推荐系统中模型自适应相关技术总结
© 作者|范欣妍
机构|中国人民大学高瓴人工智能学院
研究方向|推荐系统
本文介绍的是推荐系统中模型自适应的相关技术。本文将主要基于近三年已发表的顶会论文(ICML、ICLR、SIGIR、KDD、WWW、AAAI等),梳理了与模型自适应相关的研究工作,介绍了模型自适应常用的技术以及在推荐系统中的应用。这些技术可能来自其他研究领域,本文也会简单介绍模型自适应在这些领域的应用。文章最后列出了一些近期顶会的相关工作,供大家学习参考。
1. 什么是模型自适应(Model Adaptation)
模型自适应(Model Adaptation,简称MA)目前在多个领域已经成为研究热点。它的目标是在使用源训练数据和目标数据来最大化目标任务的表现。如下图所示,我们在丰富的源数据/训练数据上训练好一个原始模型(Original Model),在应用阶段用额外的任务相关的数据调整模型(Adaptation),得到适应后的模型(Adapted Model)来更好的适应目标任务/目标数据。模型自适应可以看做迁移学习的一种方式。考虑到训练数据和测试数据之间存在分布的不一致,如何利用少量的自适应数据(Adaptation Data)使源模型泛化到目标任务是一项关键挑战。
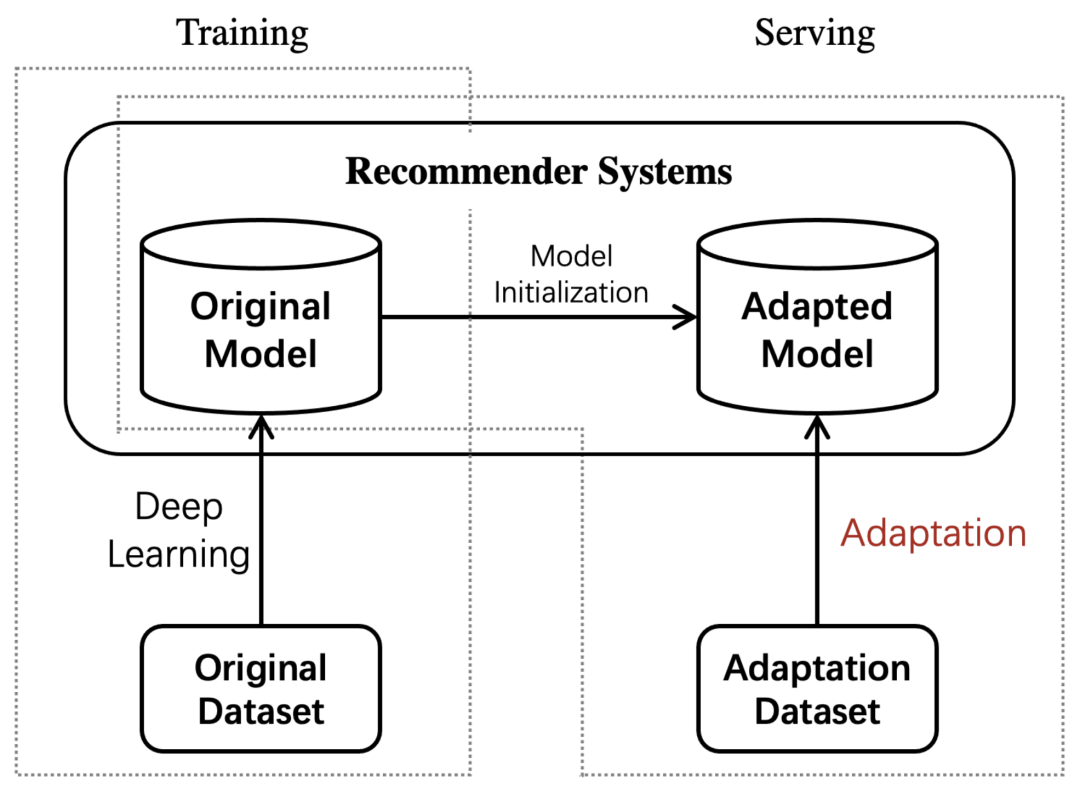
2. 推荐系统中为什么要进行Model Adaptation
目前的推荐系统服从“Offline Training”->“Online Serving”的结构,这种框架假设在在线服务时对于用户的不同请求的数据的分布是稳定的,且与线下训练模型时的数据分布是一致的。然而这种假设在现实中并不总是成立的。例如,受时效性的影响,推荐系统中的召回模块给出的数据分布是随着时间不断变化的,比如在新闻推荐中,选举期间召回的政治类新闻占比大,奥运会期间则体育类新闻更多;此外用户的请求也可能来自不同的领域,例如在电商平台,同一个用户可能会输入查询词“裙子”或“手机”,不同的请求下得到的数据分布不同,甚至与训练用的数据分布也不同。对于推荐系统中的这种动态服务(Dynamic Serving)需求,一个解决上述问题的思路就是使用模型自适应(MA)。
MA有三个典型的应用场景:
-
跨领域推荐【Cross-Domain Recommendation,包括单一目标域(single target domain)的传统跨领域推荐和多域(multiple domains)的多领域推荐】:目前的大型推荐系统通常服务于多个不同的域(例如新闻网页中的「热门新闻推荐板块」和「政治新闻栏目」),如果对每个域都训练一个模型代价太大;而且一些域的数据很稀疏,无法有效的训练好一个模型。一个好的思路是在混合多个域包含丰富信息的大数据集上训练一个模型,然后根据目标域的数据做adaptation,自适应地应用到不同的场景。
-
在线服务【Online Service】:线上应用线下已经训练好的推荐模型进行服务时,往往因为数据分布不一致(offline-online inconsistency)导致在线服务效果不好。频繁收集线上数据并在线下重新训练模型并不是一个高效的办法。一个比较自然的想法是应用模型自适应,通过捕捉线上数据的分布特征,调整原始模型,来适应到线上场景,减轻线上线下数据不一致带来的负面影响,以达到更好的线上服务效果。
-
用户冷启动【Cold-Start】:用户冷启动问题是推荐系统中最重要的挑战之一,它是指向新/冷用户推荐商品的任务,该用户的交互记录在系统中非常少。如何从以往不同的用户的交互数据学到一个模型,使得面对新的用户时能够借助以往学习的知识以及少量的样本快速适应到新用户的推荐任务中,在初始给出好的推荐来更好地留住用户,也是模型自适应一个重要的应用场景。
MA在其他研究领域的一些典型应用:
-
在NLP中,目前一个通用的范式是pre-train+fine-tune。先用大语料训练一个模型,然后使用下游数据对预训练好的语言模型进行微调,让模型适应到不同的下游任务。这种fine-tune的框架也可以看做是一种模型自适应。
-
在CV中,有一项任务是visual reasoning answer,即看图回答所给问题。模型需要根据问题来提取图片中需要的特征进行计算,不同的问题提取的特征应该不同。一些研究提出根据不同的问题,对模型参数做出自适应地调整,从而做出不同的回答。
-
在Speech中,自定义语音(Custom voice)是商业语音平台中的一种特定文本到语音的服务,该任务需要使用目标用户的少量语音调整一个训练好源模型,来自适应地合成目标说话者的个人语音库。

3. 相关工作
3.1 Transfer Learning (TL)
TL针对源任务训练模型,旨在提高模型在不同但相关的目标域/任务上的性能。Pre-train+fine-tune是迁移学习的常用策略,其中源域和目标域具有不同的任务且目标域的数据在训练时可以被用到。但是当目标域数据很稀疏时,传统的pre-train+fine-tune范式容易产生过拟合。后文将介绍的一些高效finetune的MA方法能有效避免这个问题。
3.2 Domain Adaptation(DA)
DA是一种特殊形式的迁移学习(直推式迁移学习),是在一个包含丰富标签信息的源数据上训练一个模型,能够很好的泛化到目标域。在DA中,目标域和源域的分布不同;且不一定需要根据目标域对训练好的模型做修改。本文的MA强调的是根据目标数据(可能来自与源数据来自同一个域,也可能不同;可能很大,也可能很小,例如冷启动时的一个用户)对模型做调整,适应到目标任务。DA可以看做本文MA的一种情况。
3.3 Multi-Task Learning(MTL)
MTL通过同时联合训练多个相关任务来优化模型。由于相关任务之间的知识共享,该模型为特定任务学习了更广阔的视角,可以更好地泛化。多任务学习可以在多个相关领域进行训练,以学习对每个原始领域都良好的模型,从而应用到多领域学习(例如,跨领域推荐),但并不在于增强对新任务/新数据的适应能力。
3.4 Online Learning(OL)
OL并不是一种模型,而是一种模型的训练方法,OL要求数据以流的方式顺序到来,并且能够根据线上的反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率。它的流程包括:将模型的预测结果展现给用户,然后收集用户的反馈数据,再用来训练模型。与MA不同,OL是一个不断更新模型的过程,且每次的更新是在获得真实反馈之后;而MA更强调如何在将预测结果展示给用户前,根据目标任务的数据对一个已经训练好的模型做调整(adaptation)。
4. 现有技术
本文梳理了与模型自适应相关的近期的研究工作,目前在推荐领域中涉及到的Model Adaptation的主要技术大致可以分为以下三类:
-
Parameter Patch:这类方法的核心是在原始网络中插入一些参数补丁,根据目标域的数据训练/调整补丁的参数,来达到自适应到目标任务的效果;
-
Feature Modulation:这类方法的假设是在源域上学到的表示与目标域不在同一个空间,因此他们关注于如何使用目标域的数据对原有模型得到的特征表示变换到目标域空间中;
-
Meta Learning:这类方法的目标是将task视作样本,通过对多个task的学习,以使训练好的模型能够根据少量数据快速适应到新的task,从而做出准确的学习。目前主要应用在冷启动任务中。
下面将对这三类Adaptation的方法进行介绍。
4.1 Parameter Patch
-
Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation. SIGIR 2019.
