厉害|YOLO比R-CNN快1000倍,比Fast R-CNN快100倍的实时对象检测!

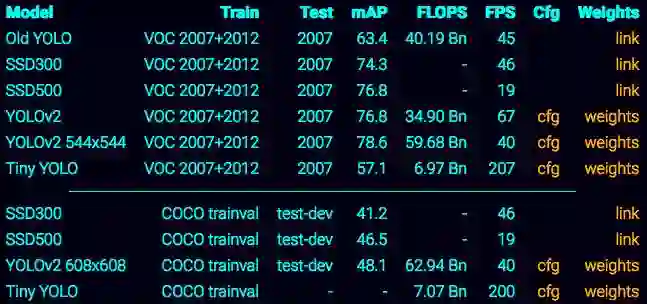
YOLO是一个最先进的实时对象检测系统。在Titan X上,它处理40-90 FPS的图像,并且在COCO测试开发人员的VOC 2007上具有78.6%的mAP和48.1%的mAP。
怎么运行?
先前的检测系统重新利用分类器或定位器进行检测。他们将模型应用于多个位置和比例的图像。图像的高评分区域被认为是检测。
我们使用完全不同的方法。我们将单个神经网络应用于完整图像。该网络将图像划分为区域并且预测每个区域的边界框和概率。这些边界框由预测概率加权。

我们的模型比基于分类器的系统有几个优点。它在测试时间看整个图像,所以它的预测是通过图像中的全局上下文来通知的。它也可以通过单个网络评估进行预测,而不像像R-CNN这样的系统,需要数千个单个图像。这使得它非常快,比R-CNN快1000倍,比Fast R-CNN快 100倍。有关完整系统的更多信息,请参阅我们的论文(https://arxiv.org/abs/1612.08242)。
R-CNN:https://github.com/rbgirshick/rcnn
Fast R-CNN:https://github.com/rbgirshick/fast-rcnn
版本2中有什么新功能?
YOLOv2使用一些技巧来改善训练并提高性能。像Overfeat和SSD我们使用完全卷积模型,但是我们仍然训练整个图像,而不是硬的负面。像更快的R-CNN,我们调整边界框上的先验,而不是直接预测宽度和高度。然而,我们仍然直接预测x和y坐标。完整的细节在我们的论文中(https://arxiv.org/abs/1612.08242)。
使用预培训模型进行检测
这篇文章将引导您使用预培训模型使用YOLO系统检测对象。如果你还没有安装Darknet,可以先阅读安装说明(https://pjreddie.com/darknet/install/)。或者直接运行:
git clone https://github.com/pjreddie/darknet cd darknet make
简单!您已经在cfg/子目录中具有YOLO的配置文件。你必须在这里下载预先训练的体重文件(258 MB)。或者只是运行这个:
wget https://pjreddie.com/media/files/yolo.weights
然后运行检测器!
