理论计算机科学家 Boaz Barak:深度学习并非“简单的统计”,二者距离已越来越远

极市导读
Boaz Barak 通过展示拟合统计模型和学习数学这两个不同的场景案例,探讨其与深度学习的匹配性;他认为,虽然深度学习的数学和代码与拟合统计模型几乎相同,但在更深层次上,深度学习中的极大部分都可在“向学生传授技能”场景中被捕获。 >>加入极市CV技术交流群,走在计算机视觉的最前沿


场景A:拟合统计模型
 的得到形式是
的得到形式是
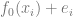 ,其中
,其中
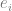 是对应的噪声,为简单起见使用了加性噪声,而
是对应的噪声,为简单起见使用了加性噪声,而
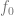 是正确的真实标签。)
是正确的真实标签。)
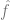 拟合到数据中,使
的经验风险最小。也就是说,我们使用优化算法来找到
的最小化数量
拟合到数据中,使
的经验风险最小。也就是说,我们使用优化算法来找到
的最小化数量
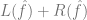 ,其中
,其中
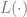 是一个损失项(捕捉
是一个损失项(捕捉
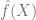 距离 y 有多近),
距离 y 有多近),
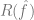 是一个可选的规范化项 (试图使得
偏向更简单的模型)。
是一个可选的规范化项 (试图使得
偏向更简单的模型)。
