地平线提出AFDet:首个Anchor free、NMS free的3D目标检测算法
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI算法修炼营 | 论文已上传,文末附下载方式

这是一篇由地平线机器人发表在CVPR2020 Workshop的文章,主要是将Anchor Free的思想应用于3D目标检测领域。同时,提出了一种NMS Free的思想,让模型在推理阶段更方便部署到嵌入式设备中。整体思想较为新颖,期待开源。
论文地址:https://arxiv.org/abs/2006.12671
在嵌入式系统上运行的高效点云3D目标检测对于许多机器人应用(包括自动驾驶)都非常重要。大多数以前的工作试图使用基于Anchor的检测方法来解决它,这有两个缺点:后处理相对复杂且计算量大;调整Anchor点参数非常棘手,并且是一个tricky。本文是第一个使用AFDet( anchor free and Non-Maximum Suppression free one stage detector)来解决这些缺点的公司。借助简化的后处理环节可以在CNN加速器或GPU上高效地处理整个AFDet。并且,在KITTI验证集和Waymo Open Dataset验证集上,AFDet无需花哨的技巧,就可以与其他Anchor-based的3D目标检测方法竞争。
在点云中检测3D目标是自动驾驶最重要的感知任务之一。由于功率和效率的约束,大多数检测系统都在车辆嵌入式系统上运行。开发对嵌入式系统友好的3D目标检测系统是实现自动驾驶的关键步骤。
由于点云的稀疏性质,直接在原始点云上应用3D或2D卷积神经网络(CNN)效率很低下。对于点云数据中的目标检测部分,大多数采用基于anchor的检测方法,而基于anchor的方法有两个主要缺点。首先,非最大抑制(NMS)是基于anchor的方法所必需的,它可以抑制重叠的高置信度检测边界框。但是它可能会带来不小的计算成本,尤其是对于嵌入式系统。根据实验,即使在现代高端台式机CPU上,处理一个KITTI 点云框架也要花费20毫秒以上的时间,更不用说计算平台为嵌入式系统的情况。其次,基于anchor的方法需要选择anchor,这很棘手且耗时,因为调整的关键部分可能是手动尝试和错误过程。例如,每次将新的检测类别添加到检测系统时,都需要选择超参数,例如适当的anchor编号,anchor大小,anchor角度和密度等。
我们能否摆脱NMS并设计出对嵌入式系统友好的高效anchor free 3D点云目标检测系统?在本文中,基于anchor free思想提出了一种无anchor和无NMS的具有简单后处理的一阶段端到端3D点云目标检测器(AFDet)。
在本文的实验中,使用PointPillars将整个点云编码成伪图像或鸟瞰图(BEV)中类似图像的特征图。然而,AFDet可以与任何点云编码器一起使用,它可以生成伪图像或类似图像的2D数据。
