深度学习,路在何方?

文 | Severus
最近,AI领域的三位图灵奖获得者Yoshua Bengio、Yann LeCun和Geoffrey Hinton共同发表了一篇文章,名为Deep Learning for AI,文中讨论了深度学习的起源、发展、成就及未来。
文章标题:
Deep Learning for AI
原文链接:
https://cacm.acm.org/magazines/2021/7/253464-deep-learning-for-ai/fulltext
小伙伴们也可以在 【夕小瑶的卖萌屋】订阅号后台回复关键词 【0712】 下载论文PDF~
今天我们有什么
得益于越来越便宜的算力,以及越来越海量的数据,加上各种机构做出了越来越简单易用的深度学习框架,如Theano、Torch、TensorFlow、PyTorch等,它们可以做自动求导,让训练深度学习模型变得更加简单。这一切因素带动了深度学习的火热。
深度学习在结构上的成功,则在于它的多层结构,可以进行重组、重构建浅层网络得到更加抽象的特征,而这些特征,用于最终的任务,如分类任务、生成任务等,就会变得足够的简单。但如果想得到合理的抽象特征,自然也就需要海量的数据来支撑。
在有标签数据充沛的领域,监督学习自然是会达到非常好的效果;在规则足够简单,且限制比较强的领域,强化学习也自然会有非常强势的表现(如下棋、游戏等)。但是现实世界显然不会是这么理想的,那么,利用迁移学习,将从数据充沛的任务中学习到的知识应用到一些数据不是那么够的任务中,就成为了下一步解决方案。那么迁移学习中的预训练任务,要怎么样去设计,才能得到一种对下游任务足够友好的通用表示,且数据可以足够多呢?
各个领域的人,尝试了各种无监督、自监督的方式,如NLP领域,有完形填空任务,即让模型填上文本中遮蔽掉的词,或改正错误的词;CV领域,则使用对比学习来得到更加鲁棒的表示(实际上,近年来也有将对比学习策略应用到NLP的工作,当然这些工作最大的问题仍是怎么样去定义对比学习的正例和负例)。还有一种自监督的学习方法是变分自动编码器(VAE),简单来讲,就是由编码器学习图片的表示,再用解码器还原这张图片(用这个表示去生成一张图片)。
以上是文章中对近期深度学习的工作进展的介绍,寥寥数字,远不及文章中所提全面,例如soft attention的成功、ReLU成功之谜,本文不再介绍,而比较关键的是要谈一谈深度学习的未来。
未来何去何从
机器学习研究,都会遵从一个强假设,即独立同分布假设,train集合和test集合需是相互独立且同分布的。当机器学习系统想要应用于产业中的时候,理想的情况自然也是训练样本和真实应用场景是同分布的(工业场景下不一定非得要独立,甚至,训练样本就在使用场景之中,促使一定程度的过拟合,可能才是工业比较希望的)。如果应用场景是足够窄,且数据足够多(有监督学习),或规则足够强(强化学习),这种理想情况是几乎可以实现的,但现实往往不尽如人意,也就是说,同分布的假设大概率要打破。
这也就导致了很多在实验任务中打出了不俗分数的模型,到了真实的使用场景中,往往会爆发这样或那样的问题,导致它无法应用。哪怕是已经非常神奇的自监督预训练模型或无监督预训练模型,在面对超出分布(out-of-distribution)的场景的时候,表现也会掣肘。
与深度学习模型不同,人就有着非常强大的领域迁移能力,且这种能力往往又不需要很多的样本,甚至仅仅需要一些规则(符号派的规则描述),就可以迅速适应一个新的领域。例如,如果看见一张以前完全没有见过的风格的照片,人大概也能分辨照片上面有什么,哪怕分辨不了,那他认识了这一张,也会迅速认识很多类似的照片。两个使用同样语言,但受到过不太一样的教育的人,在交流的时候,如果使用的是同一个语言,那么两个人大概率也能进行交流,只不过涉及到专业的背景时才可能会存在交流上的障碍;一个人在学习一个新的游戏的时候,可能仅仅需要理解规则,加上试玩一两次,就可以掌握这个游戏的基本玩法,后期对游戏规则的认识,或者学习技巧,也无非是扩充自己对这个游戏的认识。
所以,针对现有的深度学习系统,或许我们应该探索的方向是,怎样设计出一个能够很好地面对超出分布的机器学习系统。
关于这一问题,原文中提出了多种改善方向,包括
-
胶囊网络所使用的用相邻的成组神经元去表示实体 -
适应多种时间尺度的权重设计 -
高层次的认知。
这里我想要针对高层次的认知这一部分谈一下。
从“感知”到“认知”?