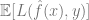 很小(这种预测是基于实验数据所在的总体数据来获得的)。
很小(这种预测是基于实验数据所在的总体数据来获得的)。
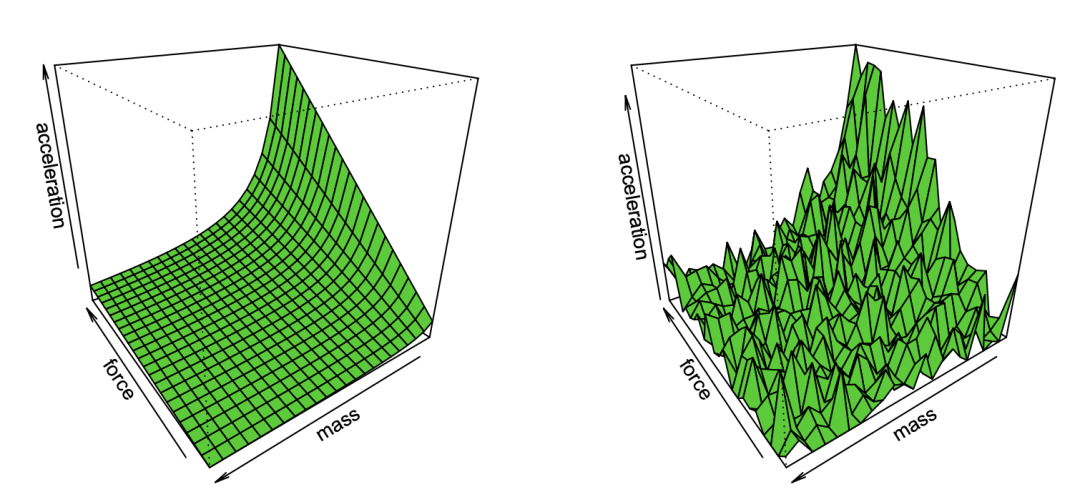
图注:Bradley Efron经过对噪音的观察所复现的牛顿第一定律漫画
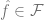 来实现。F 的类越大,偏差越小,当
来实现。F 的类越大,偏差越小,当
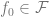 ,偏差甚至可以是零。然而,当 F 类越大, 则需要越多样本来缩小其成员范围,从而算法输出模型中的方差就越大。总体泛化误差是偏差项和方差贡献的总和。
,偏差甚至可以是零。然而,当 F 类越大, 则需要越多样本来缩小其成员范围,从而算法输出模型中的方差就越大。总体泛化误差是偏差项和方差贡献的总和。
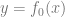 和
和
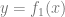 ),比独立学习单个更难。
),比独立学习单个更难。
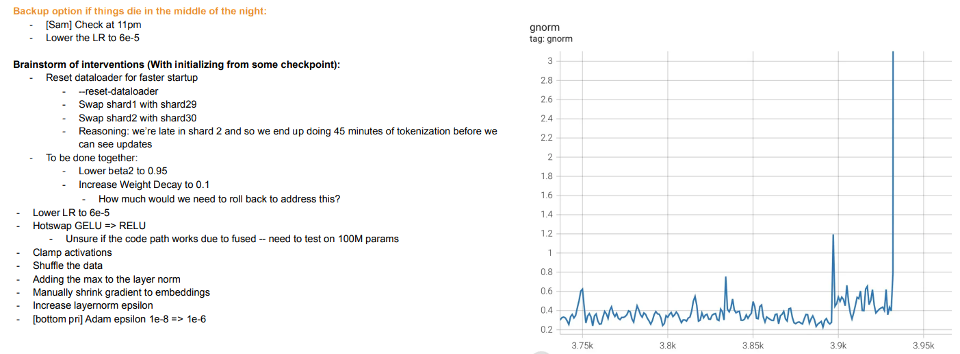
 ,其所需的数据点数量在某些参数 k 下以
,其所需的数据点数量在某些参数 k 下以
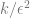 的形式拓展。在这种情况下,需要大约 k 个样本来“起飞”,而一旦这样做,则会面临收益递减的制度,即假设花耗 n 个点来达到(比如)90%的准确度,那么想要将准确度提高到95%,则大约需要另外 3n 个点。一般来说,随着资源增加(无论是数据、模型的复杂性,还是计算),我们希望捕捉到更多更细的区别,而不是解锁新的质量上的能力。
