八糟的坑后,终于自己实现了tensorflow版的YOLOv3,目前比赛的准确率达到了0.85341,yolov3还是相当强劲的。
现在我来给大家介绍一下YOLOv3以及我在比赛中对算法的一些理解和小心得吧:
Yolo算法经过了三代更新,现在已经非常强大了,YOLOv3通过多尺度+上采样的方法克服小目标不敏感的问题(我还是觉得框的不够准,不过已经比前两作大部分无视小目标来的靠谱多了)
先来一个检测效果看看:
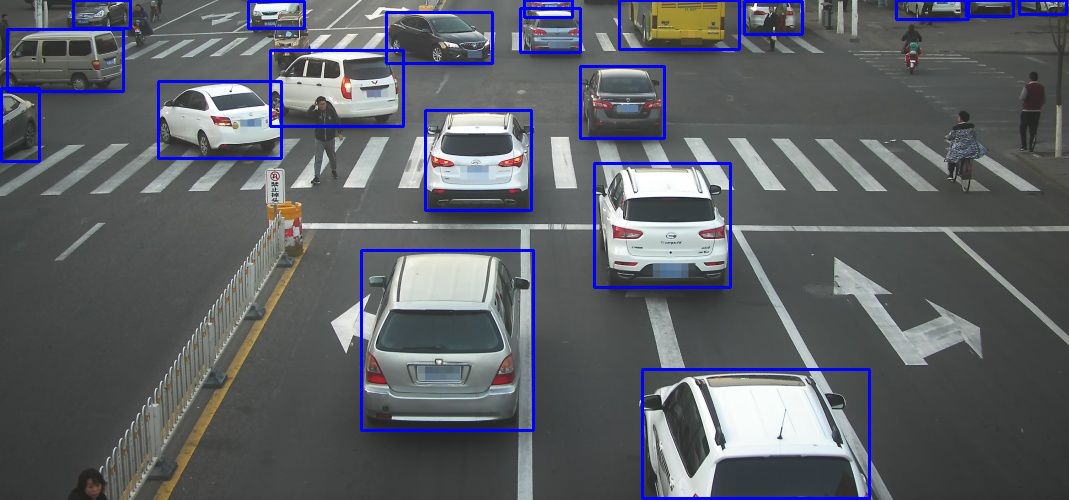
这个效果图是用YOLOv3做的车辆识别,训练集1w测试集5k,目前准确率是0.838