许多的推荐系统为用户项交互序列建模, 但很少有人尝试迁移模型来服务于不同的下游任务。这篇文章的任务:在具有丰富序列交互信息的源域上学习一个通用的用户表示模型,并将其迁移到目标域上的各种任务中(在目标域中,用户是冷的或新的)。
pre-train + fine-tune是实现适应下游任务的一个简单有效的方法,但是作者发现:1)fine-tune每个任务的附加输出层,在推荐场景中表现不佳;2)fine-tune最后(几个)隐藏层与输出层一起,表现良好但是需要需要大量的工作来确定fine-tune哪几层;3)fine-tune整个网络不高效,而且如果目标域的数据比较稀疏的时候,fine-tune整个网络容易产生过拟合现象。
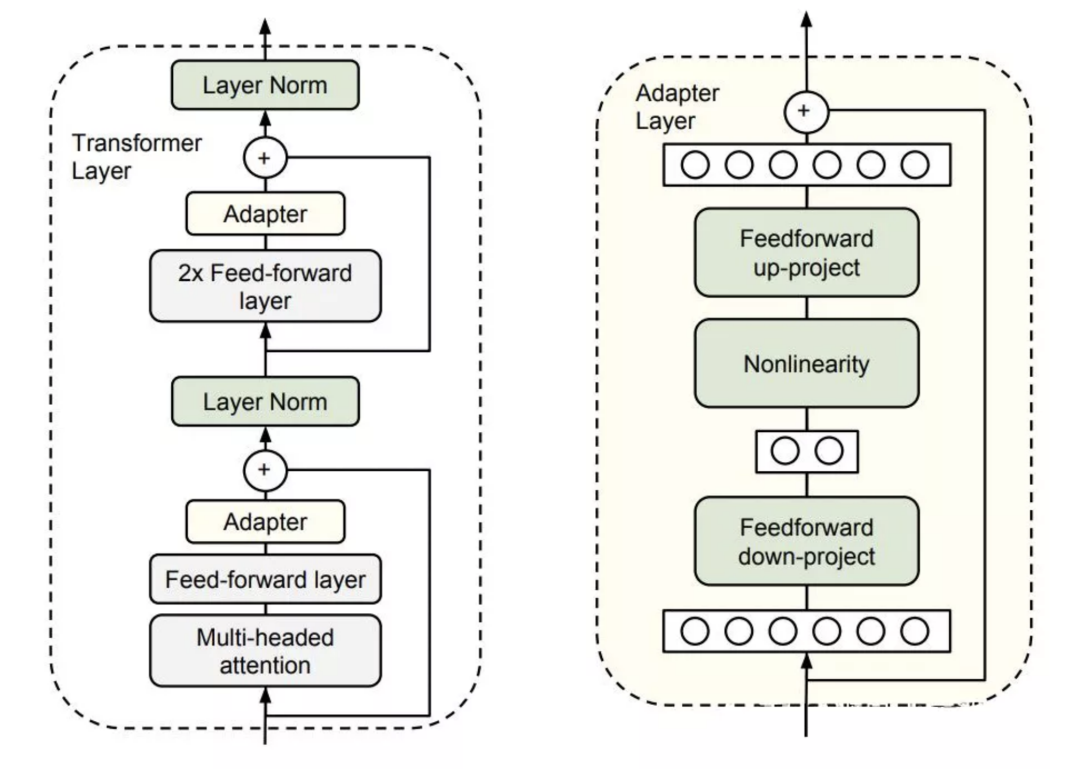
本文提出的高效fine-tune的灵感来自于Adapter-Tuning in NLP,这篇工作的思路是将 Adapter (下图中黄色方块,为bottleneck状的两层FFN网络)加入到 Transformer 中,在针对某个下游任务微调时,仅仅改变 Adapter 的参数。
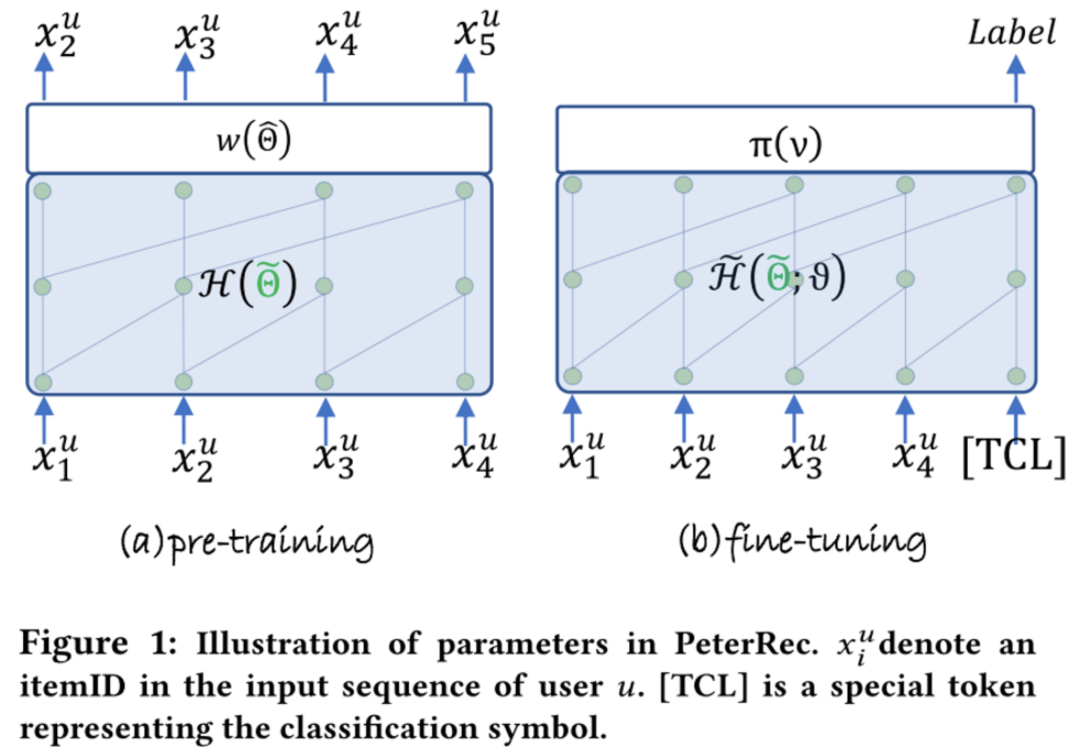
基于此,本文提出了PeterRec,其目标是在包含丰富的user-item交互序列的源数据集上进行pre-train,训练模型网络的参数 和输出层参数 ;在fine-tune阶段,对于目标域的任务,固定模型参数 ,只fine-tune插入在网络中的patch的参数和输出层参数。实验结果显示,这种只fine-tune少量参数的方式不仅可以达到fine-tune大模型同样的效果,而且有效避免过拟合。
本文提出了四种不同的Model Patch(MP)的插入方式,分为串行插入和并行插入。
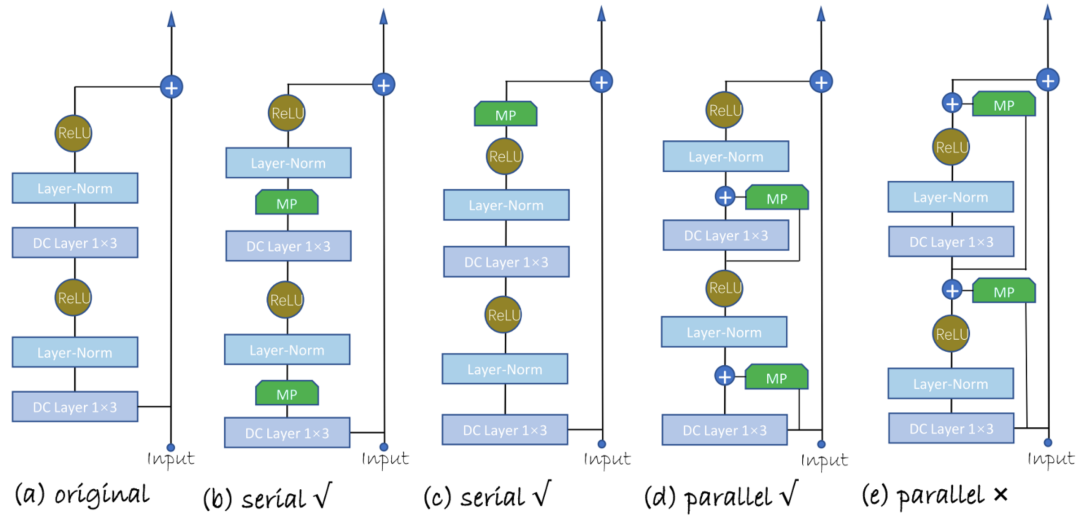
MP的结构与Adapter类似,是一个类似bottleneck的一维卷积网络。
