从数学推导开始,7万字一定带你学会支持向量机(附118PDF下载)
转载机器之心报道
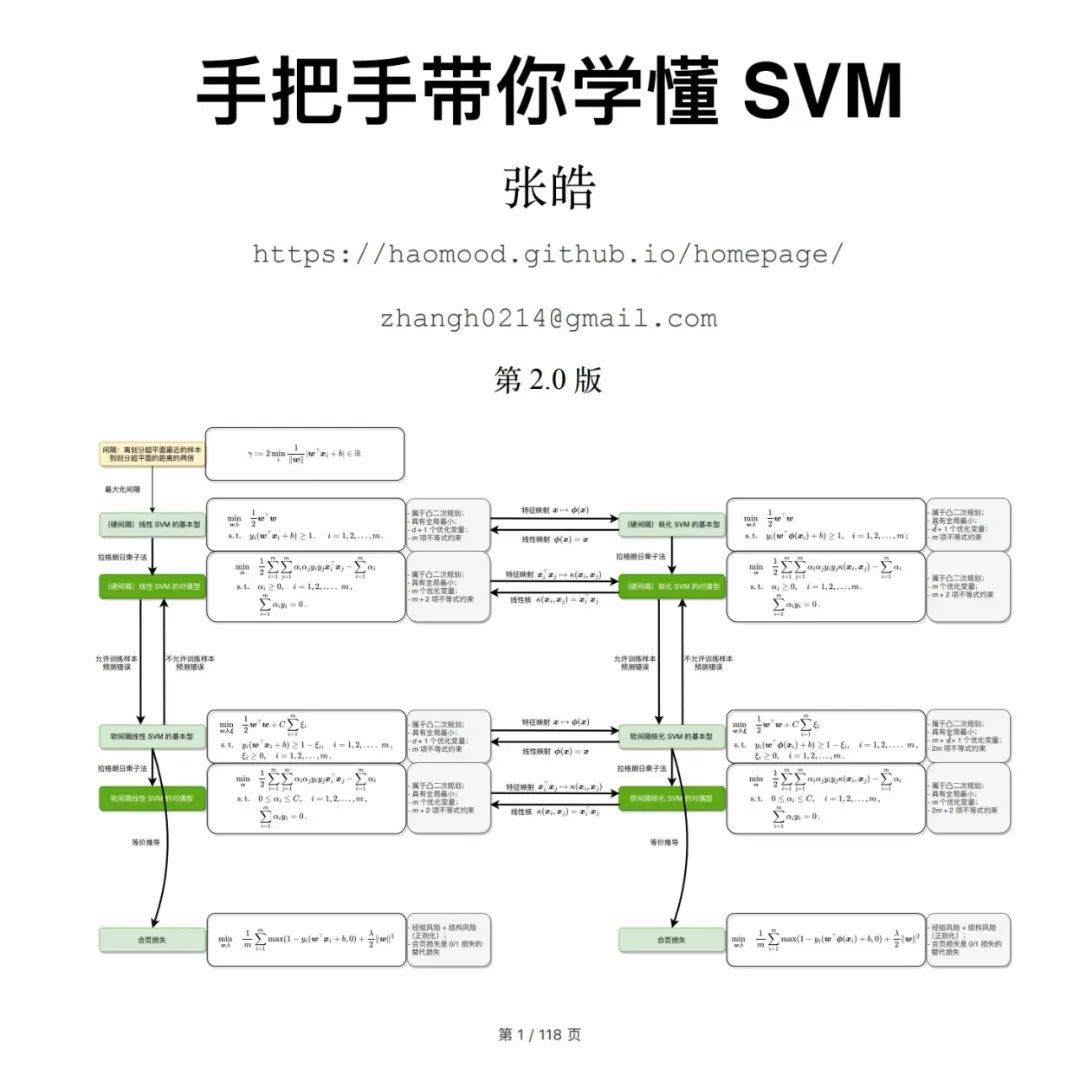
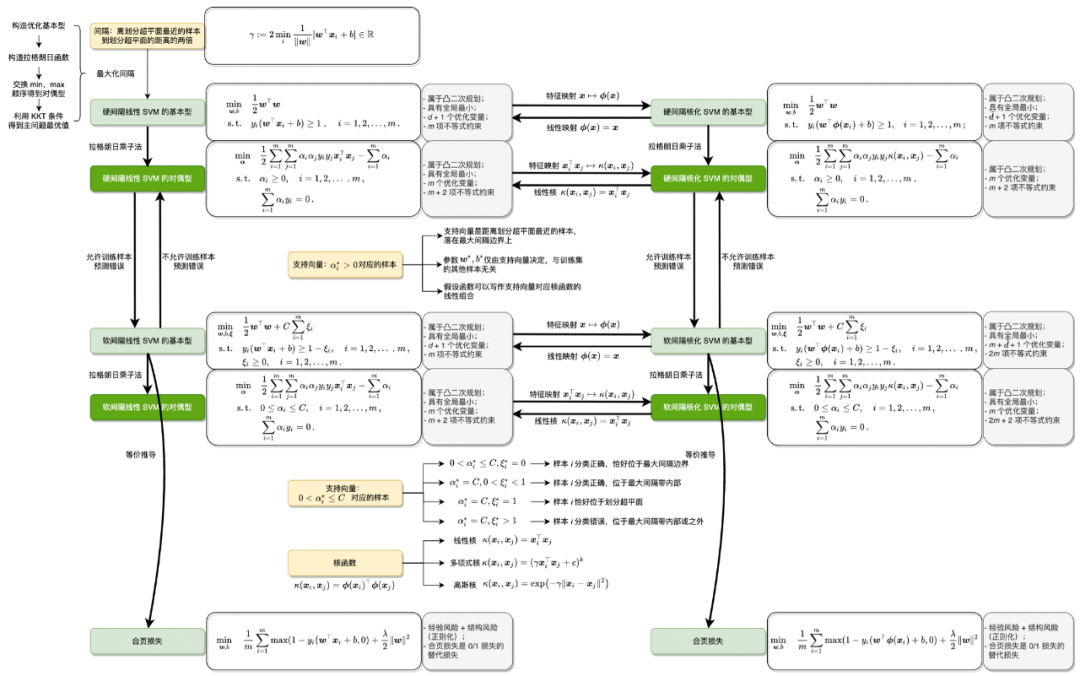
本书从零推导 SVM,涵盖从 SVM 的思想、到形式化、再简化、最后实现的完整过程。
-
电子书下载地址:https://pan.baidu.com/link/zhihu/7QhkzYuRhtikYhNkkFdf1qRHewTqJVRwZBVW== -
知乎链接:https://zhuanlan.zhihu.com/p/480302399
-
数学推导详细 。对于一些数学性比较强的资料,读者有时会卡在其中的一两个关键步骤,无法理解其中的推导过程,导致无法学习后续的内容。本书会详细推导所有涉及的公式,数学基础比较好的读者可以快速浏览推导过程作为回忆和巩固;而对于数学基础有些薄弱的读者,详细的推导过程将使读者不会 “掉队”; -