文中对高层次的认知的描述,是一种“想象”能力,将现在已经学习的知识或技能重新组合,重构成为新的知识体系,随之也重新构建出了一个新的假想世界(如在月球上开车),这种能力是人类天生就被赋予了的,在因果论中,被称作“反事实”能力。也正如Judea Pearl所代表的因果论体系中所提到的因果关系之梯,观察(感知)、干预、反事实(认知)。
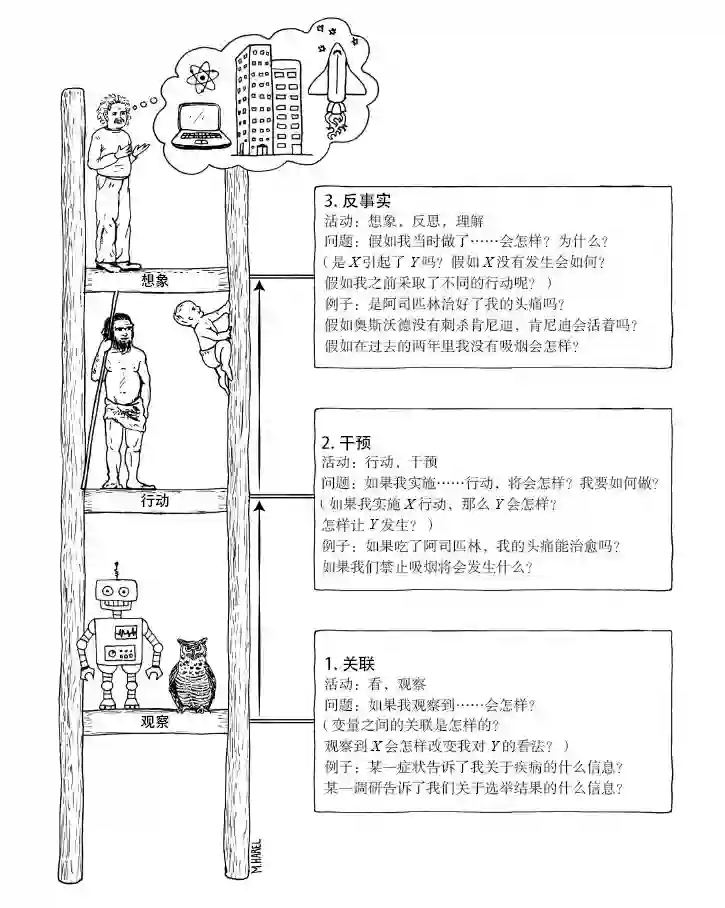
现有的统计学习系统仅仅停留在因果关系之梯的第一层,即观察,观察特征与标签之间的关联,而无法做到更高层次的事情。
当然现在也有很多人在做相关的研究,例如用反事实的思想去做训练策略(例如二分类,先假设当前样本为正例,得到一个表示,再假设当前样本为负例,又得到一个表示,两个表示相减,所剩余的东西,作者即认为是真正有用的特征),或者干脆去做对抗训练(例如文本分类中,替换实体或者遮蔽实体,试图找到人去判断这句话为某一类的真正的因素)。这些方法是想要在统计的限制之内试图去找到真正与答案有“因果”关系的因素,或者更加宏大的是,找到人类关于这个问题的通用知识。实际上当我们在统计模型中,通过去干预数据描述世界的方式,驱使模型真正模仿了人真正的推理过程,那么也就是让模型学习到了人类关于这个任务的通用知识。个人认为,如果能驱使模型学习到通用知识,其实同分布的假设也就没有那么容易被打破了。
这其实和2年前Welling教授所提到的愿景是类似的,Welling教授想要赋予模型演绎的能力,而这三位大佬的文章中则想要让AI系统学习到潜在的因果,能够从低层次的“感知”到高层次的“认知”。
但实际上,这样一种系统其实会超出现在所有对神经网络、深度学习等等的定义,会超出对统计模型的定义。统计模型其本身的原理、结构就限制了其能力,它只能做归纳,却不能做演绎。那也就是说,如果想赋予深度学习系统认知的能力,则需要彻底改变现有深度学习系统的模式,包括模型的存在形式,模型“学习”的过程,这可能是想要实现更强的人工智能的一种必然,却又无法想象它会是以一种什么样的形式存在,我想,大佬们在文章里面没有讲清楚,也可能这片未来本就是迷雾重重的。
实用主义出发的道路
我的口嗨
AI研究一直分为两个学派,符号学派及统计学派。符号学派从定理证明开始,到专家系统,到知识图谱,以及曾经非常火爆的五代机等,实际上一直在做的事情,就是试图将我们上文所讨论的将人类的认知能力描述出来,赋予给机器的过程。只不过,符号学派需要无数的人去不断地穷举、描述真实世界的知识,再编写成为机器所能接受的形式,还要去考虑计算效率等等的问题,繁琐,效率很低,面对复杂的真实世界,自然会又种种掣肘,在数据量够大、算力够便宜的今天,远不如统计学派来的优雅。
可是我们又不得不承认,在划分能力(即定义“否”的能力)上,符号派相比于统计派,就是得天独厚的。
其实在统计学习已经逐渐触摸到上限的今天,我们无法设想出新的道路,但我们是否可以走走老路呢?例如,统计学习实际上是去解决人看不过来的东西,将复杂的世界划分或聚拢成为若干个分组,每一个分组去解决不同的问题,那其实使用统计学习到的特征,成为一种规则触发,与符号AI结合,去解决更加复杂的问题,看似中庸,但使其作为一个实用者出发的道路,是否可以呢?
实际上,统计学习系统作为一个辅助决策的工具,已经在很多个领域有这种应用了,利用各个条件执行决策的,可能是人,可能是一个简简单单的规则引擎,它虽不优雅,但胜在有用。
或许,人工智能的发展,可能就是要统合,就如同玉女剑法和全真剑法一样,看似互相克制,但其实双剑合璧,却是真正的威力。

添加微信xixiaoyao-1,备注“商务合作”
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【