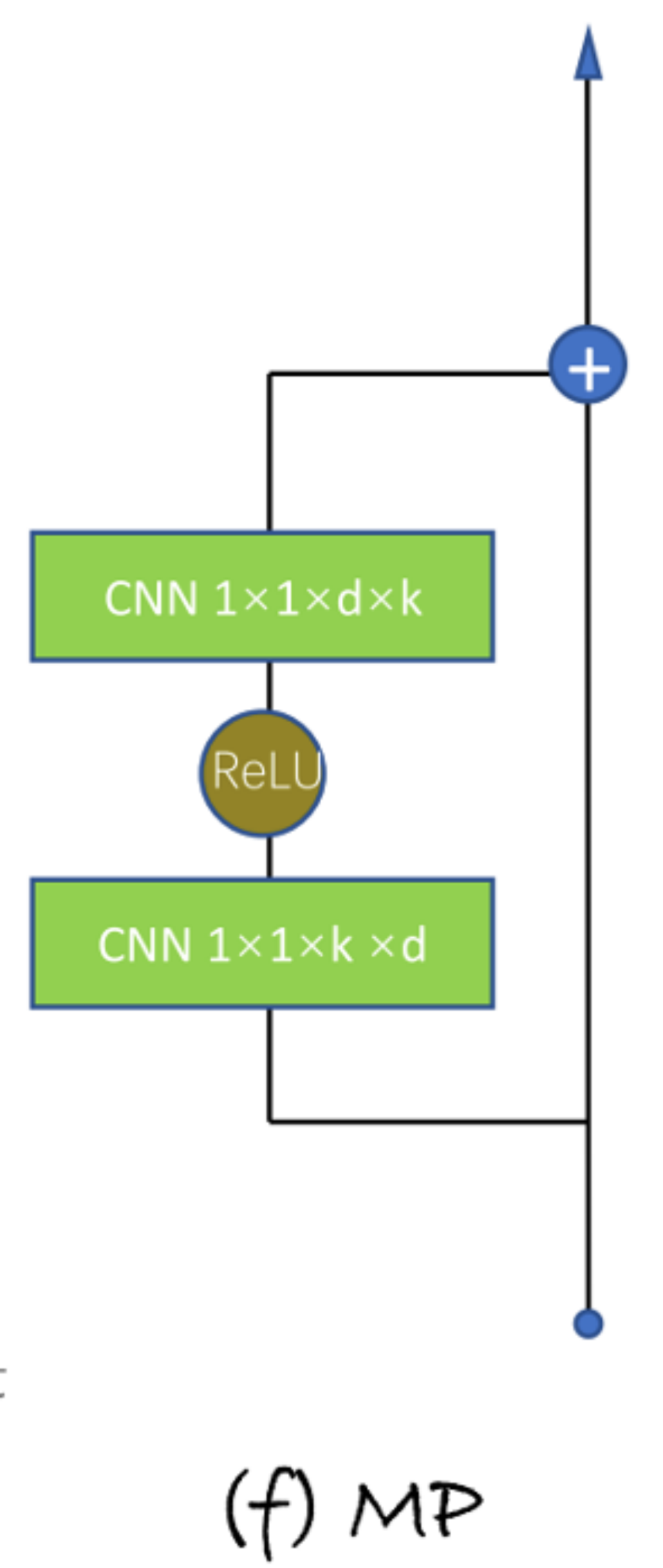
-
One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction. CIKM 2021.
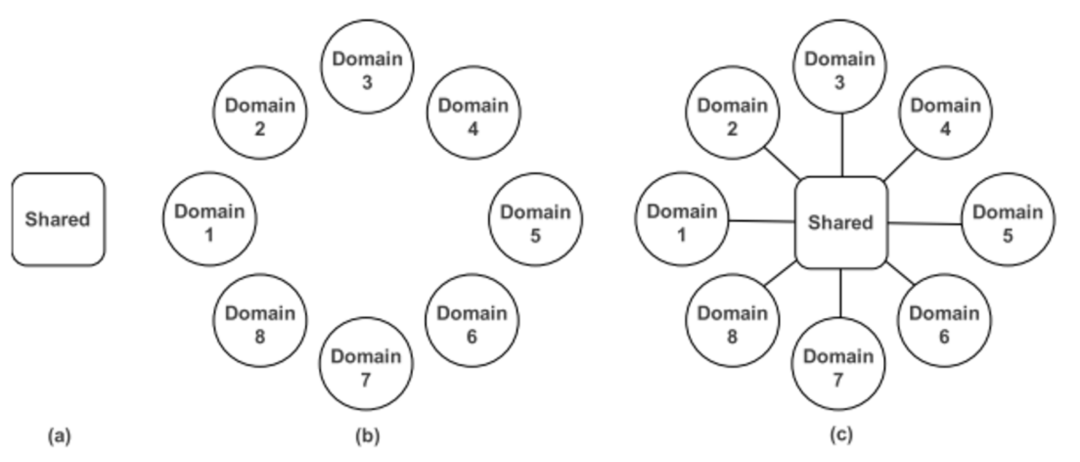
传统的推荐系统通常使用单个域中的数据来训练模型,然后服务于该域的任务。然而,一个大规模的推荐系统通常需要服务于多个域。如果使用共享的大模型(图(a)),很可能在一些子域表现不好;如果对每一个域单独训练一个模型(图(b)),则开销太大。因此本文综合这两点(图(c)),既用一个共享的网络学习全局的信息,又为每一个域各自设计了一个网络,来学习每个域特有的知识。
STAR(Star Topology Adaptive Recommender)的出发点是如何在源数据上训练一个大模型,使得其能够适应到不同的域,无论是整体还是在单个域的表现都很好。该任务也被称作multi-domain learning。STAR的核心在于提出了一个具有星型拓扑结构的全连接层(Star Topology FCN),它具有一个中心的FCN用来共享全局的信息,同时为每一个域单独训练一个FCN,作为domain-specific的参数。
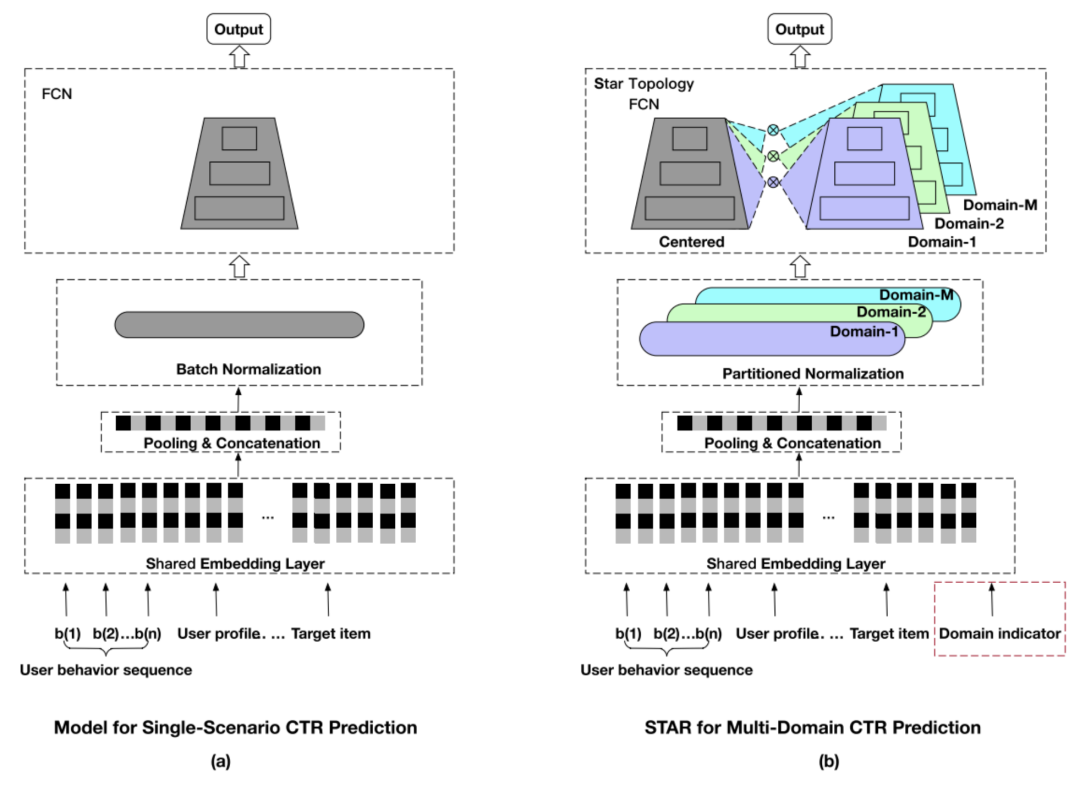
针对某一个域下的CTR任务,模型将shared FCN(参数 )和domain-specific FCN(参数 )通过下面的公式:
结合起来,得到最终用于预测的FCN。
Domain-specific FCN可以看做对单模型的中一种Model Patch,即在原始网络中插入针对不同域任务的网络,根据每个域的数据训练各自的Patch网络,从而让模型达到在各自域的任务上以及总体效果都不错的目的。
其他相关的工作:
-
BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning. ICML 2019.
-