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg
你会看到一些这样的输出:
layer filters size input output 0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 1 max 2 x 2 / 2 416 x 416 x 32 -> 208 x 208 x 32 ....... 29 conv 425 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 425 30 detection Loading weights from yolo.weights...Done! data/dog.jpg: Predicted in 0.016287 seconds. car: 54% bicycle: 51% dog: 56%
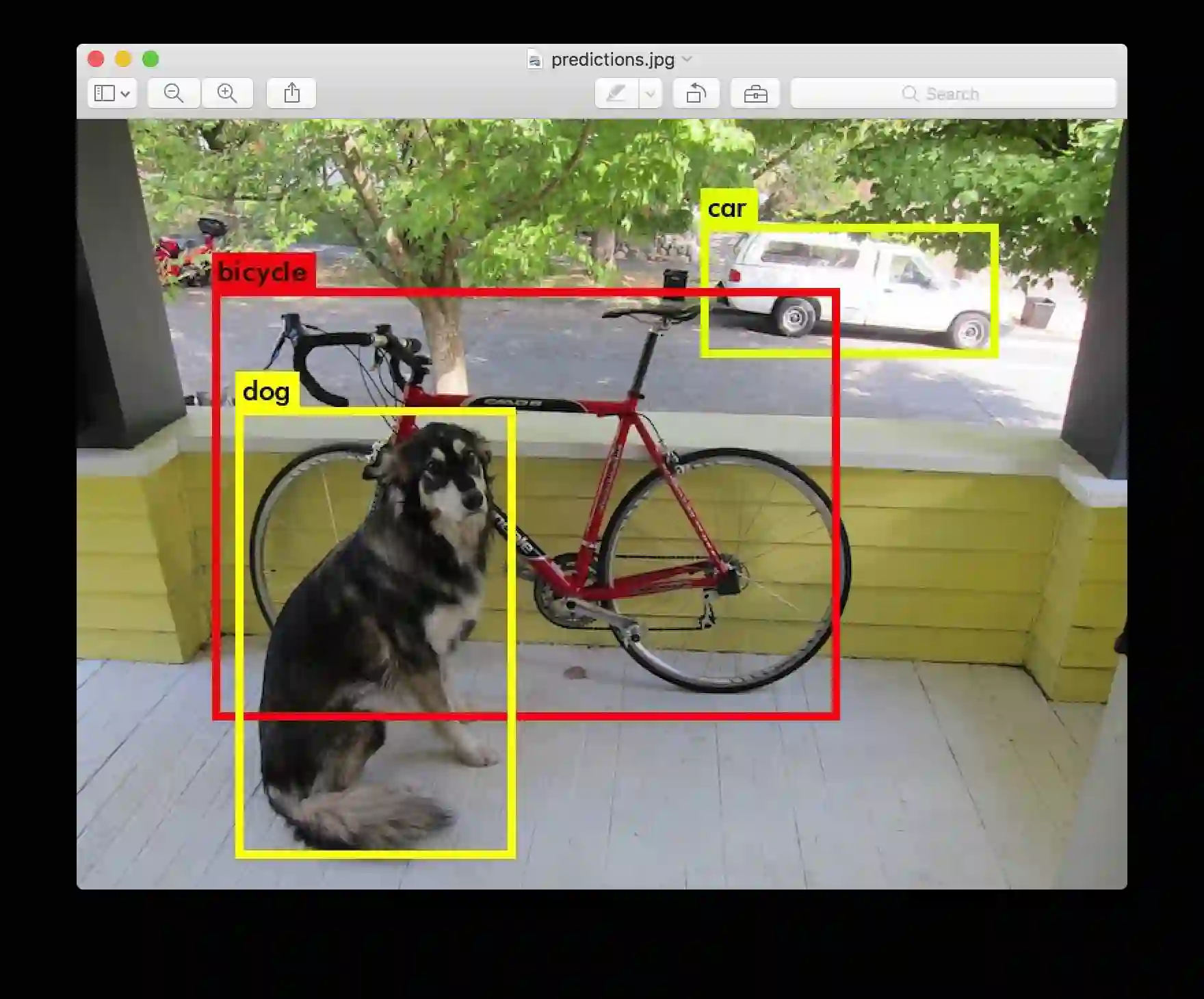
Darknet打印出它检测到的对象,秘密,以及找到它们需要多长时间。我们没有编译Darknet,OpenCV不能直接显示检测。相反,它可以节省predictions.png。您可以打开它来查看检测到的对象。由于我们在CPU上使用了Darknet,所以每个图像需要大约6-12秒。如果我们使用GPU版本,会更快。
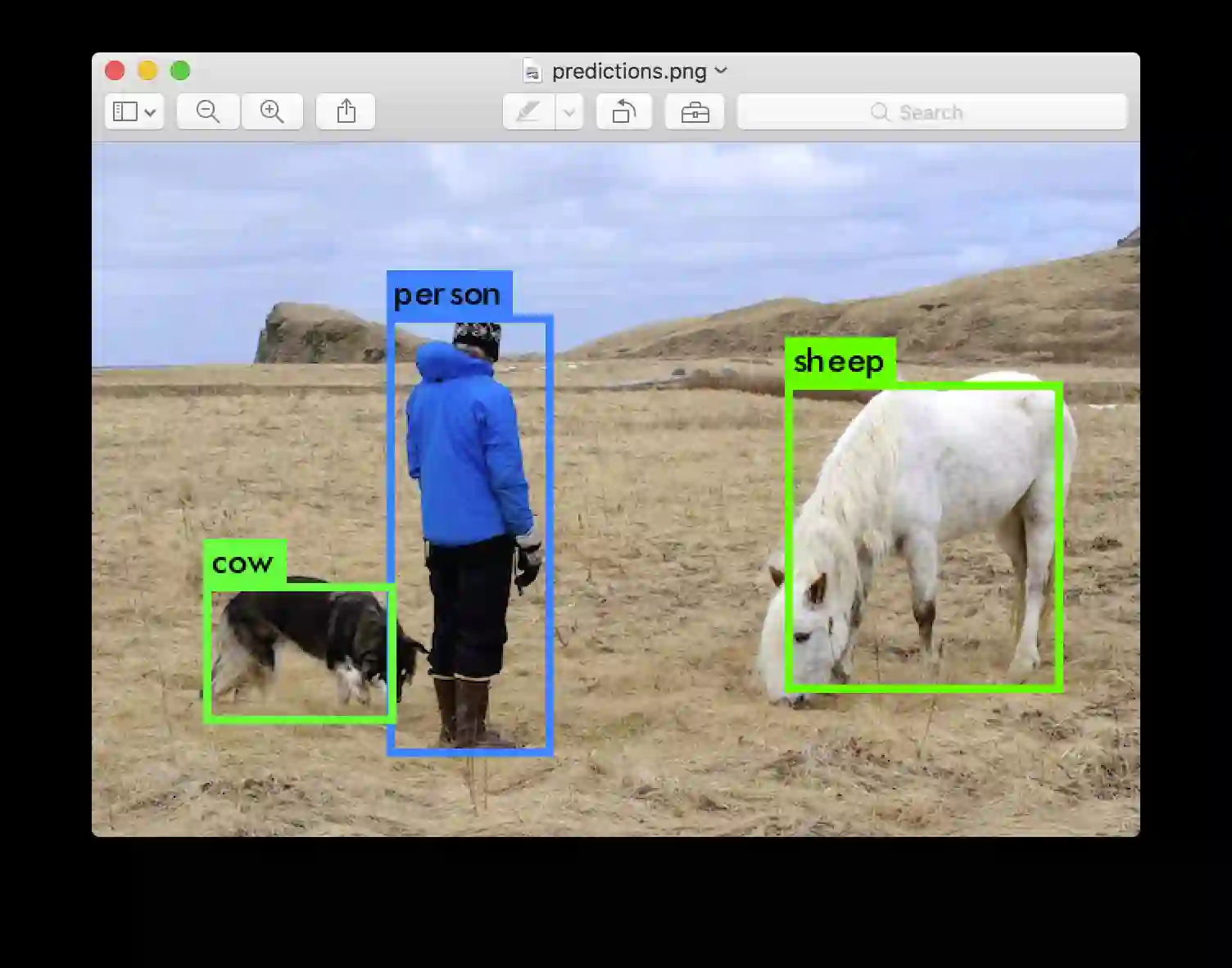
我已经使用一些示例图像来尝试:data/eagle.jpg,data/dog.jpg,data/person.jpg,或data/horses.jpg!