编码后,应用上采样necks的CNN输出特征图,连接到五个不同的heads来预测BEV平面上的物体中心,并回归3D边界框的不同属性。最后,将五个heads的输出结果合并在一起,生成检测结果。其中,关键点热图预测head用于预测BEV平面内的物体中心,每一个物体都将被编码成一个以热峰为中心的小区域。 在推理阶段,每一个热峰都会通过最大池化操作被挑出来,之后,不再有多个回归的anchor被平铺到一个位置,因此不需要使用传统的NMS。这使得整个检测器可以在典型的CNN加速器或GPU上运行,节省了CPU资源用于自动驾驶的其他关键任务。
由于LiDAR提供了准确的3D空间信息,基于LiDAR的解决方案在3D对象检测任务中占了上风。
LiDAR-based 3D Object Detection
由于长度和顺序不固定,因此点云为稀疏和不规则格式,在输入到神经网络之前需要对其进行编码。一些研究利用网状网格将点云体素化。诸如密度,强度,高度等特征在不同的体素上作为不同的通道连接在一起。体素化的点云要么投影到鸟瞰图BEV,Range View(RV)等不同的视图,然后通过2D卷积处理,要么保存在3D坐标中以通过稀疏3D卷积处理 。
PointNet 提出了一种有效的解决方案,使用原始点云作为输入进行3D检测和分割。PointNet运用多层感知器(MLP)和最大池操作来解决点云的混乱和不均匀性。后续的工作有:PointNet ++ 、Frustum PointNet 、PointR-CNN 和STD 。VoxelNet结合了vox-elization和PointNet提出了Voxel特征提取器(VFE),在每个体素内实现了PointNet样式编码器。
在基于anchor的方法中,提供了预定义的框用于边界框编码。但是,使用密集的anchors会导致潜在目标对象的数量很多,这使得NMS成为不可避免的问题。PointRCNN 提出了基于全场景点云分割的不带anchor框的3D候选区域生成子网络。VoteNet 从投票的兴趣点构造3D 边界框,而不是预定义的anchor框。但是它们都不都是NMS free的,这使它们效率降低并且对嵌入式系统不友好。
Camera-based 3D Object Detection
通过设计更复杂的网络,基于摄像头的解决方案正迅速追上基于LiDAR的解决方案。MonoDIS 利用2D和3D检测损失的新颖的disentangling 变换和3D边界框的新颖自监督置信度得分,在nuScenes 3D对象检测挑战中获得最高排名。CenterNet 从特征图上检测边界框的中心并以此预测目标对象的位置和类别。尽管CenterNet最初是为2D检测而设计的,但它也具有使用单目相机进行3D检测的潜力。TTFNet 提出了缩短训练时间并提高推理速度的技术。RTM3D 预测图像空间中3D边界框的九个透视关键点,并通过几何规则恢复3D边界框。
论文地址:https://arxiv.org/abs/1812.05784
