推荐系统是应用极其广泛的技术,基于因果方法的推荐系统正在成为趋势,并取得良好效果。北京大学周晓华团队针对各类因果启发式推荐方法,提出了一套统一的因果分析框架,并应用于多种推荐场景,本文是对相关新工作的介绍。
研究领域:因果推断,因果科学
随着互联网技术的普及,用户在信息时代对信息的需求得到满足。但随着网络迅速发展带来的信息量的大幅增长,使得用户在面对海量信息时无法从中获取对自己真正有用的那部分信息,例如:亚马逊有1200万件商品,Facebook有28亿用户,Youtube每天有72万小时的视频上传等。如此一来反而降低了用户对信息的使用效率,这就是大数据时代的“信息过载”现象。推荐系统作为基于机器学习算法的信息过滤系统,可以预测客户对产品的评级或偏好,帮助用户进行购买决策,被认为是解决信息过载的有力工具,以满足个体兴趣和偏好的需求。
近年来,因果推理引起了学术界和工业界的广泛关注。北京大学周晓华教授团队在因果推荐系统领域顶尖会议发表了多篇论文,提出了一套因果分析框架来统一现有的各类因果启发的推荐方法,并基于此在多个经典推荐场景,例如:选择偏差、点击后转化率预测、隐反馈、多稳健学习、用户从众偏差等多个场景使用因果推断技术,在理论和数值试验方面均展现出了卓越的性能。更多关于因果推荐系统的内容可参考:最新综述 | 基于因果推断的推荐系统。
1. 《On the Opportunity of Causal Learning in Recommendation Systems: Foundation, Estimation, Prediction and Challenges》(北京大学,华为)
https://arxiv.org/abs/2201.06716
近年来,因果推理引起了学术界和工业界的广泛关注。因果推理的新理论、新方法和新应用正以惊人的速度涌现。推荐系统是因果推理发展和应用的一个新兴领域。推荐系统中的许多实际问题本质上都是因果问题,如浏览后的点击率预测、点击后转化率预测和Uplift模型等。与传统的推荐方法相比,因果推荐方法有几个优势,包括更好的可解释性和稳定性,更高的准确性和可概括性。
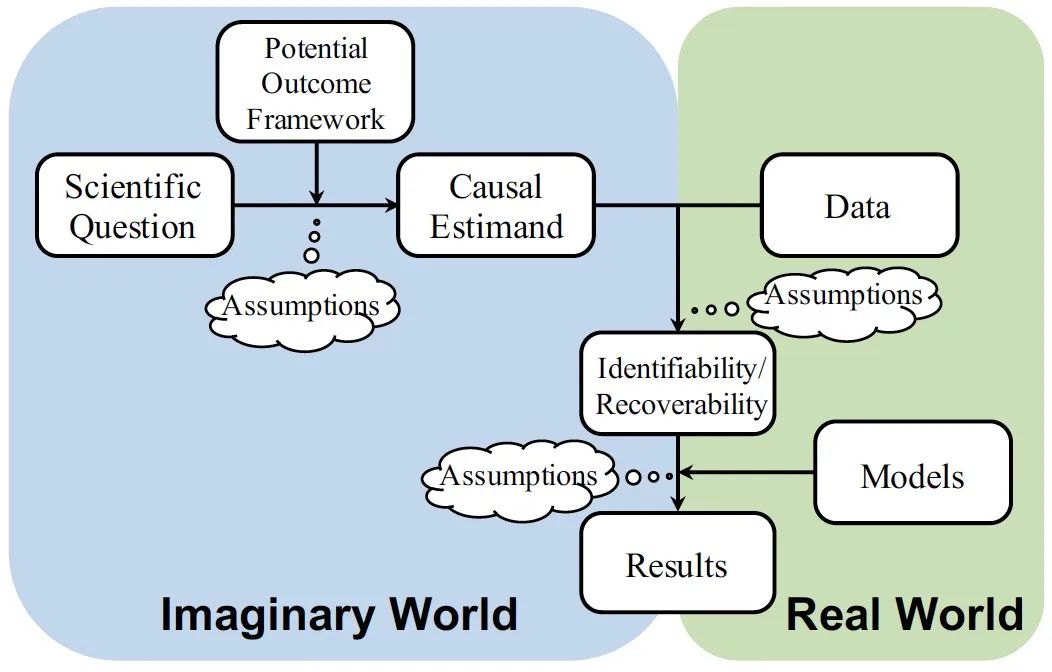
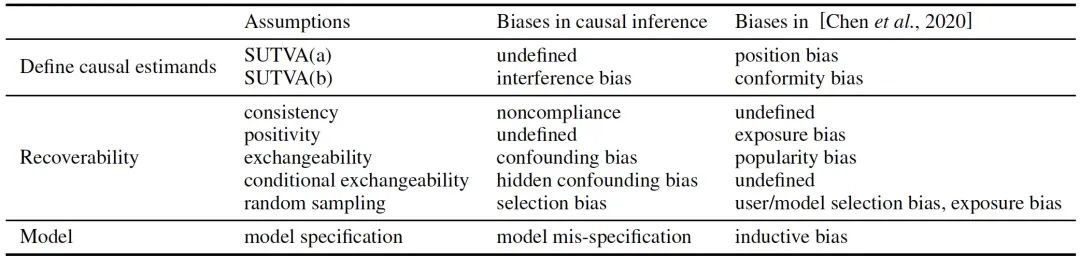
然而,一个统一的因果分析框架还没有建立起来。一方面,现有的推荐系统的因果分析方法对感兴趣的科学问题缺乏明确的因果和数学表述,导致该领域普遍存在许多模糊的因果概念,阻碍了因果推荐方法的发展。需要澄清许多混乱的问题:到底是什么被估计,为了什么目的,在什么情况下,通过什么技术,在什么合理的假设下。另一方面,推荐系统的观察数据的一个明显特征是存在各种偏差,这是得出因果结论的主要障碍。然而,推荐系统中偏差的正式因果定义仍然不明确,尽管各种偏差已经被发现并以描述性的方式提出。由于缺乏对因果问题和偏差类型的正式阐述,很难清楚地讨论去偏方法的理论属性、优点和缺点。也很难清楚地解释这些方法背后的假设。因此,很难开发新的去偏算法。