该detect命令是通用版本的缩写。它相当于命令:
./darknet detector test cfg/coco.data cfg/yolo.cfg yolo.weights data/dog.jpg
如果你想要做的是在一个图像上运行检测,但是知道你想要做其他的事情,比如在网络摄像头上运行(稍后会看到:https://pjreddie.com/darknet/yolo/#demo),这是很有用的。
多张图片
不是在命令行上提供图像,您可以将其留空以尝试连续的多个图像。相反,当配置和权重完成加载时,您将看到一个提示:
./darknet detect cfg/yolo.cfg yolo.weights layer filters size input output 0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 1 max 2 x 2 / 2 416 x 416 x 32 -> 208 x 208 x 32 ....... 29 conv 425 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 425 30 detection Loading weights from yolo.weights ...Done! Enter Image Path:
输入图像路径,data/horses.jpg使其具有该图像的预测框。
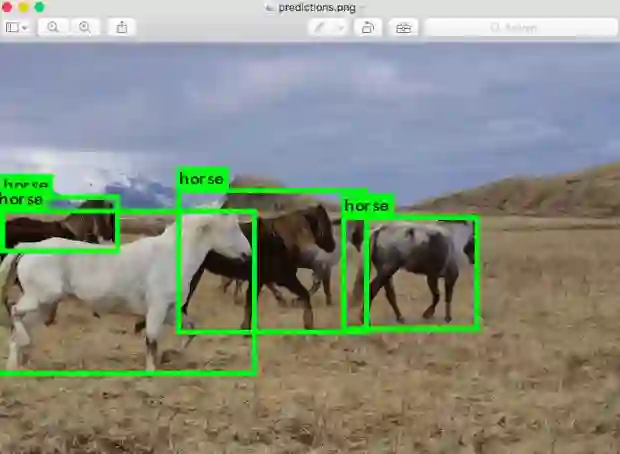
一旦完成,它将提示您有更多路径尝试不同的图像。使用Ctrl-C一旦你完成退出程序。
更改检测阈值
默认情况下,YOLO仅显示以0.25以上的置信度检测到的对象。您可以通过将该-thresh <val>标志传递给该yolo命令来进行更改。例如,要显示所有检测,您可以将阈值设置为0:
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg -thresh 0
哪个产生:
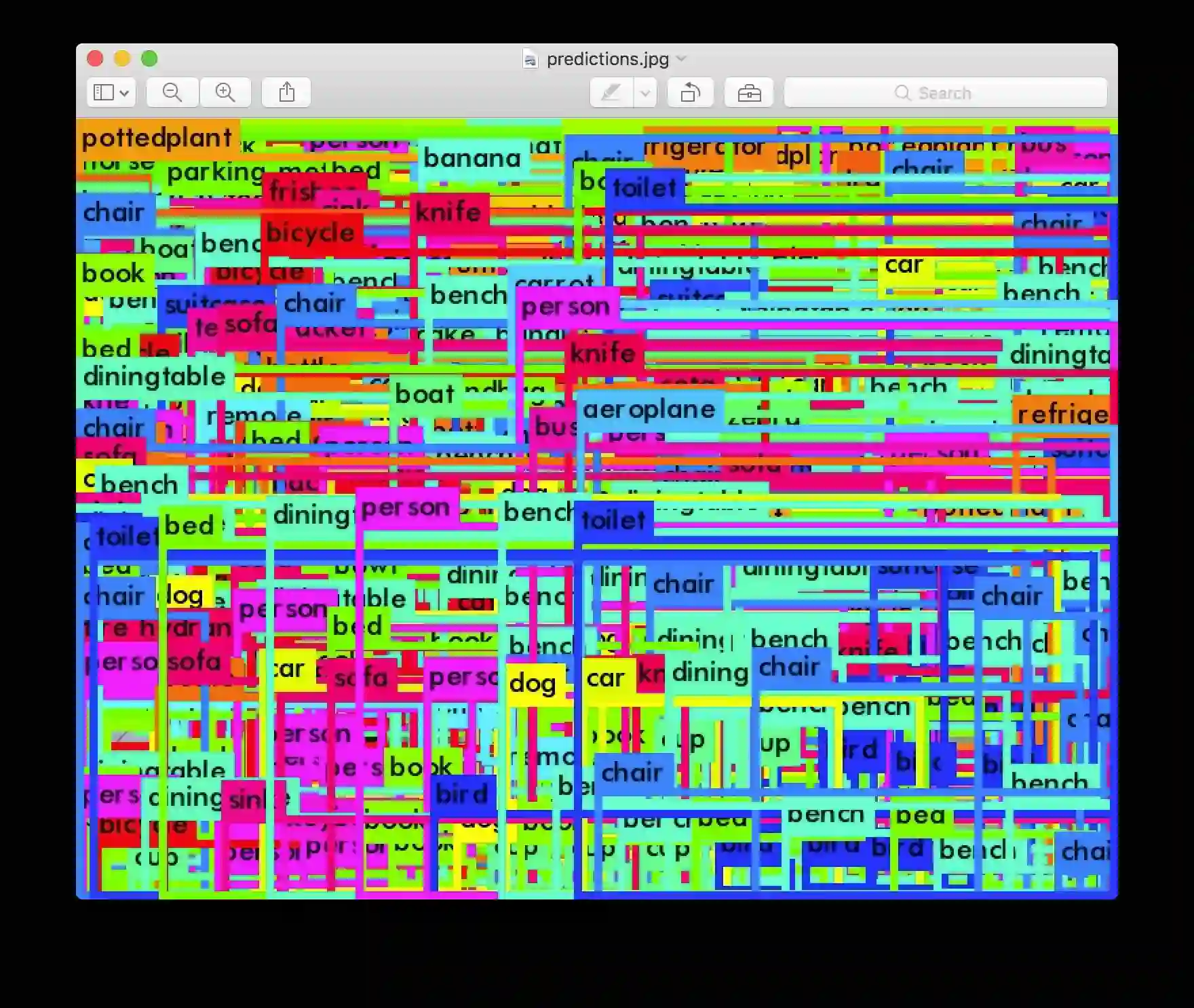
所以这显然不是特别有用,但你可以将其设置为不同的值来控制什么被模型阈值化。
微型YOLO
微型YOLO基于Darknet参考网络,并且比正常的YOLO型号快得多但不太准确。使用VOC训练的版本:
wget https://pjreddie.com/media/files/tiny-yolo-voc.weights ./darknet detector test cfg/voc.data cfg/tiny-yolo-voc.cfg tiny-yolo-voc.weights data/dog.jpg
在GPU上运行> 200 FPS。
网络摄像头的实时检测
如果看不到结果,运行YOLO的测试数据并不是很有意思。而不是在一堆图像上运行它,让我们从网络摄像头的输入中运行它!
要运行此演示,您将需要使用CUDA和OpenCV编译Darknet。然后运行命令:
./darknet detector demo cfg/coco.data cfg/yolo.cfg yolo.weights
YOLO将显示当前的FPS和预测类以及在其顶部绘制的边框的图像。
您将需要连接到OpenCV可以连接的计算机的网络摄像头,否则它将无法正常工作。如果连接了多个网络摄像头,并想要选择要-c <num>使用的网络摄像头0,则可以通过标志来选择(OpenCV 默认使用网络摄像头)。