代码地址:https://github.com/nutonomy/second.pytorch
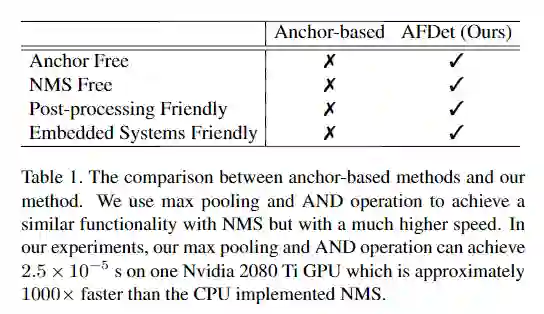
主要思路:设计一个仅仅使用二维卷积就能实现端到端的3D点云学习,适合于点云的编码器;学习点云的柱子(垂直列)上的特性,从而为对象预测面向3D的框。速读比较快,精读较高;
Pillar 方式编码:point clouds --> (D, P, N),p 是non-empty pillar number, 具体使用 12000。N 是一个pillar内有points的数目, 具体本文使用100。D 是 channel number。(D, P, N)--> (C, P, N) --> (C, P) --> (C, H, W) --> (6C, H/2, W/2) --> bbox。
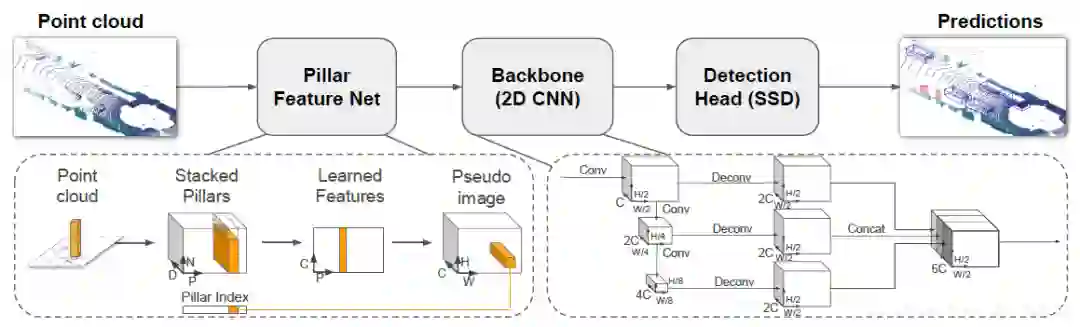
(1)生成伪图像
首先在俯视图的平面上打网格(H x W)的维度;然后对于每个网格所对应的柱子中的每一个点都取(x,y,z,r,x_c,y_c,z_c,x_p,y_p)9个维度。其中前三个为每个点的真实位置坐标,r为反射率,带c下标的是点相对于柱子中心的偏差,带p下标的是对点相对于网格中心的偏差。每个柱子中点多于N的进行采样,少于N的进行填充0。于是就形成了(D,N,P)D=9, N为点数(设定值),P为H*W。
然后学习特征,用一个简化的PointNet从D维中学出C个channel来,变为(C,N,P)然后对N进行最大化操作变为(C,P)又因为P是H*W的,我们再展开成一个伪图像形式,H,W为宽高,C为通道数。
(2)基础网络
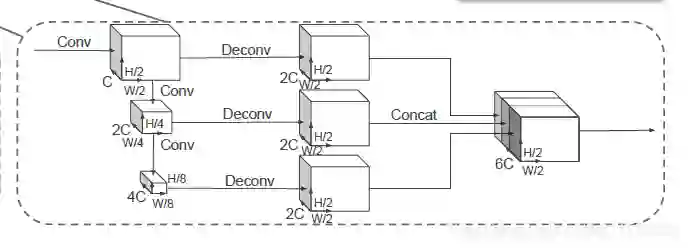
包含两个子网络(1、top-down网络,2、second网络)top-down网络结构为了捕获不同尺度下的特征信息,主要是由卷积层、归一化、非线性层构成的,second网络用于将不同尺度特征信息融合,主要有反卷积来实现。
(3)检测头和损失函数
检测头:SSD的检测头,目标高度和z轴单独回归。
损失函数:
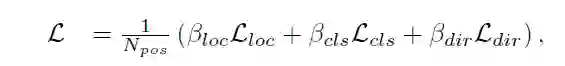
分类损失:采用focal loss
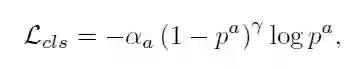
回归损失:
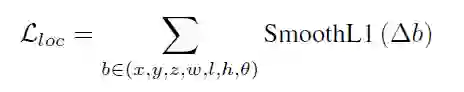
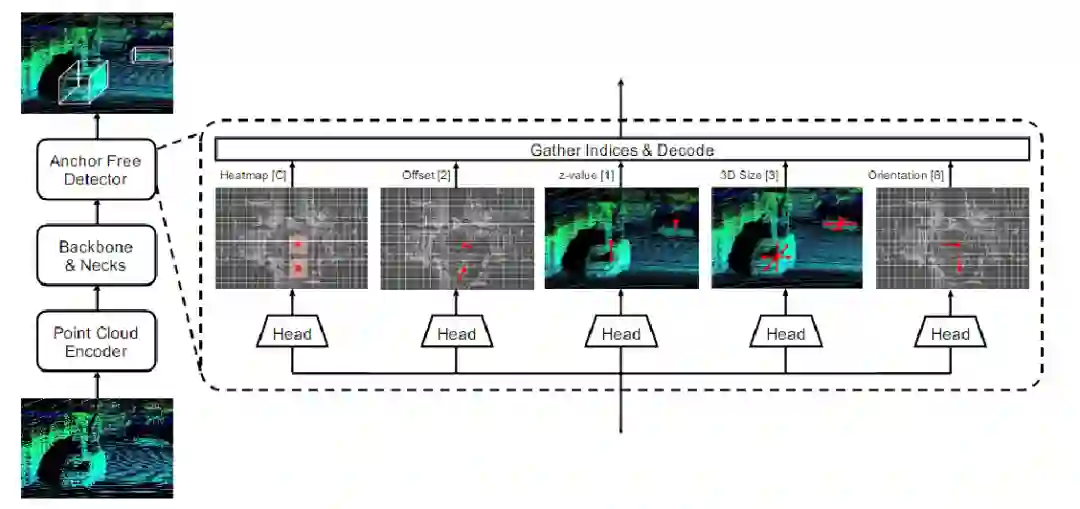
图1.AFDet系统的框架和anchor free检测器的详细结构。整个pipline由点云编码器、backbone和neck以及anchor free检测器组成。方括号中的数字表示最后一个卷积层的输出通道数。C是检测中使用的类别数。
1、Point Cloud Encoder点云编码器