K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters. AAAI 2020.
-
Pretrained Transformers As Universal Computation Engines. 2021.
4.2 Feature Modulation
对于模型中学到的Feature做Modulation的工作中,主要的技术可以大概分为对特征做仿射变换(Affine Transformation)和对特征进行条件归一化(Conditional Normalization)。
4.2.1 Affine Transformation
-
FiLM: Visual Reasoning with a General Conditioning Layer. AAAI 2018.
FiLM学习通过基于某些输入对神经网络的中间特征应用仿射变换,自适应地影响神经网络的输出。在Visual Reasoning任务中,模型需要根据问题自适应的调整CNN捕捉的特征。将问题用GRU编码后得到的表示作为FiLM的输入 ,通过两个神经网络学习( 和 )得到缩放 和偏差 ,接着对CNN学到的中间特征 做放射变换。FiLM会插入到每一个ResBlock中,对每一层CNN学到的特征进行modulation。
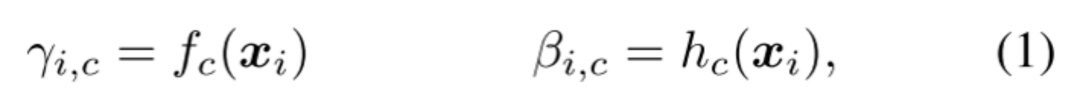
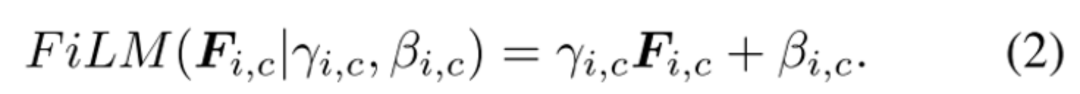
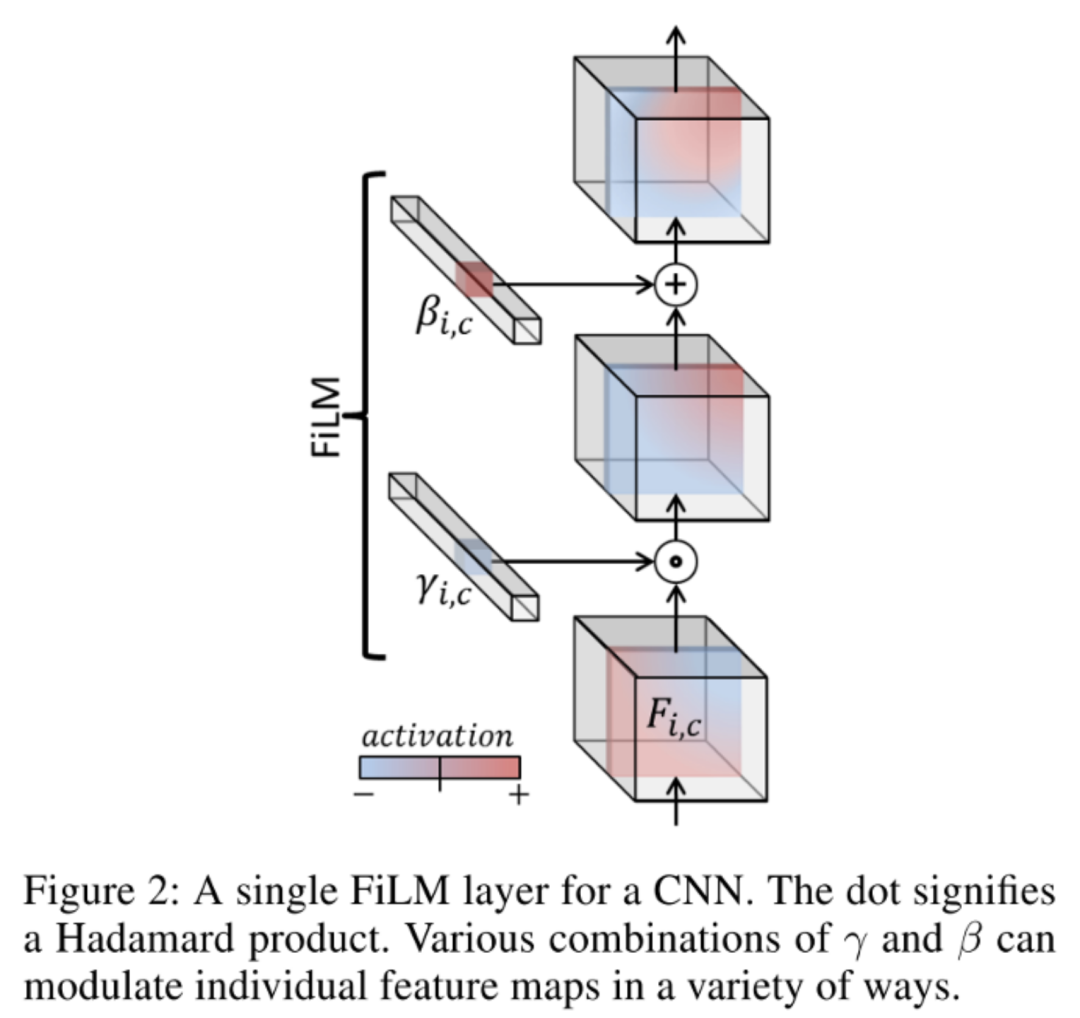
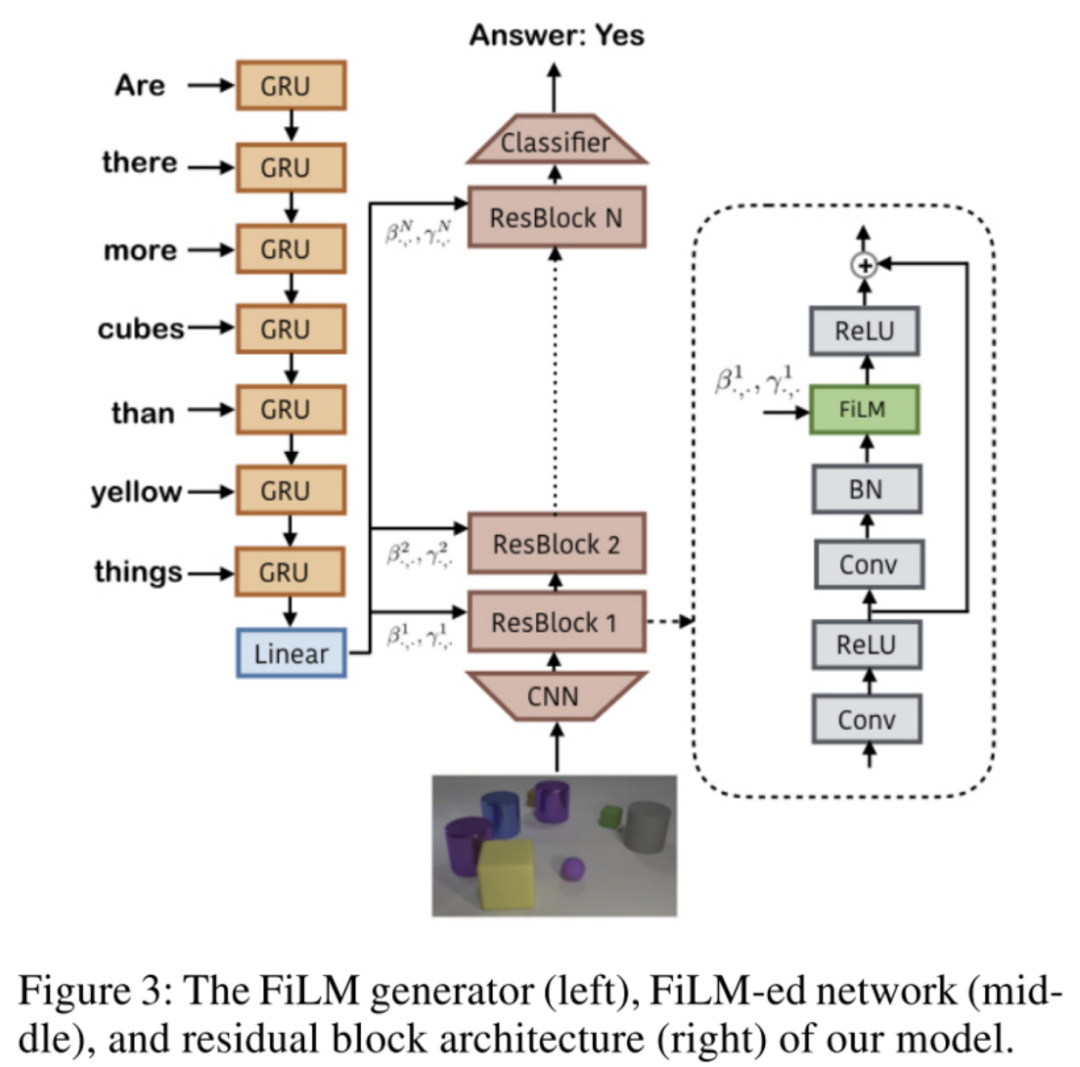
在某种程度上,可以将FiLM视为使用一个网络生成另一个网络的参数,使其成为超网络的一种形式。
-
Task-adaptive Neural Process for User Cold-Start Recommendation. WWW 2021.