在北京大学与华为的研究成果《On the Opportunity of Causal Learning in Recommendation Systems: Foundation, Estimation, Prediction and Challenges》中,我们旨在通过在因果推断中的潜在结果框架来克服上述限制,通过该框架我们综述并统一了现有的因果启发的推荐方法。我们通过分析现有研究中可能使用但未讨论的因果假设,为推荐系统中的偏差提供因果视角,然后讨论违反上述假设的相应推荐场景。事实上,大量的推荐任务通过应用提出的因果框架得到了严格的澄清。最后,我们对推荐系统中的许多去偏和预测任务进行了形式化,并总结了基于统计和机器学习的因果估计方法,期望为因果推荐系统社区提供新的研究机会和视角。
2.《A Generalized Doubly Robust Learning Framework for Debiasing Post-Click Conversion Rate Prediction》(北京大学,华为)
https://dl.acm.org/doi/abs/10.1145/3534678.3539270
点击后转化率
(CVR)
的预测在现代推荐系统中得到了广泛的关注,因为点击后转化的反馈包含了用户偏好的强烈信号,并直接促进了商品总量
(GMV)
。在许多工业应用中,CVR预测通常被认为是发现用户兴趣和增加平台收入的核心任务。对于一个用户-物品对,CVR代表了用户在点击该物品后消费该物品的概率。从本质上讲,CVR预测的任务是一个反事实的问题。这是因为在推理过程中,我们想知道的本质上是所有用户-项目对的转换率,假设所有项目都被所有用户点击,这是一个与现实相矛盾的假设情况。
大多数现有的工作将CVR预测视为一个缺失数据问题,其中转化标签在点击的事件中被观察到,而在未点击的事件中缺失。一个传统和自然的策略是只根据点击的事件训练CVR模型,然后预测所有事件的CVR。然而,由于存在严重的选择偏差,这种估计方法是有偏差的,并且经常得到一个次优的结果。此外,数据稀少的问题,即点击事件的样本量远远小于非点击事件的样本量,将放大这两类事件之间的差异,从而加剧选择偏差问题。
对于考虑选择偏差的CVR的无偏估计器:基于误差推断
(EIB)
和逆概率加权
(IPS)
是CVR预测去偏的两个主要策略。此外,可以通过结合EIB和IPS方法构建双稳健
(DR)
估计器。一个DR估计器将具有双稳健的特性,如果推断误差或倾向性得分都是准确的,它可以保证对CVR的无偏估计。与EIB和IPS方法相比,DR方法在总体上有更好的表现。
尽管DR方法通常与EIB和IPS估计器相比更有优势,但仍有一些担忧。通过对DR估计器的理论分析表明:偏差、方差和泛化界都取决于由倾向得分的倒数加权的误差推断模型的误差偏离。这是一个令人担忧的结果,因为在未点击的事件中,倾向于使用大的倾向性加权,而由于选择偏差和数据稀少,误差推断模型的误差偏差在未点击的事件中很可能是不准确的。这表明,在未点击事件中,在不准确的推断误差下,偏差、方差和泛化边界可能仍然很大。最近,一些方法,主要包括双重稳健联合学习
(DR-JL)
和更加稳健的双重稳健
(MRDR)