为了进一步挖掘anchor free检测器的效率潜力,本文先将PointPillars 用作点云编码器,因为其速度快。首先,将检测范围离散为鸟瞰图(BEV)平面中的pillars (也就是x-y平面)。根据其x-y值将不同的点分配给不同的pillars 。在此步骤中,每个点也将增加到D=9维。第二,将对具有足够数量点的预定义pillars 经过线性层并执行max操作以创建尺寸为F×P的输出张量,其中F是在PointNet中的线性层的输出通道数。由于P是选定pillars 的数目,它们在整个检测范围内与原始pillars 不是一一对应的。因此,第三步是将选定的pillars 映射到检测范围内的原始位置。之后,就可以得到一个伪图像。具体步骤,可以参考上一部分介绍。尽管使用PointPillars 作为点云编码器,但本文的anchor free检测器与生成伪图像或类似图像的2D数据的任何点云编码器兼容。
2、Anchor Free Detector
本文的Anchor Free目标检测器由五个head组成。它们是关键点热图head,局部偏移head,z轴定位head,3D目标尺寸head和方向head。图1显示了Anchor Free目标检测器的一些细节。
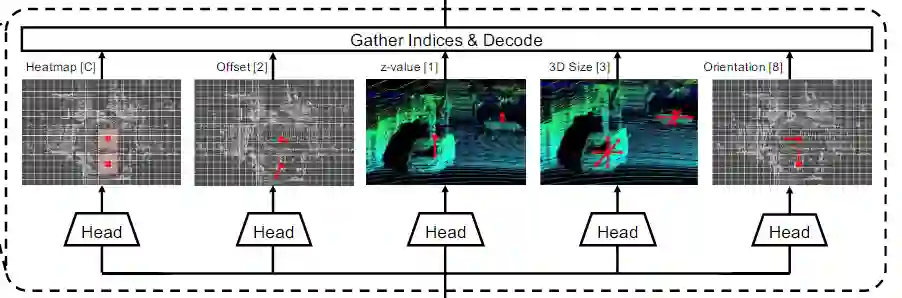
Object localization in BEV
对于热图head和偏移head,预测关键点热图和局部偏移回归图。关键点热图用于查找目标对象中心在BEV中的位置。偏移回归图不仅可以帮助热图在BEV中找到更准确的对目标象中心,而且还可以弥补因柱化过程引起的离散化误差。
将边界框参数化为,其中,分别表示LiDAR坐标系的中心位置、边界框的宽度,长度和高度、θ 是垂直于地面的绕z轴的偏航旋转。
表示在x-y平面的检测范围,在LiDAR坐标系中,前后方向沿x轴,左右方向沿y轴。在本文的工作中,柱面xy平面始终是一个正方形,因此,b表示支柱的边长。对于每个目标对象的中心,在BEV伪图像坐标中具有关键点
,BEV中的2D边界框可以表示为
。
对于伪图像的2D边界框中覆盖的每个像素(x,y),将其在heatmap中的值设置为
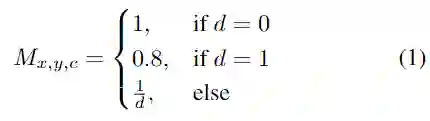
其中,d表示在离散的伪图像坐标中,边界框中心与相应像素之间计算出的欧几里得距离。预测的M= 1表示目标对象的中心,M= 0表示此柱是背景。
BEV中的代表目标对象中心的pillars 将被视为正样本,而所有其他支柱将被视为负样本。使用改进的focal loss来训练heatmap:
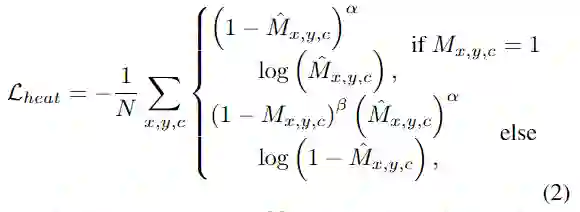
对于偏移回归head,有两个主要功能:首先,它被用来消除由柱化过程引起的错误,在该过程中,将浮点的目标对象中心分配给BEV中的 整型的pillar 位置。其次,它在完善热图目标对象中心的预测方面起着重要作用,尤其是当热图预测错误的中心时。具体来说,一旦热图预测到一个错误的中心,该错误的中心距离ground truth中心几像素远,则偏移head就具有减轻甚至消除相对于ground truth目标对象中心几像素误差的能力。