大多数基于元学习的冷启动推荐模型是基于MAML(本章最后一节会详细介绍),旨在学习参数初始化(全局知识),通过几步的梯度更新达到新任务有良好表现的效果。当不同用户的兴趣表现高度相关时,这些方法表现良好。然而,当它们之间的任务相关性很弱时,就很难找到一个对所有用户都最优的共享参数初始化。因此本文的目的是捕获不同任务的相关性,并更有效地将以前任务中学到的全局知识适应到不同的用户。
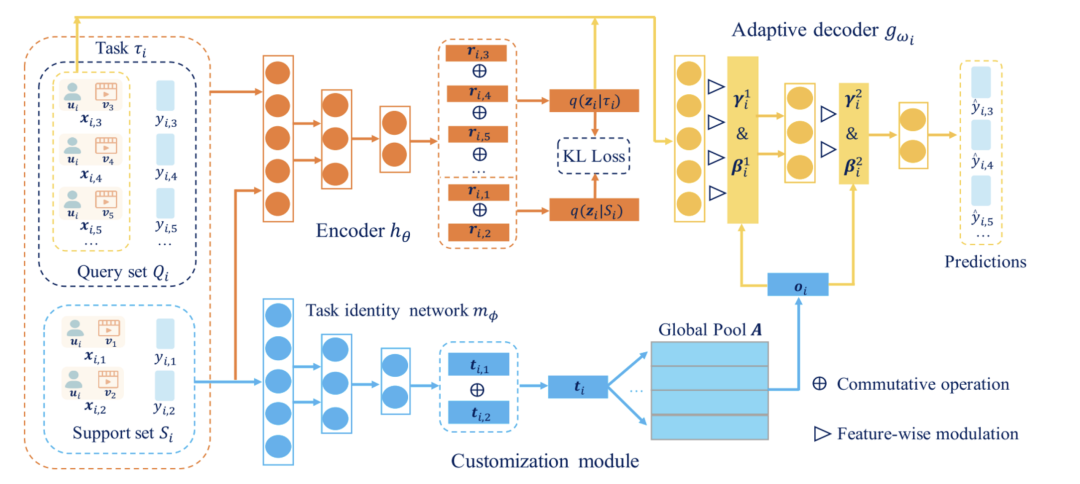
本文提出了TaNP,模型的前两部分Encoder和Customization Module分别对输入进行编码以及获取不同task相关性的表示。在自适应模块Adaptive Decoder中,TaNP将Customization Module学到的当前user的task embedding作为输入,使用FiLM两个生成的参数来缩放和移动decoder每一层的特征。对于每个用户的缩放和偏差都不同,以此达到了自适应解码的目标:
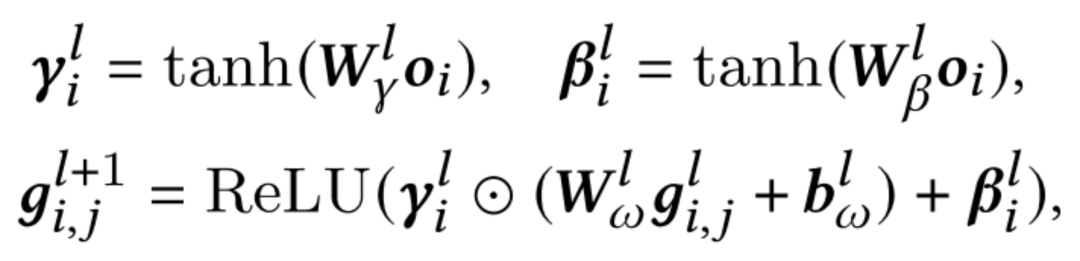
虽然FiLM可以有效地实现Feature Modulation,但一个潜在的问题是这种操作不能过滤一些对学习有相反影响的信息。为了缓解这个问题,增强对自适应过程中产生相反影响的信息的过滤能力,本文提出了一种更通用的Gating-FiLM,在FiLM的基础上引入了 和 ,具体公式如下:
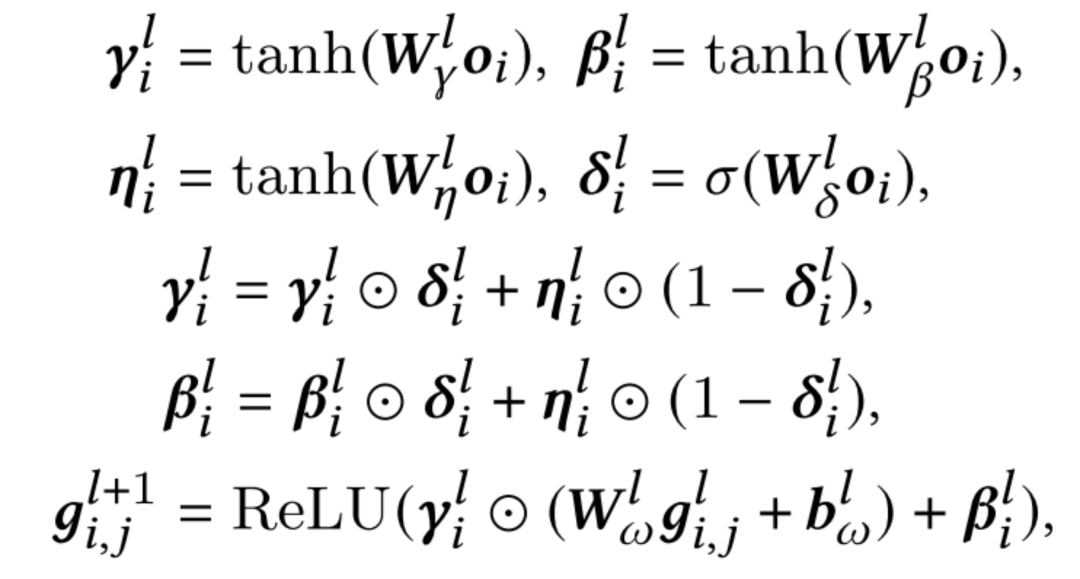
4.2.2 Conditional Normalization
这一类方法假设一个batch中包含不同类别的训练数据,放在一起做Normalization不太妥当,因为不同类别的数据理应对应不同的均值和方差,其归一化的放缩和偏置也应该不同。针对这个问题,一个解决方案是不再考虑整个 batch 的统计特征,而是根据不同的条件做不同的归一化。
-
Modulating early visual processing by language. NIPS 2017.
