2月23日,清华大学计算机系崔鹏副教授与斯坦福大学Susan Athey(美国科学院院士,因果领域国际权威)合作,在全球顶级期刊Nature Machine Intelligence(影响因子IF=15.51,2020)上发表题为“Stable Learning Establishes Some Common Ground Between Causal Inference and Machine Learning”(稳定学习:建立因果推理和机器学习的共识)的观点论文。深入探讨和总结了因果推理在机器学习和人工智能领域取得的关注,并对“稳定学习”提出了系统性分析和展望。文章认为,机器学习和因果推理之间应该形成共识,而稳定学习正在向实现这一目标的方向迈进。
机器学习与经济学的碰撞,会产生什么样的火花?
人工智能的目标是让机器像人类一样“思考”和“决策”,机器学习是实现这一愿景的重要方法。那么,用机器学习的方法来解决现实中的决策问题是否可行?斯坦福大学的Susan Athey在一次演讲中用身边的例子进行了举例:斯坦福大学的经济学系女教授的平均水平似乎比男教授更高,老是发不出文章的教授中女教授很少,但这很有可能是因为数据自身的局限性,如果通过机器学习的方法编写程序按性别来筛选候选人,并用斯坦福的训练数据去推而广之,很有可能在实际中产生歧视。利用机器学习实现对一项政策效果进行更精准的推断,这正是诺贝尔奖级别的研究成果——Susan Athey与她的丈夫Guido Imbens近年来关注的研究方向正是利用机器学习实现对政策效果更精准的推断,并在融合机器学习与政策的处置效应方面合作撰写了多篇文章。而Guido Imbens2021年也因此与另两位学者分享了当年的诺贝尔经济学奖,评奖委员会认为,他们在劳动经济学和从自然实验中分析因果推理方面做出了突出贡献,掀起了经济学研究的“可信革命”。所谓“因果推理”是计量经济学中近年来得到重视的一个重要概念。传统计量经济学一般集中在统计推理方面,重视变量之间的相关性而忽视了当中的因果关系;因果推断则是将相关性与因果性进行独立分析,科学地识别变量间的因果关系。在机器学习领域也存在类似的问题,目前大多数机器学习模型注重各因素之间的相关性分析,由此衍生的“泛化性”和“可信性”正是当前机器学习需要面对的两大问题。在大数据时代,人们认为可以利用更大的机器或者更多数据解决问题,但很多时候问题的答案并不在数据中。这也正是机器学习难以在实际场景中应用于决策的原因:机器学习存在缺乏可解释性和未知环境下的稳定性的问题,既难以预测结构变化之后的结果,也不能对结果进行合理的解释。

(人工智能的两大问题:缺乏可解释性和稳定性,来自崔鹏的报告ppt)Susan Athey在2017年为《Science》撰写的综述性文章《Beyond Prediction:Using big data for policyproblems》中总结,在做出预测和做出决策之间存在许多差距,为了优化数据驱动的决策,需要理解基本假设。而这也正是解决机器学习两大问题的有效途径。

(Susan 2017年为《Science》撰写的综述性文章)**在机器学习过程中带来的关联统计被认为是导致目前的机器学习缺乏可解释性和稳定性的重要原因。**现有的大部分机器学习方法都需要IID假设,即训练数据和测试数据应当是独立同分布的。然而在现实中这一假设很难满足。以我们熟悉的图片“猫狗检测”为例,如果训练数据的大部分图片中狗位于草地上,模型对“水中的狗”这一极端样例的检测可能会完全失效,甚至可能出现“指猫为狗”的错误,把在草地上的猫错认为狗。