,已经被设计用来缓解这个问题。MRDR旨在减少DR损失的方差,以提高模型的鲁棒性,但当偏差较大时,它仍然可能有较差的泛化性。DR-JL试图减少误差推断模型的偏差,以获得更准确的CVR估计值,但这种方法不能直接控制偏差和方差。因此,如果我们能找到一种更有效的方法来直接控制偏差和方差,将会很有帮助。
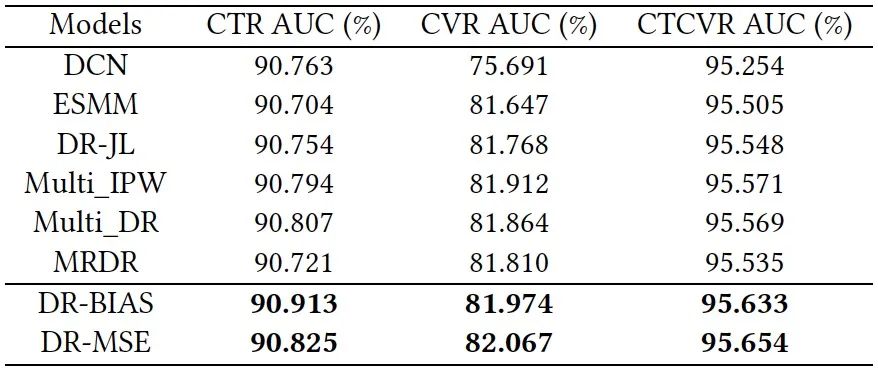
在北京大学与华为的研究成果《A Generalized Doubly Robust Learning Framework for Debiasing Post-Click Conversion Rate Prediction》中,我们揭示了CVR预测任务背后的反事实问题,并给出了CVR的正式和严格的因果定义。然后,通过分析DR估计器的偏差、方差和泛化界,我们推导出一个新颖的泛化学习框架,该框架可以通过指定不同的损失函数指标来适应广泛的CVR估计器。这个框架统一了现有的各种双稳健的CVR预测方法,如DR-JL和MRDR。最重要的是,它为设计新的估计器以适应CVR预测中不同的应用场景提供了关键的见解。基于这一框架,从偏差-方差权衡的角度,我们提出了两个新的双稳健估计器,称为DR-BIAS和DR-MSE,其目的是更灵活地控制DR损失函数的偏差和均方误差
(MSE)
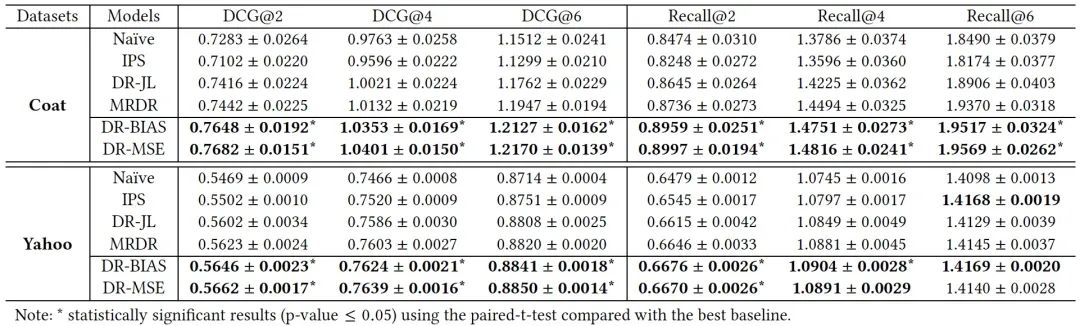
,基于我们的分析,与现有基于DR的方法相比,DR-MSE实现了更好的泛化性能。此外,我们还提出了一种新的三级联合学习优化方法,用于在CVR预测中实现灵活的DR-MSE,并提出了相应的高效训练算法。我们进行了大量的实验来验证所提出的方法与最先进的技术相比的优势。在实验中,DR-MSE在DCG@2中优于存在研究方法的3.22%。
3.《Doubly Robust Collaborative Targeted Learning for Debiased Recommendations》(北京大学)
https://arxiv.org/abs/2203.10258
基于因果推断的方法来解决推荐系统中的各种任务已经变得越来越流行。这一趋势的主要原因之一是,推荐系统中的许多实际任务本身就是因果关系问题,如评分预测、浏览后的点击率预测、点击后的转换率预测,以及Uplift建模。许多先前的研究表明,基于因果关系的推荐在数值实验和理论分析中都显示了其巨大的潜力。一般来说,推荐系统面临的基本问题是:"如果向用户推荐一个项目,会有什么反馈",需要估计推荐对用户反馈的因果效应。为了回答这个问题,人们提出了许多方法,如逆概率加权
(IPS)
、自归一化逆概率加权
(SNIPS)
、基于误差推断
(EIB)
的方法和双稳健
(DR)
方法。在这些方法中,DR方法及其变体显示出优越的性能。
为了评估这些方法的性能,我们引入了五个角度来比较和评估推荐系统中的不同方法,包括双重稳健性、对小倾向的稳健性、有界性、无外推性和低方差。如果不能满足其中任何一个,都可能导致次优的性能。我们在这五个方面对各种估计器进行了比较,发现IPS、EIB和DR方法只享有其中几个理想统计特性。