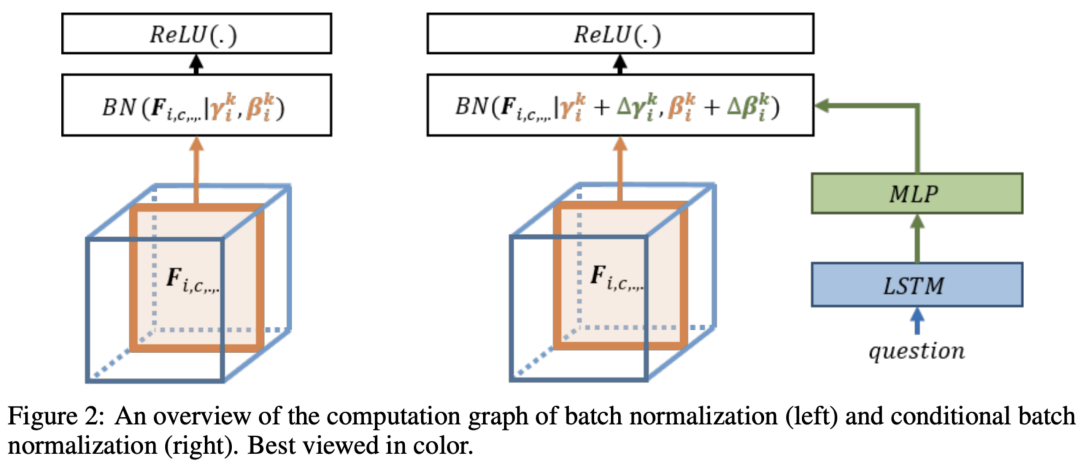
本文最早提出Conditional Batch Normalization。作者提到,ResNet 是预训练的网络,用于提取图片特征,不能轻易修改里面 filter 的参数。而其中的 BN 层包含两个参数:缩放和偏差,用于对 feature施加缩放和偏置操作,从图片含义上讲可以解释为:强调feature的某部分channel,忽略另外一些channel。而且修改BN的参数量不大,因此作者决定把问题提取出的特征输入到MLP中生成 和 ,来修正 和 ,即根据不同的问题自适应地调整提取图片的部分信息。
-
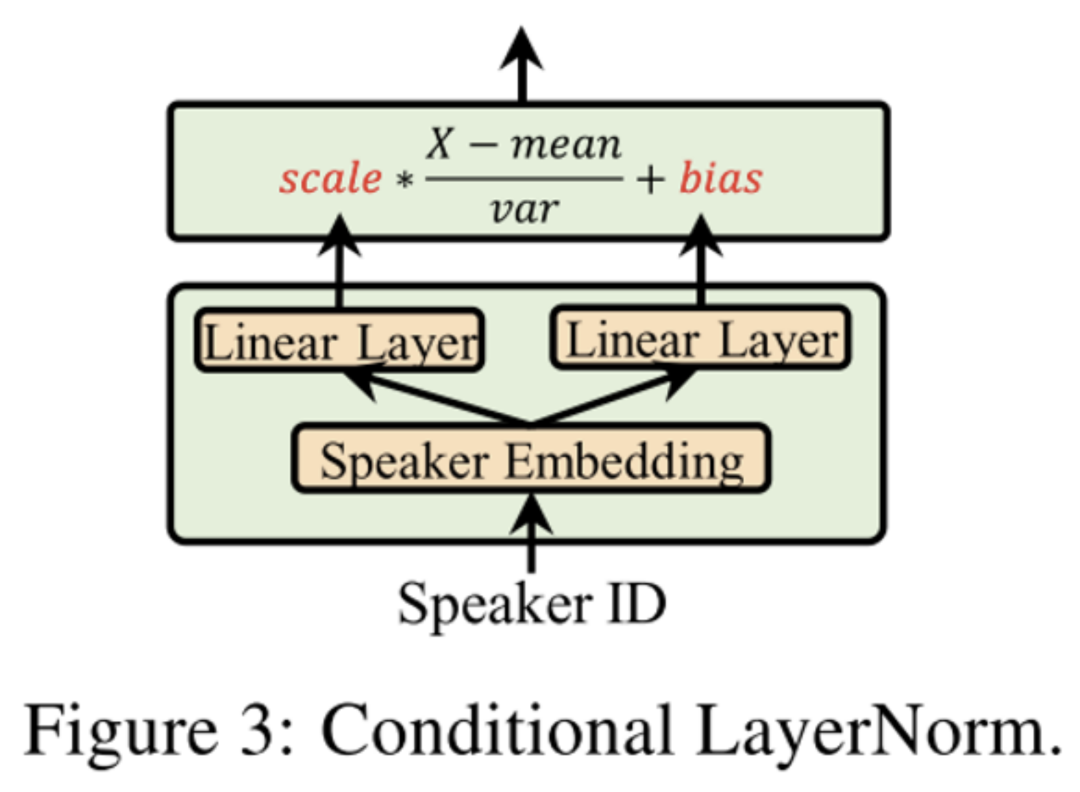
AdaSpeech: Adaptive Text to Speech for Custom Voice. ICLR 2021.
这是一篇Speech领域做自适应的工作。语音个性化定制(custom voice)是一项非常重要的文本到语音合成(text to speech, TTS)服务。其通过使用较少的目标说话人的语音数据,来微调(适配)一个源 TTS 模型,以合成目标说话人的声音。AdaSpeech做了两方面的feature级别的自适应。
第一,将少量自适应数据用于个性化语音,通过对不同粒度的声学条件进行建模(Acoustic Condition Modeling)并融入原有的hidden state中,对网络中隐藏的状态向量进行调制(modulation),用以支持含有不同类型声学条件的语音数据。
第二,使用了条件层归一化(Conditional LayerNorm):为了确保自适应质量的同时fine-tune尽可能少的参数,AdaSpeech在预训练时修改了解码器中LayerNorm,使用目标speaker的嵌入表示作为条件信息,在层归一化中直接生成放缩和偏差向量(而不是对原来的参数做补充)。在fine-tune阶段,只调整与Conditional LayerNorm相关的参数。通过这种方式,与fine-tune整个模型相比,可以大大减少自适应参数和计算开销,更加符合线上应用的场景;同时由于Conditional LayerNorm的灵活性,每个speaker的归一化放缩与偏差都不一样,模型可以保持高质量的自适应化语音。
-
One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction. CIKM 2021.