如果OpenCV可以读取视频,也可以在视频文件上运行它:
./darknet detector demo cfg/coco.data cfg/yolo.cfg yolo.weights <video file>
这就是我们如何制作YouTube视频。
训练YOLO VOC
如果您想玩不同的训练方式,超参数或数据集,您可以从头开始训练YOLO。以下是如何使其在Pascal VOC数据集上工作。
获取Pascal VOC数据
要训练YOLO,您将需要从2007年到2012年的所有VOC数据。您可以在这里找到数据链接。要获取所有数据,请创建一个目录以将其全部存储,并从该目录运行:
curl -O https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar curl -O https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar curl -O https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar tar xf VOCtrainval_11-May-2012.tar tar xf VOCtrainval_06-Nov-2007.tar tar xf VOCtest_06-Nov-2007.tar
现在将有一个VOCdevkit/子目录,其中包含所有VOC培训数据。
为VOC生成标签
现在我们需要生成Darknet使用的标签文件。Darknet想要.txt为每个图像提供一个文件,图中的每个地面实例对象的线条如下所示:
<object-class> <x> <y> <width> <height>
其中x,y,width,和height相对于图像的宽度和高度。要生成这些文件,我们将voc_label.py在Darknet的scripts/目录中运行该脚本。让我们再次下载,因为我们很懒惰。
curl -O https://pjreddie.com/media/files/voc_label.py python voc_label.py
几分钟后,此脚本将生成所有必需的文件。主要是它产生了很多的标签文件VOCdevkit/VOC2007/labels/和VOCdevkit/VOC2012/labels/。在您的目录中,您应该看到:
ls 2007_test.txt VOCdevkit 2007_train.txt voc_label.py 2007_val.txt VOCtest_06-Nov-2007.tar 2012_train.txt VOCtrainval_06-Nov-2007.tar 2012_val.txt VOCtrainval_11-May-2012.tar
文本文件像2007_train.txt列出该年份的图像文件和图像集。Darknet需要一个文本文件,其中包含您要训练的所有图像。在这个例子中,让我们训练除2007测试集之外的所有内容,以便我们可以测试我们的模型。跑:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
现在我们将所有2007年的班车和2012年的班车设置在一个大的列表中。这就是数据设置所需要做的一切!