(来自崔鹏的报告ppt)当下的人工智能技术往往不能很好地泛化到未知的环境,是因为现有大部分机器学习模型主要是关联驱动的,这些模型通常只做到了知其“然”(即关联性)而不知其“所以然”(即因果性)。将因果推理的思想推广到机器学习领域,去除关联中的虚假关联,使用因果关联指导模型学习,是提升模型在未知环境下稳定性根本路径之一。值得一提的是,从因果角度出发,可解释性和稳定性之间存在一定的内在关系,即通过优化模型的稳定性亦可提升其可解释性,从而解决当前人工智能技术在落地中面临的困境。基于此,清华大学崔鹏团队从2016年起开始深入研究如何将因果推理与机器学习相结合,并最终形成了“稳定学习”(Stable Learning)的研究方向。稳定学习有望弥补机器学习模型的“预测”到经济生活等现实“决策”之间的鸿沟,随着对因果分析研究的进一步深入,以稳定学习为代表的因果分析建模技术将成为人工智能发展的突破口,帮助我们从数据中推断出因果关系并进行有效检验,从而做出更好的决策。
稳定学习:建立因果推理和机器学习的共识
摘要因果推理近年来在机器学习和人工智能领域引起了广泛关注。它通常被定位为一个独特的研究领域,可以将机器学习的范围从预测建模扩展到干预和决策。而从作者的角度来看,即便对于机器学习所擅长的预测类问题,如果对预测稳定性、可解释性和公平性提出较高要求,那么因果统计的思想对于改善机器学习、预测建模也变得不可或缺。基于此,作者提出了稳定学习的概念和框架,以弥合因果推理中传统精确建模与机器学习中的黑盒方法之间的鸿沟。本文阐明了机器学习模型的风险来源,讨论了将因果关系引入机器学习的必要性,从因果推理和统计学习两个视角阐述了稳定学习的基本思想和最新进展,并讨论了稳定学习与可解释性和公平性问题的关系。
当前机器学习的主要风险
论文指出,机器学习技术的优化目标是预测的精度和效率,而错误预测的潜在风险往往被忽视。对于预测点击量或对图像进行分类等应用,模型可以频繁更新,错误的代价也不会太高。因此,这些应用领域非常适合结合持续性能监控的黑盒技术,这也是近年来机器学习得以快速发展的基础。然而,近年来机器学习被应用于医疗健康、工业制造、金融和司法等高风险领域,在这些领域,机器学习算法犯下的错误可能会带来巨大的风险。尤其是当算法预测在决策过程中发挥重要作用时,错误会对安全、道德和正义等社会问题产生重大后果。因此,缺乏稳定性、可解释性和公平保障是当今机器学习中亟需解决的最关键和最紧迫的议题。
虚假相关性:风险的主要来源
如图所示,相关性有三种来源,即由因果性导致的相关性、干扰变量导致的相关性、由样本选择偏差导致的相关性。在这三种相关性中,只有由因果性导致的相关性是可以保证在各种环境下稳定成立、且可以被解释的。而目前的神经网络模型并没有对特征是否存在因果性加以区分,这也是导致模型性能不稳定的重要原因。 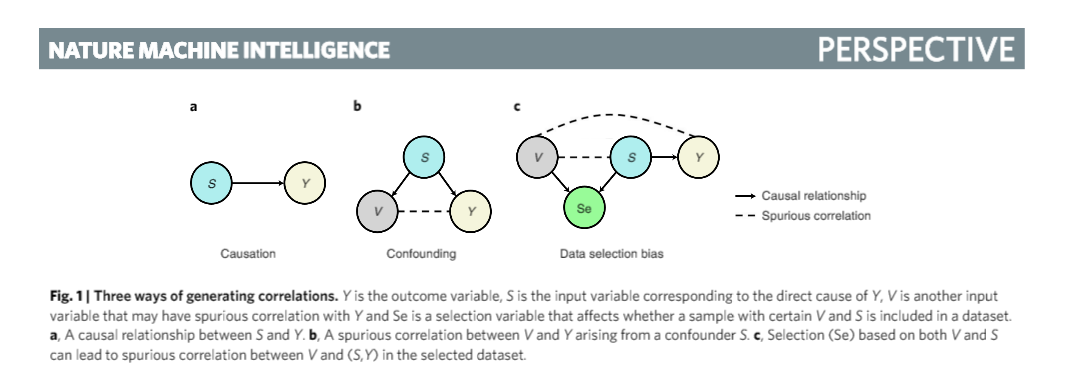
稳定学习:建立因果推理和机器学习的共识
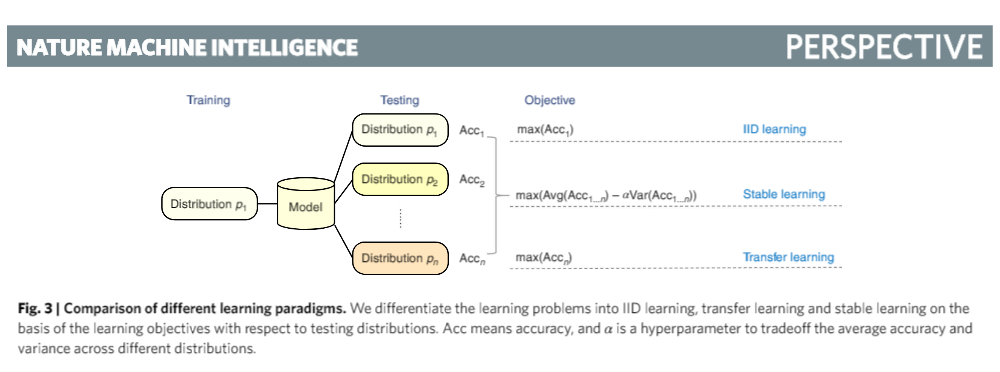
论文还进一步阐述了稳定学习的定位与发展脉络,并比较了与常见的独立同分布模型和迁移学习模型的异同:
-
独立同分布模型的训练和测试都在相同分布的数据下完成,测试目标是提升模型在测试集上的准确度,对测试集环境有较高的要求;
-
迁移学习同样期望提升模型在测试集上的准确度,虽然允许测试集的样本分布与训练集不同,但要求测试集样本分布已知;
-
稳定学习无需测试数据集与训练数据来自同一分布,并且不假设测试数据分布已知。测试目标是在保证模型平均准确度的前提下,降低模型性能在各种不同样本分布下的准确率方差。与上述学习模式相比,稳定学习的目标更接近现实的问题设置,理论上,稳定学习可以在不同分布的测试集下都有较好的性能表现。
结论文章最后提出,如果我们希望机器学习算法能被进一步应用,需要解决稳定性、可解释性和公平性问题,而这些问题是当今学习范式的根本局限,需要从根本上加以解决。尽管业内对预测、相关性和因果关系的基础仍存在争论,因果推理,尤其是在观察研究中所取得的一些最新进展已经可以为机器学习提供更多的见解和理论支持。作为一种新的学习范式,稳定学习试图结合这两个方向之间的共识基础。如何合理地放松严格的假设,以匹配更多具有挑战性的真实应用场景,并在不牺牲预测能力的情况下使机器学习更可信,是未来稳定学习需要解决的关键问题。论文完整内容参见Nature网站:https://www.nature.com/articles/s42256-022-00445-z
作者简介