的形式拓展。在这种情况下,需要大约 k 个样本来“起飞”,而一旦这样做,则会面临收益递减的制度,即假设花耗 n 个点来达到(比如)90%的准确度,那么想要将准确度提高到95%,则大约需要另外 3n 个点。一般来说,随着资源增加(无论是数据、模型的复杂性,还是计算),我们希望捕捉到更多更细的区别,而不是解锁新的质量上的能力。
场景B:学习数学
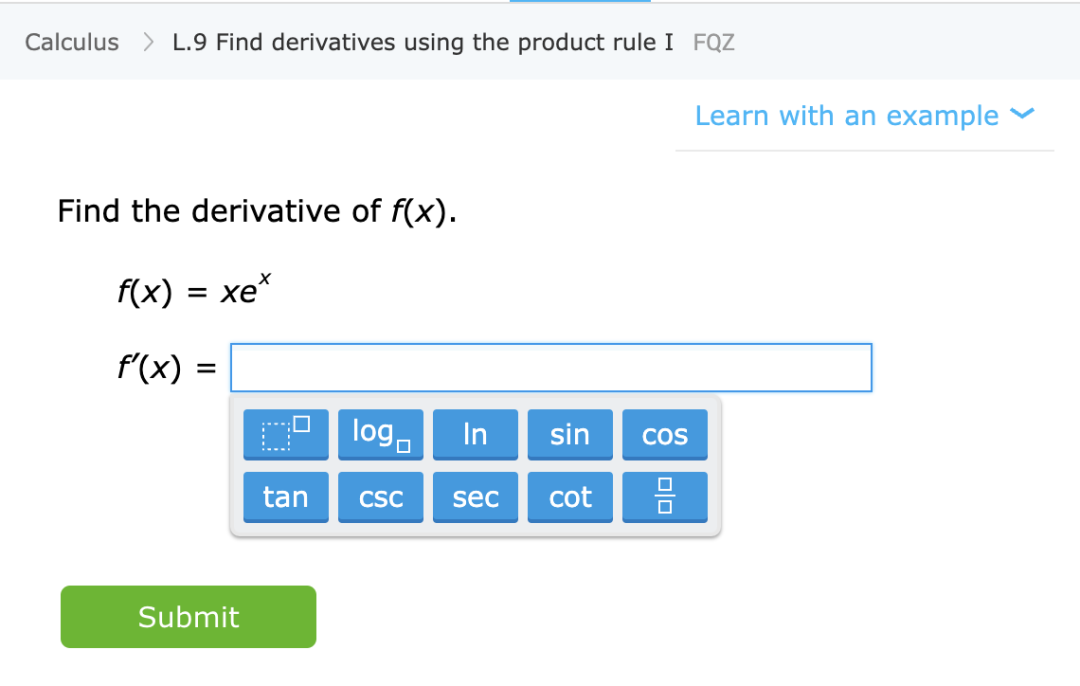
图注:从IXL 网站学习特定数学技能的练习

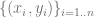 ,其中
,其中
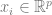 是某个数据点(例如具体的图像)、
是某个数据点(例如具体的图像)、
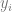 是一个标签。
是一个标签。
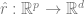 ,这个函数的训练只使用数据点
,这个函数的训练只使用数据点
 而不使用标签,通过最小化某种类型的自监督损失函数。这种损失函数的例子是重建或画中画(从另一个输入 x 的某些部分恢复)或对比学习(找到
而不使用标签,通过最小化某种类型的自监督损失函数。这种损失函数的例子是重建或画中画(从另一个输入 x 的某些部分恢复)或对比学习(找到
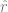 使
使
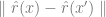 显著更小,当
显著更小,当
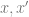 是同一个数据点的增量时,并列关系比两个随机点的并列关系要小得多)。