03
网络介绍:
1.DarkNet53
Yolov3使用的特征抽取网络是DarkNet53
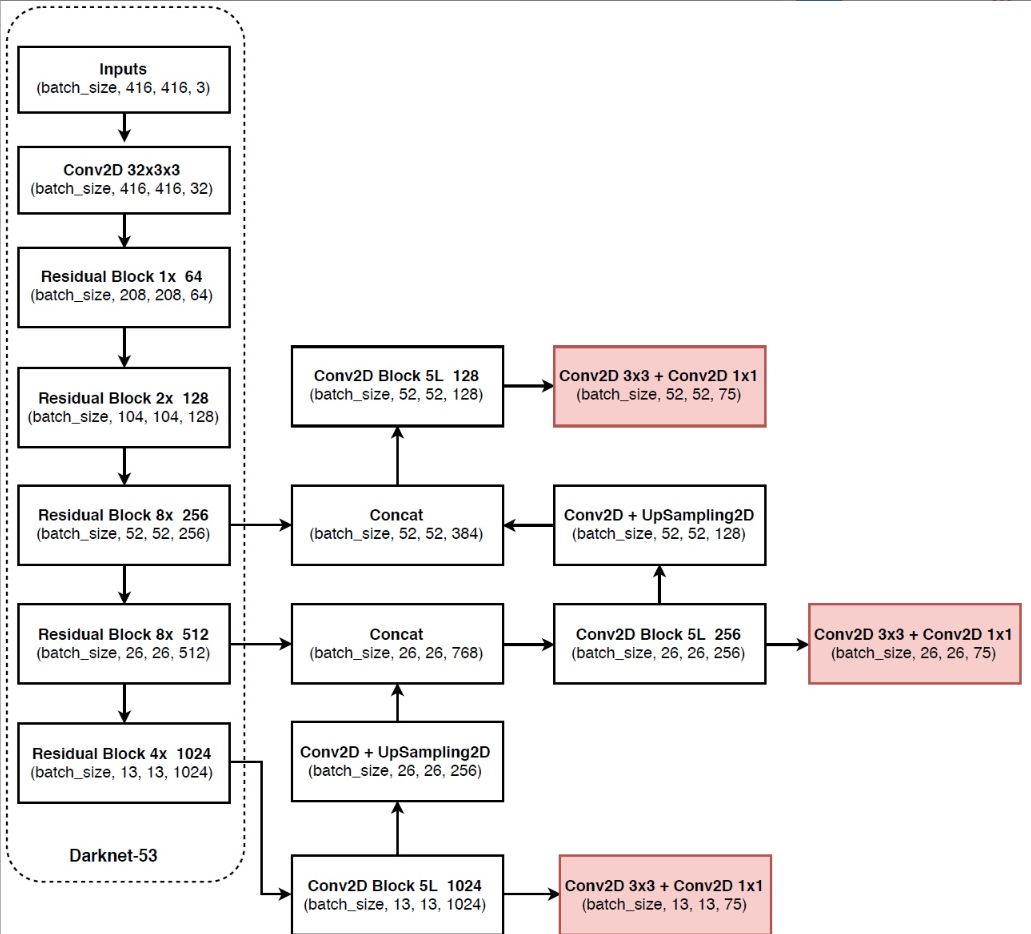
(1)这个网络使用了Resnet的设计思想,我发现残差网络训练的速度总是比单纯堆卷积快一些,我认为是残差连接让Resnet网络的训练平面变得更加平坦(个人认为,残差连接不仅缓解了梯度消失的问题,还去除了一些噪声,所以让训练更容易,我实验发现,densenet收敛的速度更快)
(2)没有pooling层
DarkNet53没有使用pooling层,缩小特征图尺度的方法是使用kernel size = 3x3 stride=2的小卷积层(我对此作了实验,把该卷积层换成2x2 max pooling,在同样的数据集与迭代3.5w次下,比使用卷积层准确率少1.2%),我认为作者没有使用max pooling的原因应该是防止max pooling把小目标给pooling没了,卷积可以保留小目标的信息,毕竟yolo算法本身对小目标的检测就不那么好使
(3)Darknet53有三个尺度被分别用来做检测:
13x13 26x26 52x52
他们之间使用上采样拼接在一起,目的是让大尺度的特征图融合较深特征图信息,因为浅层特征对小目标的信息保留做的更好,较深的特征图对目标的识别效果更好,融合之后可以弥补浅层特征的劣势(我在训练中发现,三个尺度的avg iou是52的最高,其次是26,最差的是13,但是confidence是52的检测层更不容易收敛,其次是26,最后是13)
2.Yolo v3的loss
Yolov3的每一个grid cell输出为:
grid cell attr = (5 + 类别数量)* 3
5 = 一个置信度confidence + 四个位置信息xywh
3 = 三个anchor
▶ loss分为3个部分
(1)坐标损失
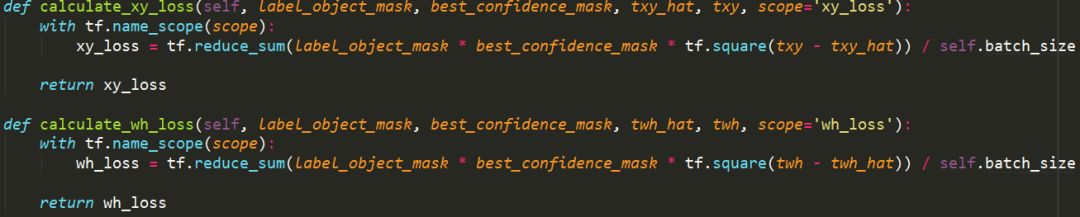
Yolov3的xy是目标中心相对于grid cell左上角的偏移量
Wh是经过指数变换和anchor box的比例的乘积后得到的
如下图:

在yolov3中一个grid cell有三个anchor,当目标的中心点落在该grid cell中时,这个grid cell就对这个目标负责,在选择计算xywh的loss时,选择三个anchor中confidence最高的那个anchor计算和ground truth的损失,如果没有目标中心点落在该grid cell中,则不计算xywh的loss。
(2)置信度损失

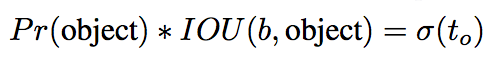
置信度confidence,是网络直接给出的, 是网络直接给出的, 是网络直接给出的(重要的事情说三遍)。
经过一个sigmoid就可以使用了,不用自己去计算,在计算confidence loss的时候如果有目标的中心点落在grid cell中,接着从三个anchor中挑出和ground truth的iou最高的那个anchor的confidence做有目标的置信度损失(object_confidence_loss)计算
没有被选到的另外2个anchor的confidence归为没有目标的置信度损失(no_object_confidence_loss)计算,
在计算no_object_confidence_loss时,如果没有被选到的两个anchor与ground truth的iou高于设定的阈值,则忽略该anchor的no_object_confidence_loss的计算。
没有目标的grid cell的confidence直接计算no_object_confidence_loss
(3)分类损失