通常,DR在偏差和方差方面都优于IPS。在比较EIB和DR时,涉及到偏差-方差的权衡,因为通常DR的偏差比较小,而EIB的方差比较小。在《Doubly Robust Collaborative Targeted Learning for Debiased Recommendations》一文中,北京大学周晓华教授团队提出了一种新的方法,即DR-TMLE,它可以利用目标最大似然估计
(TMLE)
技术,有效地抓住DR和EIB的优点。值得注意的是,与上述现有的方法相比,DR-TMLE拥有更多的理想特性。此外,为了进一步减少训练过程中的偏差和方差,我们提出了一种新颖的不依赖随机流量数据的协作式目标学习方法,称为DR-TMLE-TL,它将推断误差分解为参数化的推断模型部分和非参数化TMLE误差部分,其中后者自适应地纠正前者的残差。通过协作更新这两部分,DR-TMLE-TL实现了更准确和稳健的预测。理论分析和实验都证明了与现有方法相比,DR-TMLE和DR-TMLE-TL的优越性。
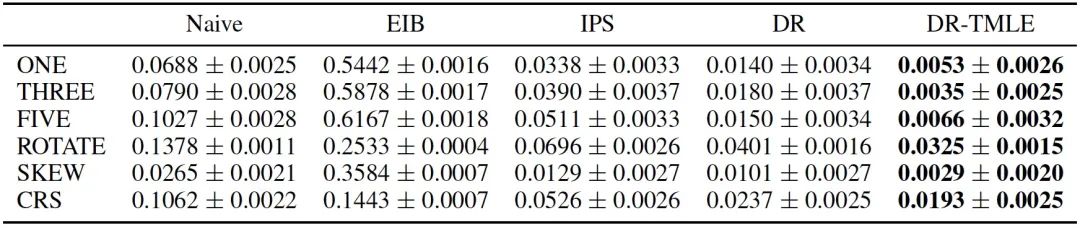
【Naive、EIB、IPS、DR和DR-TMLE的相对误差的平均值和标准偏差】
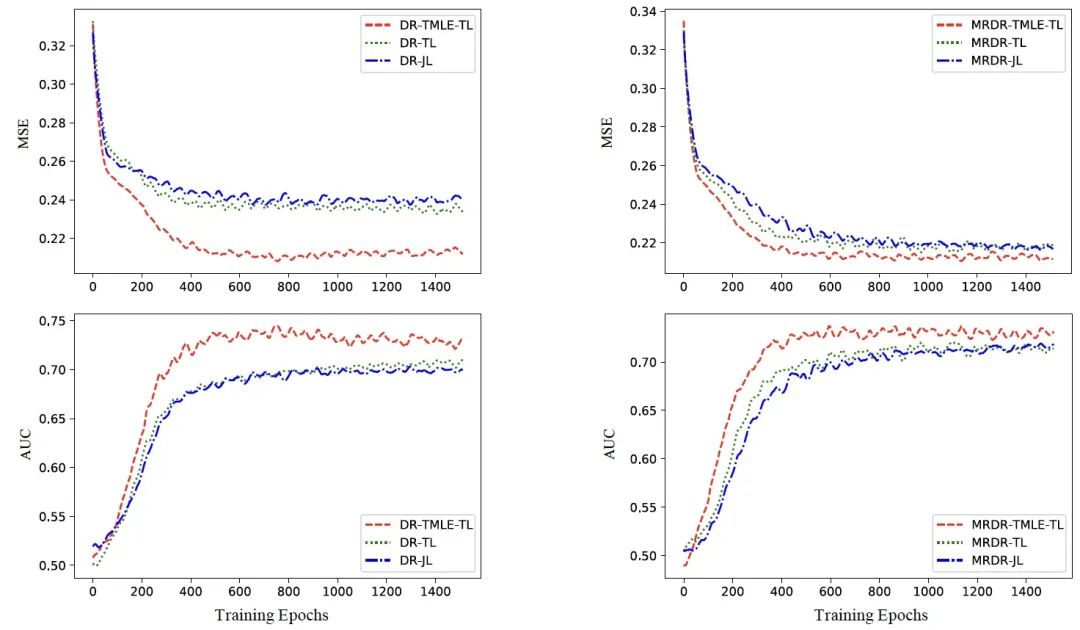
图题:TMLE-TL、TL和JL的MSE(上)和AUC(下)的比较,DR(左)和MRDR(右)作为误差推断模型,其中TL跳过了TMLE-TL中的目标步骤
4.《RDLDR: Robust Debiasing Loop Doubly Robust Learning for Post-Click Conversion Rate Prediction》(北京大学)
转化标签作为一类反馈,反映了用户偏好的强烈信号,并与商品交易总量
(GMV)
直接挂钩。点击后转化率
(pCVR)
指的是点击事件发生后的转化概率。在许多应用场景中,如电子商务交易、音乐网站和学术文章下载,预测pCVR的任务在探索用户兴趣和增加平台收入方面起着关键作用。
pCVR预测任务可以被看作是一个缺失数据的问题,因为我们想预测所有事件的pCVR,但转换反馈只在点击的事件中可以观察到,而在未点击的事件中缺失。在推荐系统中,用户可以自由选择要点击的项目,因此缺失不是随机的,导致点击的事件和所有事件之间的分布有明显的不同,这就是选择偏差问题。一个朴素的方法是直接使用点击的事件来训练pCVR模型。然而,由于选择偏差的存在,这种方法通常具有次有的性能。考虑选择偏差,旭福哦研究提出了无偏学习的方法,包括基于误差推断
(EIB)
的方法、逆概率加权
(IPS)
和双稳健
(DR)
方法。其中,双稳健放法及其提升版本在pCVR预测方面具有最先进的性能。
EIB方法试图对未点击事件的预测误差进行推断,然后通过对所有事件的预测误差进行平均,得出一个无偏的损失函数。然而,EIB估计器在很大程度上依赖于误差推断模型的“外推性
(外泛化能力)