STAR提出的Partitioned Normalization(PN),是对BatchNorm做了自适应归一化。在多域CTR预测中,样本应当仅仅假设为在特定域内满足i.i.d。因此,来自不同领域的数据具有不同的归一化矩,对全部样本共享BN层是不合理的。为了捕获每个域中独特的数据特征,本文提出了分区规一化(Partitioned Normalization,PN),它将不同域的规范化统计数据和参数私有化。具体而言,在训练过程中,为每一个域单独训练放缩系数 和偏差 ,再与全局共享的缩放 和偏差 结合。
BN:
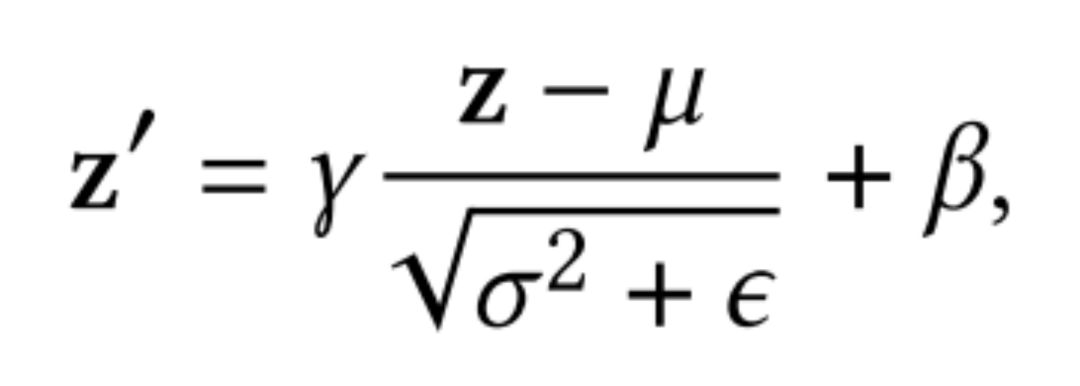
PN:
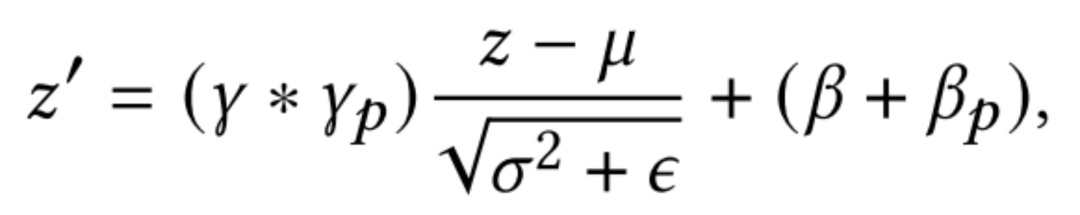
其他相关的工作:
-
Dynamic Instance Normalization for Arbitrary Style Transfer. AAAI 2020. (Instance级别的动态Normalization)
-
Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks. 2021. (借鉴FiLM,通过超网络生成Task Conditional Adapter Layers)
4.3 Meta Learning
相对于deep learning在一个task中通过对样本的学习以对新样本做出判断,元学习的目标可以看做是将task视作样本,通过对多个task的学习,以使元模型能够快速适应到新的task,做出准确的学习。
-
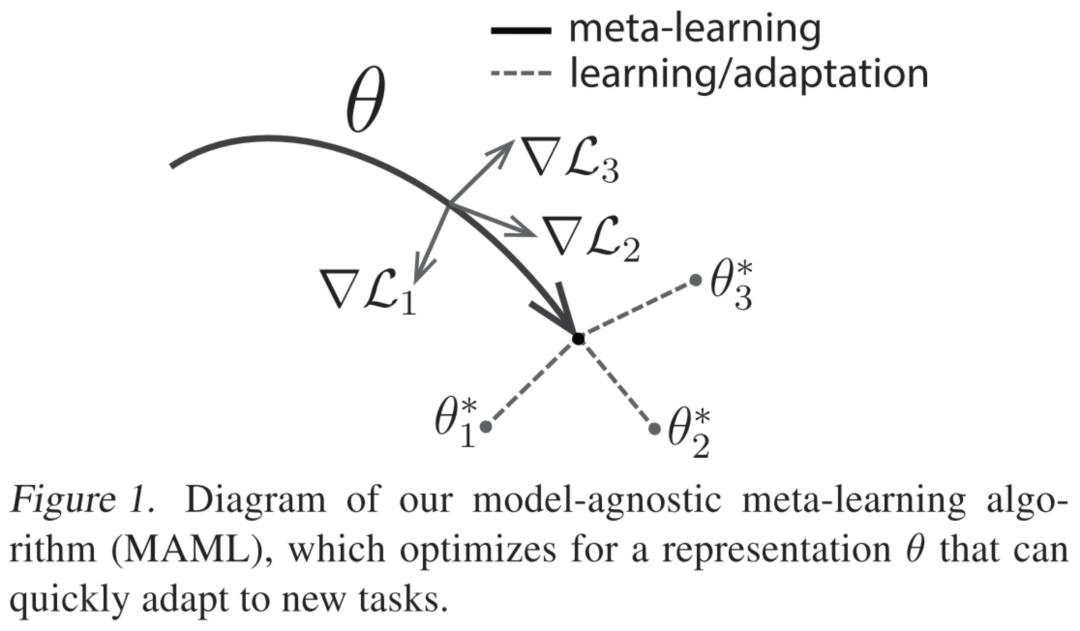
MAML:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. ICML 2017.
MAML的设想是训练一组初始化参数,通过在初始参数的基础上进行一或多步梯度的调整,来达到仅用少量数据就能快速适应新task的目的。为了达到这一目的,训练模型需要最大化新task的loss function的参数敏感度,当敏感度提高时,极小的参数(参数量)变化也可以对模型带来较大的改变。MAML算法可以适用于多个领域,不需要通过扩充模型的参数量,无需限制模型结构(如限定RNN网络),并且可以根据不同的问题使用不同的loss函数。既然希望使用训练好的模型仅通过几步梯度迭代便可适用于新的task,作者便将目标设定为,通过梯度迭代,找到对于task敏感的参数 。如图所示,训练完成后的模型具有对新task的学习域分布最敏感的参数,因此可以在仅一或多次的梯度迭代中获得最符合新任务各自的 ,达到较高的准确率。
对于少样本监督学习(few-shot supervised learning),MAML所做的是对每个task,先取一部分样本与标签(一般认为是support set),将其用于第7行的第一次梯度更新;再取另一部分样本与标签(query set),统一用第10行的第二次梯度更新,其伪代码流程图如下图所示:

-
MeLU: Meta-Learned User Preference Estimator for Cold-Start Recommendation. KDD 2019.