修改Pascal数据的Cfg
现在去你的Darknet目录。我们必须更改cfg/voc.data配置文件以指向您的数据:
1 classes= 20 2 train = <path-to-voc>/train.txt 3 valid = <path-to-voc>2007_test.txt 4 names = data/voc.names 5 backup = backup
您应该将<path-to-voc>放置VOC数据的目录替换。
下载预训练卷积重量
对于训练,我们使用在Imagenet上预先训练的卷积重量。我们使用提取模型中的权重。您可以在这里下载卷积层的权重(76 MB)。
curl -O https://pjreddie.com/media/files/darknet19_448.conv.23
如果要自己生成预先训练的权重,请下载预先训练的Darknet19 448x448模型并运行以下命令:
./darknet partial cfg/darknet19_448.cfg darknet19_448.weights darknet19_448.conv.23 23
但是如果您只是下载权重文件,这样会更容易。
训练模型
现在我们可以训练了!运行命令:
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg darknet19_448.conv.23
训练YOLO COCO
如果您想玩不同的训练方式,超参数或数据集,您可以从头开始训练YOLO。以下是如何使其在COCO数据集上工作。
获取COCO数据
要培训YOLO,您将需要所有的COCO数据和标签。脚本scripts/get_coco_dataset.sh会为你做这个。找出要COCO数据并将其下载的地方,例如:
cp scripts/get_coco_dataset.sh data cd data bash get_coco_dataset.sh
现在你应该拥有为Darknet生成的所有数据和标签。
修改COCO的cfg
现在去你的Darknet目录。我们必须更改cfg/coco.data配置文件以指向您的数据:
1 classes= 80 2 train = <path-to-coco>/trainvalno5k.txt 3 valid = <path-to-coco>/5k.txt 4 names = data/coco.names 5 backup = backup
您应该<path-to-coco>将COCO数据放在目录下。
您还应该修改您的型号cfg进行培训,而不是进行测试。cfg/yolo.cfg应该是这样的:
[net] # Testing # batch=1 # subdivisions=1 # Training batch=64 subdivisions=8 ....
训练模型
现在我们可以训练了!运行命令:
./darknet detector train cfg/coco.data cfg/yolo.cfg darknet19_448.conv.23
如果要使用多个gpus运行:
./darknet detector train cfg/coco.data cfg/yolo.cfg darknet19_448.conv.23-gpus 0,1,2,3
如果要从检查点停止并重新开始训练:
./darknet detector train cfg/coco.data cfg/yolo.cfg backup/yolo.backup-gpus 0,1,2,3
老YOLO网站发生了什么?
如果您使用YOLO版本1,您仍然可以在这里找到该网站:https://pjreddie.com/darknet/yolov1/
引用
如果您在工作中使用YOLOv2,请引用我们的论文!
@article{redmon2016yolo9000,
title={YOLO9000: Better, Faster, Stronger},
author={Redmon, Joseph and Farhadi, Ali},
journal={arXiv preprint arXiv:1612.08242},
year={2016}
}
参考:https://github.com/philipperemy/yolo-9000