是同一个数据点的增量时,并列关系比两个随机点的并列关系要小得多)。
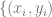 来拟合线性分类器
来拟合线性分类器
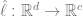 (其中 C 是类的数量),使交叉熵损失最小。最终的分类器得出了
(其中 C 是类的数量),使交叉熵损失最小。最终的分类器得出了
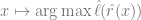 的映射。
的映射。
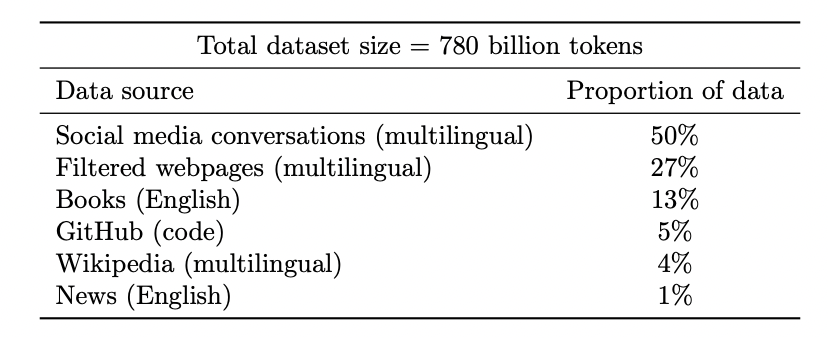
图注:谷歌 PaLM 模型的数据集

情况1:监督学习
 ,都可以将通过自监督训练的深度 d 模型的首 k 层数与监督模型的最后 d-k 层数“缝合”起来,并且使性能几乎保持原有水平。
,都可以将通过自监督训练的深度 d 模型的首 k 层数与监督模型的最后 d-k 层数“缝合”起来,并且使性能几乎保持原有水平。
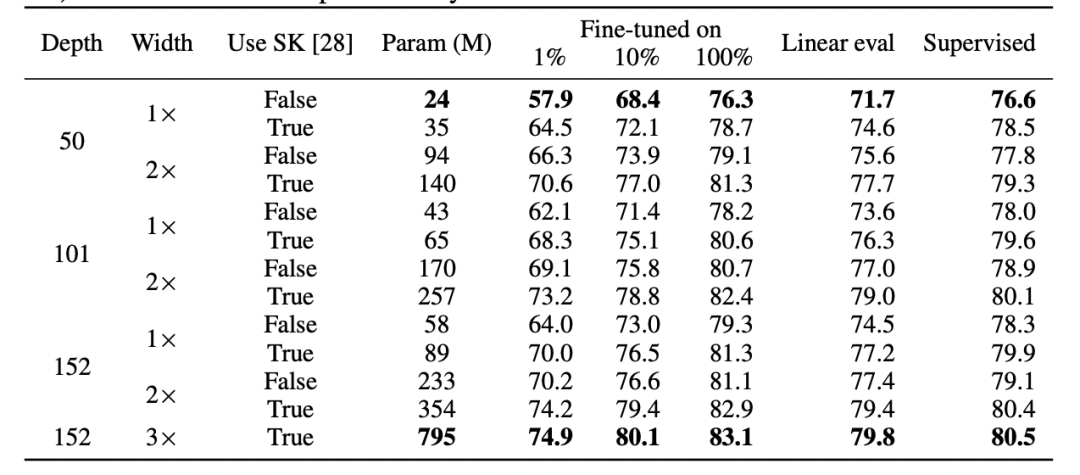
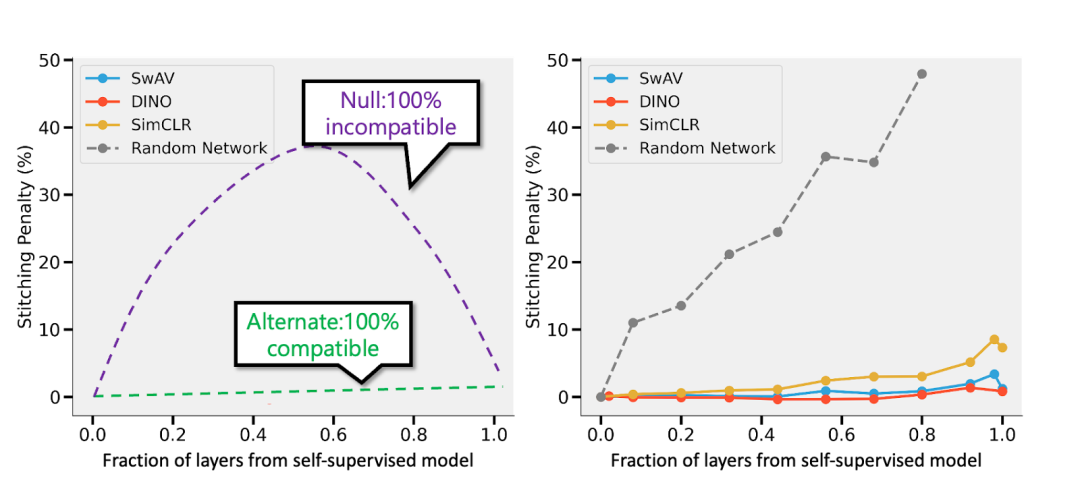
情况2:过度参数化
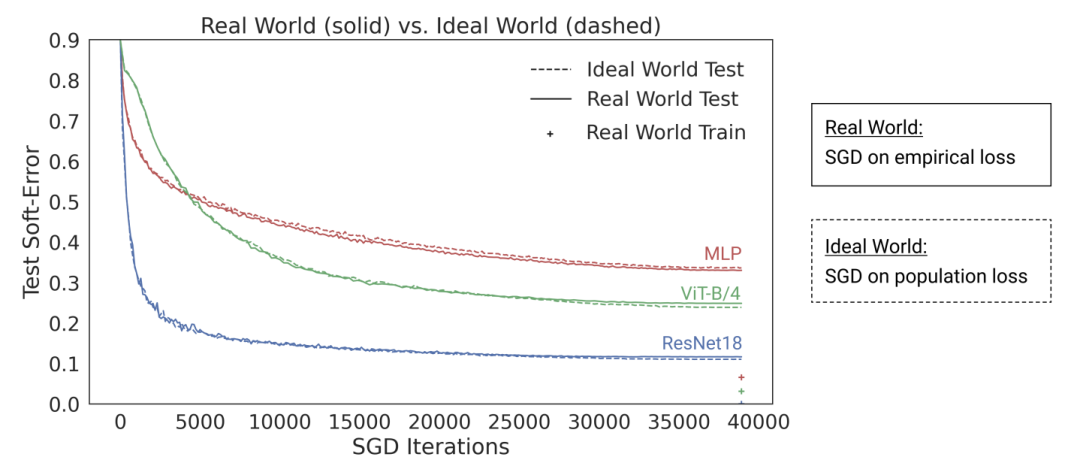
https://windowsontheory.org/2022/06/20/the-uneasy-relationship-between-deep-learning-and-classical-statistics/
公众号后台回复“ECCV2022”获取论文分类资源下载~

“
点击阅读原文进入CV社区
收获更多技术干货
登录查看更多
相关内容
专知会员服务
207+阅读 · 2020年2月16日




相关VIP内容
专知会员服务
207+阅读 · 2020年2月16日
相关资讯