”,导致难以获得准确的误差推断,在实践中造成性能不佳。IPS方法对点击的概率进行建模,称为倾向得分,通过用倾向得分的倒数对点击事件的预测误差进行加权,得到一个无偏的损失函数。虽然倾向性估计不依赖于外推法,但IPS方法遇到了小倾向性情况下的高方差问题,由于严重的数据稀少问题,即点击事件的样本量远远小于未点击事件的样本量,这在pCVR预测任务中经常出现。通过结合EIB和IPS方法,DR估计器具有双重稳健性,也就是说,如果推断的误差或估计的倾向得分是准确的,DR就是无偏的。
尽管具有双重稳健性,现有的DR方法也继承了IPS和EIB的缺陷。DR估计器依赖于外推法,我们的理论分析表明,当存在一些极小的倾向性时,DR估计器的偏差、方差和泛化误差界会变得非常大
(趋于无穷大)
。自归一化的IPS
(SNIPS)
估计器通过归一化其权重来改进IPS估计器。与DR估计器相比,我们发现SNIPS估计器不依赖于外推法,在存在小的倾向性的情况下,它的偏差、方差和泛化误差都有界,尽管它不是双重稳健的。
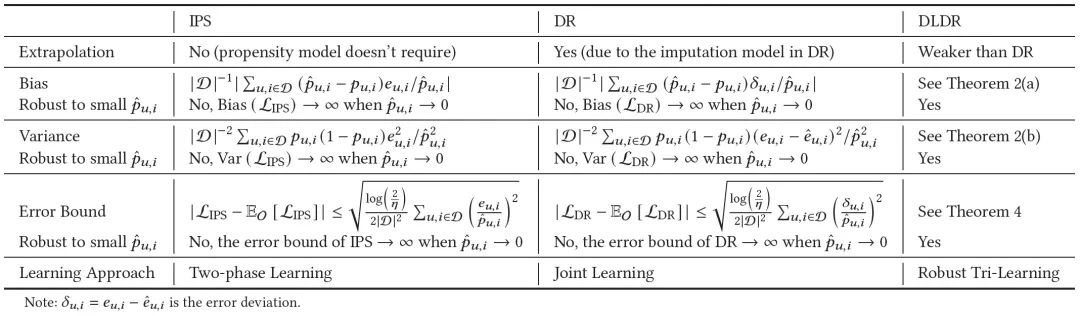
【比较IPS、DR和提出的DLDR估计器的外推依赖性、偏差、方差、误差界和学习方法】
在《RDLDR: Robust Debiasing Loop Doubly Robust Learning for Post-Click Conversion Rate Prediction》一文中,北京大学周晓华教授团队提出了一种新的循环去偏双稳健
(DLDR)
估计器,它有效地结合了SNIPS和DR估计器的优点。一方面,当学到的倾向性是准确的,DLDR估计器等同于原始的SNIPS估计器。另一方面,如果倾向性是不准确的,但推断的误差是准确的,DLDR估计器将收敛于EIB估计器。此外,我们从理论上表明,提出的DLDR估计器在存在小的倾向性的情况下具有有界的偏差、方差和泛化误差边界。DLDR估计器是一个增强的SNIPS估计器,它获得了双重稳健性的特性,并且是一个改进的DR估计器,它改善了对小倾向的稳健性,减轻了对外推法的依赖性。此外,我们提出了一种稳健的DLDR
(RDLDR)
三模型学习方法,以减少DLDR估计器的方差,并通过共享pCVR的参数及其误差推断模型进一步提高稳健性。
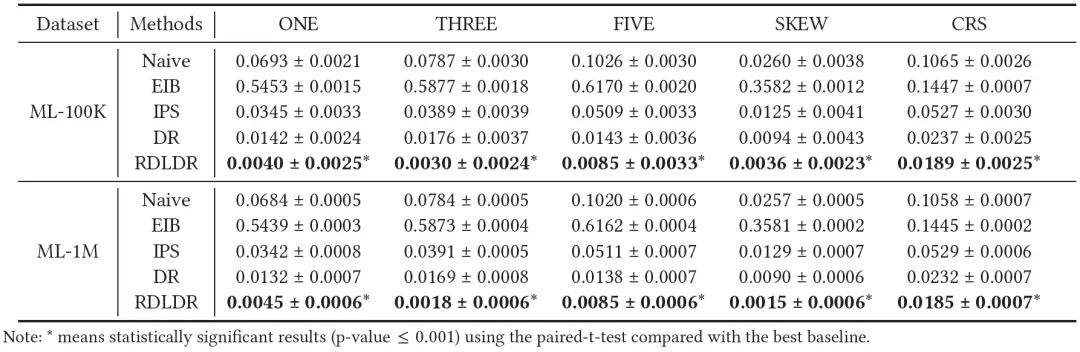
【在两个半合成数据集ML-100K和ML-1M上,五个预测指标的相对误差与理想损失相比较(最好的结果用黑体表示)】
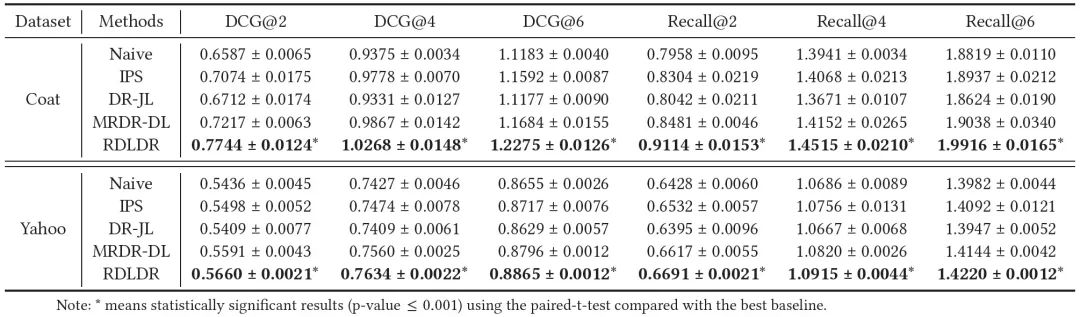
【在Coat和Yahoo!R3的MAR数据上,以MF为基模型,DCG@2,4,6和Recall@2,4,6的评价指标(最好的结果用黑体表示)】
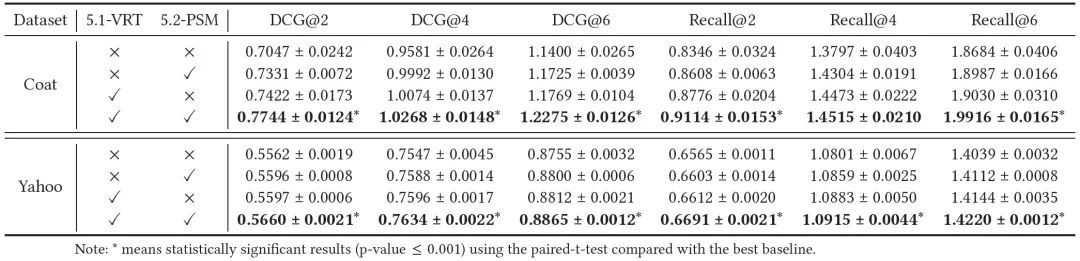
【以DCG@2,4,6和Recall@2,4,6为评价指标,在Coat和Yahoo!R3的MAR数据上对所提出的RDLDR的方法进行了消融研究(最好的结果用黑体表示)】
5.《Multiple Robust Learning for Recommendation》(北京大学,华为诺亚方舟实验室)