崔鹏清华大学长聘副教授。于2010年获得清华大学博士学位,研究兴趣包括大数据环境下的因果推理与稳定预测、网络表征学习,及其在智慧医疗、商业决策等场景中的应用。从2016年起,崔鹏与团队开始深入研究如何将因果推理与机器学习相结合,并最终形成了“稳定学习”(Stable Learning)的研究方向。他在数据挖掘和多媒体领域的著名会议和期刊上发表了150多篇论文,并先后获得7项国际会议及期刊最佳论文奖。曾获得CCF-IEEE CS青年科学家奖,国家自然科学二等奖,以及省部级一等奖3项。目前是ACM杰出会员,CCF杰出会员以及IEEE高级会员。

Susan Athey斯坦福大学商学院教授,美国科学院院士,美国艺术与科学院院士,美国经济学会主席,约翰·贝茨·克拉克奖(该奖项也被视为诺内尔经济学奖的风向标)的第一位女性获得者。她曾在微软担任咨询首席经济学家六年,目前是斯坦福大学斯坦福经济政策研究所高级研究员、以人为本人工智能研究所副主任、 Golub Capital 社会影响实验室主任。Susan Athey本科期间在杜克大学同时主修经济学、数学与计算机科学三个专业,目前专注于数字化经济学、市场设计以及计量经济学与机器学习领域的交叉领域研究,是因果领域的国际权威。