补充背景知识 。SVM 是凸优化领域的经典算法,需要读者对凸优化的背景知识有一定的了解。但是大部分读者可能并不是数学或优化背景出身,为了学习 SVM 先要掌握内容宏大的凸优化知识会是比较重的负担。为了减轻读者的负担并能使尽可能多的读者从中收益,本书不要求读者有凸优化背景知识,读者只需要有基础的微积分和线性代数背景即可。文本对 SVM 中涉及的背景知识会进行补充,力图使本书内容是自足的,即争取做到 “学懂 SVM 只看本书就够了”; -
概念图文结合 。SVM 的另一个难点是涉及许多概念,有些还比较抽象。因此,本书配备了许多插图,用于辅助读者学习。读者如果能自动地做到将各个术语和概念对应到图中,那基本就可以达到对 SVM 融会贯通的程度; -
包含面试问题 。本书内容涵盖了常见的对 SVM 的面试考察问题,因此也可以作为快速回顾和复习 SVM 的参考资料; -
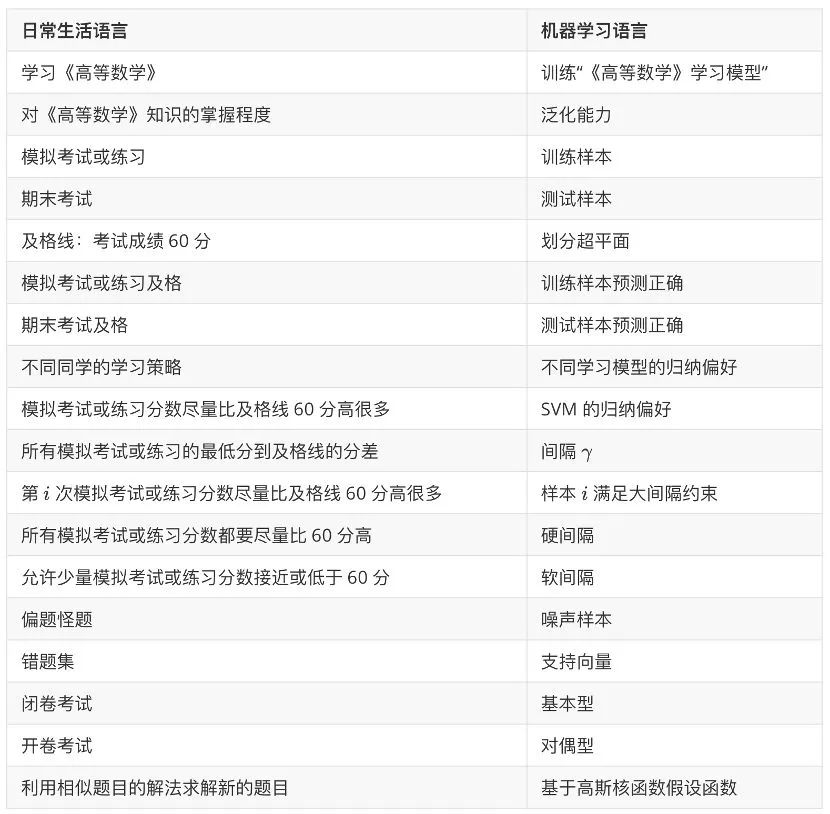
穿插趣味示例 。本书如果通篇都是对 SVM 的数学推导不免有些抽象和乏味,因此会多次用人类学习《高等数学》知识这一例子类比 SVM 中的重要概念和思想。类比不见得严谨,但对理解 SVM 具有帮助意义。



专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“S118” 就可以获取《从数学推导开始,7万字一定带你学会支持向量机(附118PDF下载)》专知下载链接



登录查看更多
相关内容

在机器学习中,支持向量机(SVM,也称为支持向量网络)是带有相关学习算法的监督学习模型,该算法分析用于分类和回归分析的数据。支持向量机(SVM)算法是一种流行的机器学习工具,可为分类和回归问题提供解决方案。给定一组训练示例,每个训练示例都标记为属于两个类别中的一个或另一个,则SVM训练算法会构建一个模型,该模型将新示例分配给一个类别或另一个类别,使其成为非概率二进制线性分类器(尽管方法存在诸如Platt缩放的问题,以便在概率分类设置中使用SVM)。SVM模型是将示例表示为空间中的点,并进行了映射,以使各个类别的示例被尽可能宽的明显间隙分开。然后,将新示例映射到相同的空间,并根据它们落入的间隙的侧面来预测属于一个类别。
Arxiv
0+阅读 · 2022年9月17日
Arxiv
0+阅读 · 2022年9月15日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年9月17日
Arxiv
0+阅读 · 2022年9月15日