https://arxiv.org/abs/2207.10796
近年来,推荐系统在许多任务上取得了显著的进展,如带有显性反馈的评分预测、带有隐性反馈的用户与物品互动预测、浏览后的点击率预测、点击后的转化率预测以及Uplift建模等。其中,一个重要的挑战是,由于选择偏差和混杂偏差的存在,所收集的数据总是不能代表所关注的整体样本。为了解决这个问题,最近与debias相关的研究设计了因果关系启发的方法来实现无偏的推荐系统学习。
尽管双稳健估计的优势归功于实现无偏学习的两种机会,即准确估计误差推断模型或倾向模型的机会。然而,这些模型的正确指定要求很高。即使所学的两个模型都有轻微的指定错误,那么正如现有的工作所指出的,双稳健学习的偏差会很严重。更糟糕的是,即使有正确的模型指定,要根据观察到的数据准确地学习它们也是有难度的。首先,准确的预测误差的估计很难获得,因为误差推断模型是在暴露的事件中学习的,而被用于未暴露的事件。如果暴露的事件和未暴露的事件的分布有很大的不同,这很容易造成很大的偏差。其次,收集到的数据总是包含许多偏差
(例如,由未观察到的混杂因素引起的偏差)
,这可能导致对倾向性的不准确估计。因此,需要对无偏的学习进行更多的研究工作。
在《Multiple Robust Learning for Recommendation》一文中,北京大学周晓华教授团队和华为诺亚方舟实验室提出了一个用于推荐系统中无偏学习的多重稳健(MR)估计器,它包含多个候选倾向模型和误差推断模型。它允许多种不同规格的倾向和误差推断模型的学习。通过理论分析,我们证明了所提出的MR估计器具有多重稳健性,如果任何一个倾向模型、误差推断模型,甚至这些模型的线性组合都能准确估计出真实的倾向或预测误差,那么它就是无偏的。因此,MR估计器通过提供更多的模型规范和学习机会,可以大大解决现有工作中单一模型所学的倾向性或推断误差不准确的问题。此外,我们特别分析了当MR只有一个倾向性模型和一个归因模型时,MR和DR之间的关系,发现我们的MR估计器实际上可以提供一个加强版的双重稳健性。
通过理论分析MR估计器的泛化误差界,我们进一步提出了一种具有稳定性的多重鲁棒性学习方法,通过添加正则化更好地控制泛化误差。在真实世界和半合成数据集上进行的大量实验表明,与最先进的方法相比,所提出的方法取得了明显的改进。
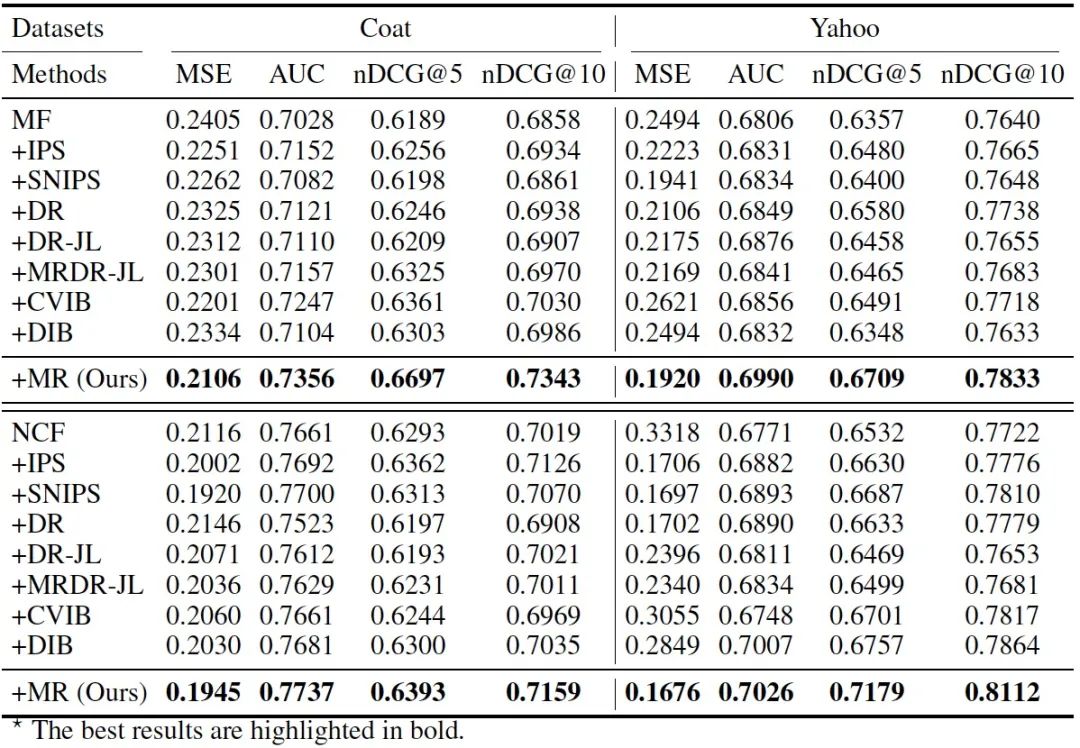
【以MF和NCF为骨干模型对Coat和Yahoo进行的实验结果】
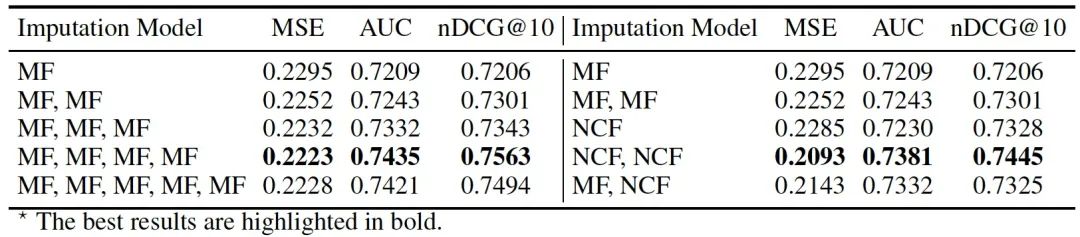
【在不同的误差推断模型设置下,即不同的数量和类型,MR方法对Coat的性能】
【在Coat数据集上不同数量和类型的倾向性模型下,MR方法的性能,其中误差推断模型和骨干预测模型都采用MF】
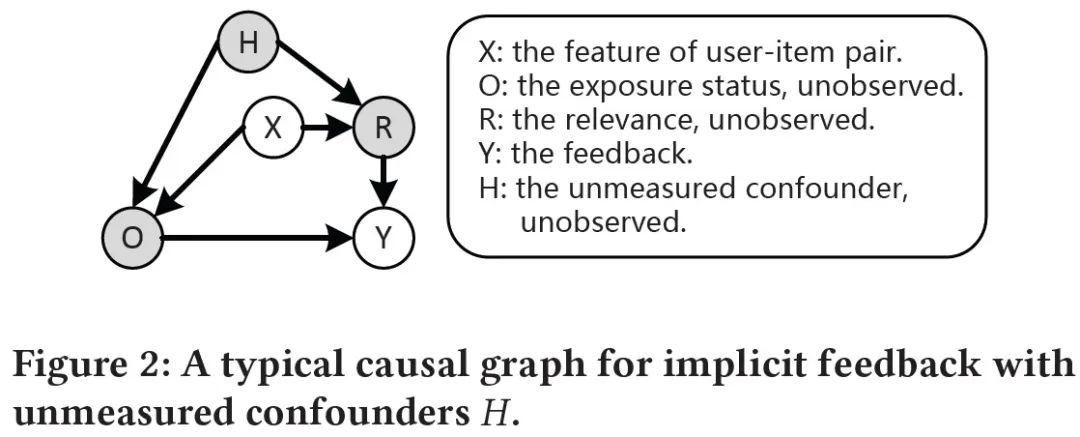
6.《A Generic Unbiased Learning Framework from Explicit to Implicit Feedback with Unmeasured Confounders》(北京大学)