在Yolov3中使用binary_crossentropy作为分类的损失函数,在前两代中使用的是softmax的交叉熵损失,这么做的理由是,通过最大熵原理得到的softmax默认类别两两之间是相互独立的,这样会造成一个问题。
假设,我们要检测一辆白色的奥迪a6,分类的类别中有奥迪a6和白色,如果使用softmax则默认是白色就不能是奥迪a6(虽然可以通过设置一个阈值选出两个概率最高的类别解决softmax类别相互独立问题,但是这样的效果不如binary_crossentropy好),使用binary_corssentropy则可以即是奥迪a6又是白色。
分类损失也只在grid cell中有目标的时候才计算,没有则不计算分类损失。
(4)损失的权重

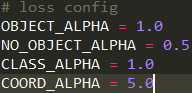
这里由于no_object的grid cell总是多于有目标的grid cell所以让no_object的loss缩小一半,xywh乘以5让他更重要,在训练时我发现三个尺度的有目标置信度损失总是先上升再下降,当没有目标的置信度损失下降到与有目标置信度损失值差不多时,有目标置信度损失开始下降,如果将no_object_alpha调小,效果会变差,貌似0.5是个不错的选择。
到这里,我觉得很多编程能力杠杠的童鞋们肯定已经可以自己实现全套loss了,不过我还是要提醒一下下,在tensorflow编程中多用切片少用循环,循环会增加cpu时间导致训练很慢很慢很慢,而且占用很多内存,我第一个版本的实现就是这样,仿佛写了个病毒。。。
(5)关于loss实现的一些细节
xy与置信度是需要通过sigmoid才能得到的,那么在实现loss时有两个选择,一个是暴力的使用均方差损失,一个是使用sigmoid_cross_entropy,我经过试验发现,使用均方差损失的效果要好于sigmoid_cross_entropy,收敛的更快些。

04
训练数据组织:
Yolo v3一共有三个尺度 13 26 52
输出的tensor纬度为:
(batch_size, 13, 13, (5+num_class)*3)
(batch_size, 26, 26, (5+num_class)*3)
(batch_size, 52, 52, (5+num_class)*3)
我在组织数据的时候同样将ground truth按照下面的公式缩放到了和网络输出的xywh,然后按照输出纬度组织好,label的tensor纬度为:
(batch_size, 13, 13, (5+num_class))
(batch_size, 26, 26, (5+num_class))
(batch_size, 52, 52, (5+num_class))
这里不乘3是因为每个grid cell的三个anchor都和一共ground truth比较,所以不用乘3。

05
训练:
我使用了两种方法训练
(1)三个尺度一起训练,结果发现同样迭代次数下最大尺度的有目标置信度损失和xy损失收敛很慢,而且下降不多。
(2)三个尺度交替训练13迭代5次,26迭代10次,52迭代20次,这样训练情况有所改善。
我在训练的最后几个epoch将数据增强的一些样本没迭代一个epoch撤掉一种,直到最后使用没有增强的数据训练(为了预测时不作数据增强),这样做的效果要比直接换上没有数据增强的数据在同样的迭代次数下效果要好0.8%。
一开始我使用Adam让其快速下降,最后的几个epoch使用SGD微调,这样比从头使用Adam一路到底效果要好一些。
其实。。。我觉得这个比赛就是在拼显卡。。。DarkNet53小显卡根本跑不动的。
关于模型压缩,我把DarkNet53割了一半,通过知识蒸馏压缩模型,fps从23.53提升到了29.11,后面发现nms是一个很耗时间而且难调的东西,还没想到什么好的改进方法。

06
Yolo v3改进的一些脑洞
Yolov3对小目标的检测不太好,我想是不是可以通过再52的特征层输出时加上一个空洞卷积,提高感受野,提高小目标的检测准确率
或者把残差连接换成密集型连接?类似densenet
以上都没试验过,是我的胡思乱想。。。
童鞋们有空多来七月逛逛,想当初我是一个小白,经过深度学习集训营后也能自己实现复杂算法了,yolov3的介绍就到此结束了,大家记得多多关注七月在线吖。

以上就是小哥哥的分享啦,小伙伴们看了有什么想法呢,以及你在工作或学习中参加过哪些【比赛或课程】,遇到了哪些有趣的事,都可以一起来和小七分享。欢迎在下方留言评论说出你的【参赛体会或学习心得】,有福利噢。
【奖励】:
评论区的个人留言的点赞数量排名前3名(top3)的亲,每人各送平台任意一个在线课程(不包括集训营和就业班)
【活动时间】
2018年7月25日—2018年7月30日(12:00)
【其它说明】:
1、中奖结果公布后,获得课程的亲请添加客服微信:julyedukefu_02,备注课程+微信昵称。
2、活动结束后会尽快安排送课程。
今日推荐:为了帮助大家更多的学习课程的相关知识,我们特意推出了深度学习系列课程。

更多资讯
请戳一戳



点击“阅读原文”,可在线报名