本文主要提出了MeLU模型,使用MAML去解决推荐系统的用户冷启动问题。先前的冷启动推荐研究主要有两个不足:(1)用户只有非常少量的物品交互数据不足以进行很好的推荐;(2)不充分的候选物品被用于识别用户偏好。本文提出一种基于元学习的推荐系统MeLU,可以在很少量的物品条件下估计一个新用户的偏好。它采用MAML来学习一个深度推荐模型共享的初始化参数,然后针对每一个冷启动用户,使用有限的交互数据来对这个初始化参数进行微调,得到用户定制化的模型进行推荐。
基于元学习的推荐任务有一些通用的设定:为一个用户进行推荐被视为一项任务。每个任务都拥有其支持集(Support Set)和查询集(Query Set)。在训练阶段,模型在支持集上学习,并在查询集上更新。在测试阶段,根据支持集中的少量交互推断冷启动用户的偏好。
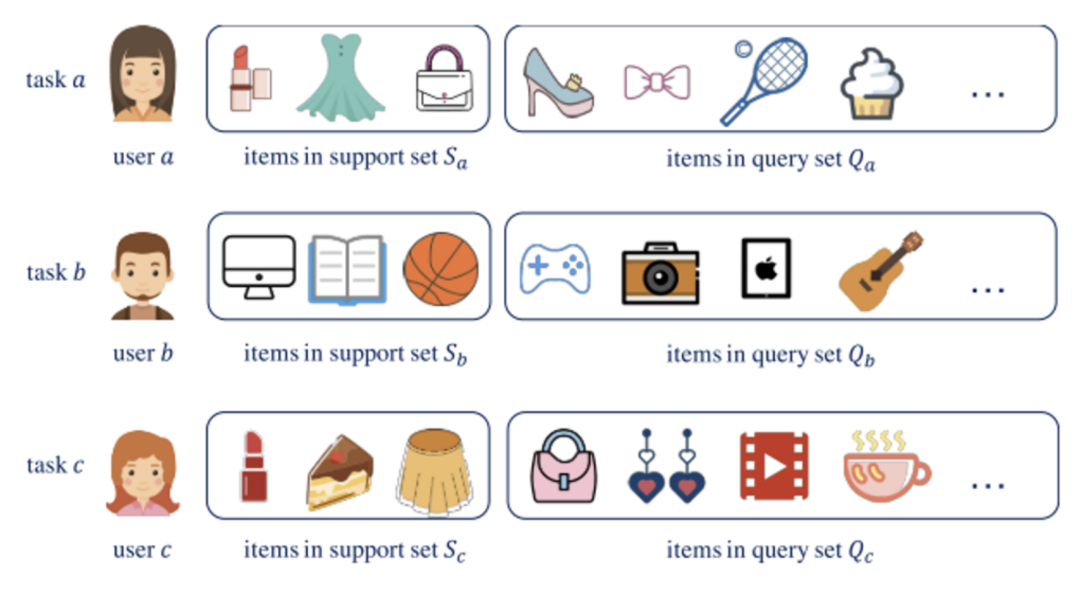
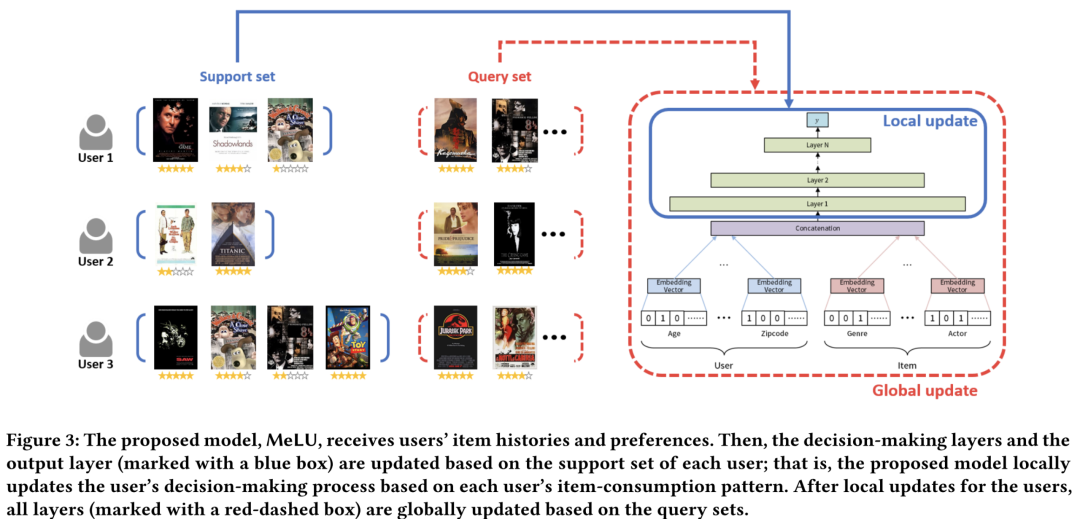
MeLU在每一轮训练过程中,挑选一定数量的用户(相当于MAML中的Task)进行采样得到支持集,获得少量的交互数据后,计算在支持集上得到的训练loss,并计算对应的梯度实现局部更新。每个用户进行局部更新的目的是,模拟让模型对新的用户进行学习的过程。在全局更新阶段则是对所有用户再次采样得到的查询集上进行的,每个用户的查询集上均可以得到测试loss,并平均后计算梯度。
其他相关的工作:
-
Meta-Learning for User Cold-Start Recommendation. IJCNN 2019. (与MeLU类似,使用MAML的框架,但是对local更新参数时的步长做了限制,步长与global的更新步长有关。)
-
Fast Adaptation for Cold-Start Collaborative Filtering with Meta-learning. ICDM 2020. (CF中引入meta learning,同时提出了动态子图采样的方法,对于新用户能够自适应生成当前的任务表示。)
-
Personalized Adaptive Meta Learning for Cold-Start User Preference Prediction. AAAI 2021. (当用户偏好差异较大时MAML很难对不同用户都能做到快速更新,本文提出了一种个性化的自适应学习速率的元学习方法,给每个用户提供个性化的学习率,提高MAML的性能)
5. 总结与展望
模型自适应当前还是十分火热的,涉及到的研究领域也非常广泛。本文梳理了现在推荐系统中常用的一些模型自适应的相关技术,这些技术的源头可能来自于NLP、CV、Speech等多种领域,本文也一一做了详细的补充和介绍。
本文提到的模型自适应技术包括:1)补充参数补丁,根据目标域的数据训练/调整补丁的参数,以适应到目标任务;2)对特征进行变换,可以对模型中间的计算特征进行仿射变换,也可以对输入/输出特征进行条件归一化,让变换后的特征更加适应到目标任务;3)使用元学习,在冷启动推荐场景中,为每个新用户快速调整原模型,得到适应后的个性化模型进行推荐。
当然,模型自适应的技术不仅仅局限于本文所总结的这些,也有一些工作采用了强化学习、模型蒸馏、分布对齐等技术来完成模型自适应。以下列出了一些近期的相关工作,供大家学习参考:
-
近一年顶会推荐系统adaptation相关的:
-
Nonintrusive-Sensing and Reinforcement-Learning Based Adaptive Personalized Music Recommendation. SIGIR 2020. (在音乐推荐系统中使用强化学习动态适应当前用户的偏好。) -
MetaSelector: Meta-Learning for Recommendation with User-Level Adaptive Model Selection. WWW 2021.(使用来自所有用户的数据对一组推荐模型进行训练,在此基础上通过元学习对模型选择器进行训练,根据用户特定的历史数据为每个用户适配到最佳的单一模型。) -
A User-Adaptive Layer Selection Framework for Very Deep Sequential Recommender Models. AAAI 2021. (一个自适应的序列化模型推理框架,学习为每个用户自适应地跳过原有模型中非活动的隐藏层,每个用户做推理时保留的参数是不同的。类似于动态蒸馏。) -
Learning Personalized Itemset Mapping for Cross-Domain Recommendation. IJCAI 2020. (使用两个生成器来构建用户在两个不同域中的行为随时间变化的双向个性化项集映射,并不断优化生成的item集合与实际交互的item集之间的距离,缩小源域和目标域的差距。) -
Personalized Transfer of User Preferences for Cross-domain Recommendation. WSDM 2022. (用辅助源域中的冷启动用户之间的交互可以帮助目标域中的冷启动推荐。大多数现有方法建模一个公共偏好桥接器(preference bridge),为所有用户迁移偏好。本文则通过元学习,为每个用户生成自适应的偏好迁移函数,实现每个用户的个性化偏好转移。) -
一些相关的综述:
-
跨域推荐: -
Cross-Domain Recommendation: Challenges, Progress, and Prospects. -
A Survey on Cross-domain Recommendation: Taxonomies, Methods, and Future Directions. -
元学习: -
Meta-Learning in Neural Networks: A Survey. -
领域自适应: -
A Survey of Unsupervised Deep Domain Adaptation. -
Neural Unsupervised Domain Adaptation in NLP--A Survey. -
领域泛化: Generalizing to Unseen Domains: A Survey on Domain Generalization.
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于微信公众号试行乱序推送,您可能不再能准时收到机器学习与推荐算法的推送。为了第一时间收到干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于微信公众号试行乱序推送,您可能不再能准时收到机器学习与推荐算法的推送。为了第一时间收到干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