推荐系统在许多现代网站和移动应用中发挥着关键作用,它过滤出用户可能感兴趣的信息。一般来说,有两种类型的用户反馈,即显性反馈和隐性反馈,用于训练推荐模型。显性反馈
(如评分)
毫不含糊地反映了用户的偏好。然而,收集显性反馈需要额外的工作,因此往往是不可获取的。相比之下,隐性反馈
(如点击或购买)
只揭示了用户的部分偏好,但只需记录用户的行为日志就可以轻松获得。
由于缺乏明确的负面反馈和缺失非随机
(MNAR)
的问题,利用隐性反馈建立推荐模型是具有挑战性的。例如,在信息检索领域,假设点击表示正反馈,那么人们就无法知道未点击的事件是负反馈
(不相关)
还是未暴露的反馈,也就是说,真正的负反馈和潜在的正反馈在未点击的事件中纠缠在一起。这个问题也被称为正向无标记的问题。此外,由于用户倾向于点击更相关的项目,而系统更倾向于推荐热门项目,所以用户的反馈并不是完全随机缺失的。忽视这个问题会招致偏见,导致次优性能。
大量的文献专注于解决正向无标签问题,例如将未点击的事件作为负向样本,并给它们分配较少的权重,或者试图从未点击的事件中抽取一些有代表性的项目。近年来,人们对同时解决正面无标签问题和MNAR问题的兴趣越来越大。Saito等人制定了一个新的理想损失函数,然后提出了一个用于无偏学习的逆概率加权
(IPW)
方法。Zhu等人和Lee等人分别通过引入联合学习方法和处理缺失反馈的偏差来扩展Saito的方法。此外,Lee等人进一步指出了暴露偏差的存在,并提出了一种去偏方法来处理它。
尽管现有的隐性反馈的去偏移方法比忽略MNAR问题的方法提高了预测精度,在《A Generic Unbiased Learning Framework from Explicit to Implicit Feedback with Unmeasured Confounders》一文中,北京大学周晓华教授团队发现有两个重要的限制:(1)没有双稳健
(DR)
方法。众所周知,双稳健方法及其变体在显性反馈的无偏学习中取得了最先进的性能,而且许多新的算法和模型结构被设计用来提高DR方法的性能。因此,开发隐性反馈的DR方法是必要的;(2)没有一个方法可以解决未测量的混杂因素。由于各种原因,如技术困难或隐私限制,未测量的混杂因素是推荐系统中不可避免的问题。我们的理论分析表明,当未测量的混杂因素存在时,基于倾向得分的去偏方法是有偏差的,因此在推荐系统中开发一种对抗未测量的混杂因素的方法至关重要。
为了填补这些研究空白,我们首先创新性地将隐性反馈问题表述为潜在结果框架内的反事实预测问题。值得注意的是,在这种新的问题表述下,以前所有针对显性反馈的去偏方法都可以平行地应用于隐性反馈,前提是暴露状态
(或等同于治疗)
可以被适当地推断。这促使我们提出了一个两阶段的去偏框架,其中包括治疗的推断阶段和去偏阶段。治疗的归纳是一个单类的分类问题,我们利用在这一领域被广泛使用的SVDD方法。对于去偏阶段,除了直接应用以前用于显性反馈的去偏方法外,我们还考虑了未观测混杂的存在,这在隐性反馈中还没有研究过。重要的是,所提出的框架提供了一个灵活的范式,将显性反馈中的去偏方法与隐性反馈中的去偏方法无缝连接。例如,我们可以将显性反馈中的DR去偏方法应用于隐性反馈。
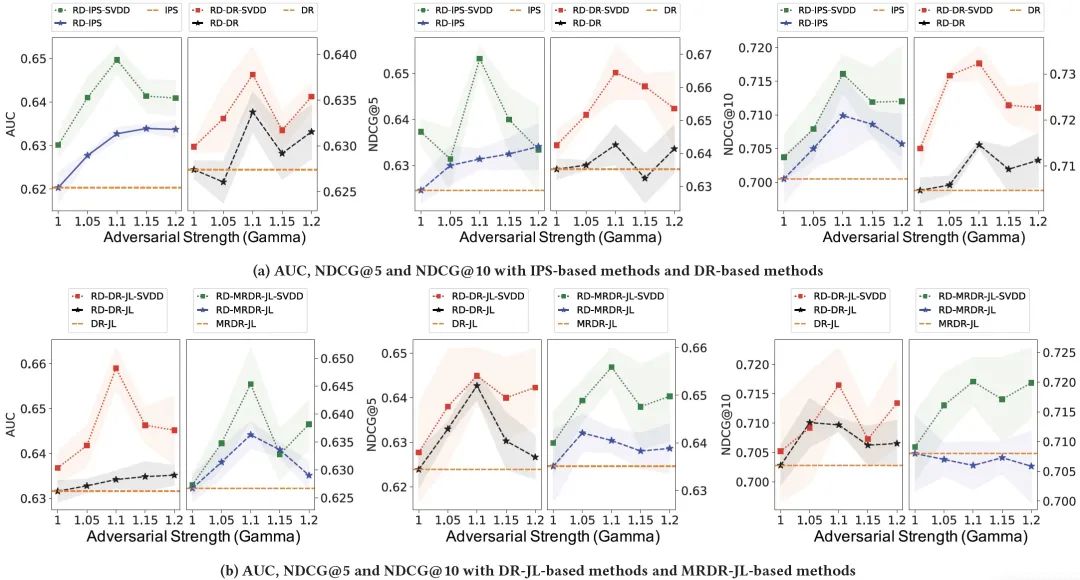
图题:在MAR数据上,不同对抗强度的AUC、NDCG@5和NDCG@10。上面是IPS和DR方法,下面是基于DR和MRDR的联合学习方法。
[1] Peng Wu, Haoxuan Li, Yuhao Deng, Wenjie Hu, Quanyu Dai, Zhenhua Dong, Jie Sun, Rui Zhang, Xiao-Hua Zhou (2021), On the Opportunity of Causal Learning in Recommendation Systems: Foundation, Estimation, Prediction and Challenges, IJCAI 22.
[2] Quanyu Dai, Haoxuan Li, Peng Wu, Zhenhua Dong, Xiao-Hua Zhou, Rui Zhang, Xiuqiang He, Rui Zhang, and Jie Sun (2022), A Generalized Doubly Robust Learning Framework for Debiasing Post-Click Conversion Rate Prediction, KDD 22.
[3] Peng Wu, Haoxuan Li, Yan Lyu, Chunyuan Zheng & Xiao-Hua Zhou (2022), Doubly Robust Collaborative Targeted Learning for Recommendation on Data Missing Not at Random, arXiv:2203.10258.
[4] Haoxuan Li, Chunyuan Zheng, Peng Wu & Xiao-Hua Zhou (2022), RDLDR: Robust Debiasing Loop Doubly Robust Learning for Post-Click Conversion Rate Prediction.
[5] Haoxuan Li, Quanyu Dai, Yuru Li, Yan Lyu, Zhenhua Dong, Peng Wu & Xiao-Hua Zhou (2022), Multiple Robust Learning for Recommendation.
[6] Yan Lyu, Haoxuan Li, Chunyuan Zheng, Peng Wu & Xiao-Hua Zhou (2022), A Generic Unbiased Learning Framework from Explicit to Implicit Feedback with Unmeasured Confounders.
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。