在偏移回归map中选择一个具有半径r围绕目标对象中心像素的正方形区域。距物体中心的距离越远,偏移值就越大,并使用L1 loss来训练偏移量。
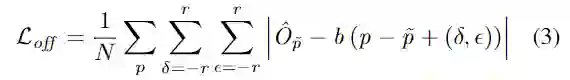
z-axis location regression
在BEV中进行目标对象定位之后,便只有目标对象 x-y location。因此需要z轴定位head来回归z轴值。使用L1 loss直接回归z值:
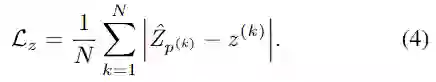
Size regression
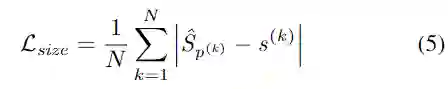
Orientation prediction
物体的方向θ与绕着垂直于地面的z轴旋转的标量角相交。将其编码为一个八标量,每个bin具有四个标量。两个标量用于softmax分类,另外两个标量用于角度回归。
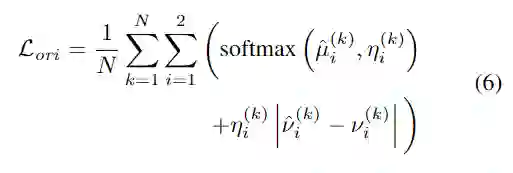
其中,,
,并且可以使用以下方法解码预测的方向值:
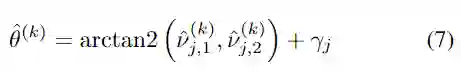
Gather indices and decode
在训练阶段,不对整个特征图进行反向传播。相反,仅反向传播作为所有回归head的目标对象中心的索引。在推理阶段,使用最大池化和AND操作在之后的预测热图中找到峰值,这比基于IoU的NMS更快,更高效。经过最大池化和与运算后,可以轻松地从关键点热图收集每个中心的索引。BEV中的最终物体中心将是,对于所有其他预测值,它们要么直接来自回归结果,要么通过上面的解码过程进行解码。物体的预测边界框为:
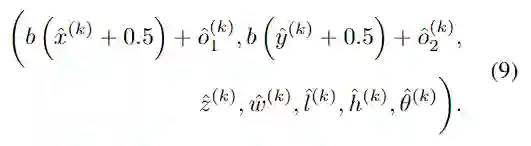
3、Backbone and Necks
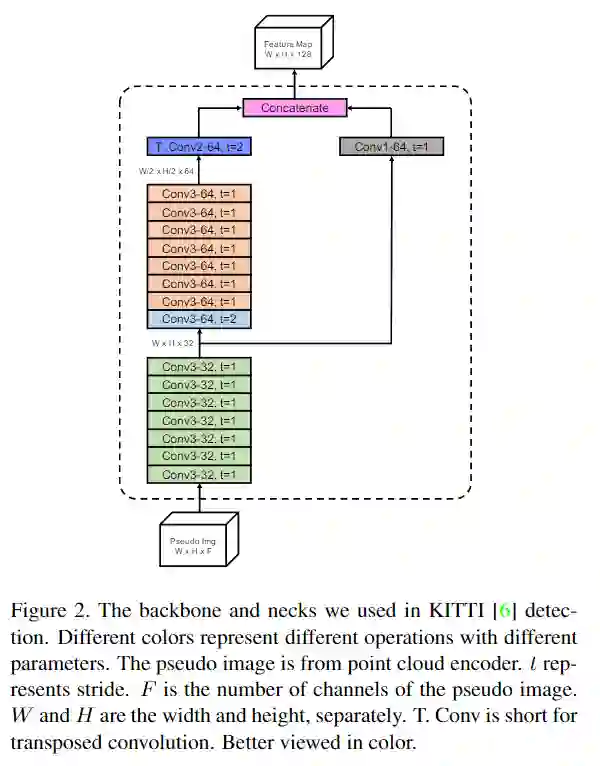
backbone部分类似于分类任务中使用的网络,该网络用于提取特征,同时通过不同块对空间大小进行下采样。neck部分用于对特征进行上采样,以确保来自主干不同块的所有输出具有相同的空间大小,以便可以将它们沿一条轴连接在一起。图2显示了主干backbone和neck的详细信息。在生成特征图的过程中,不会降低采样率,减少下采样的步幅只会增加FLOP,因此也减少了backbone和neck的卷积数量。
数据集: KITTI、Waymo
训练方法:将AdamW优化器与one-cycle 策略结合使用,用于不同子损失的权重为λoff= 1.0,λz= 1.5,λsize = 0.3且λori= 1.0。
关于各个数据集的具体设置和数据增强请参考原文。
实验效果

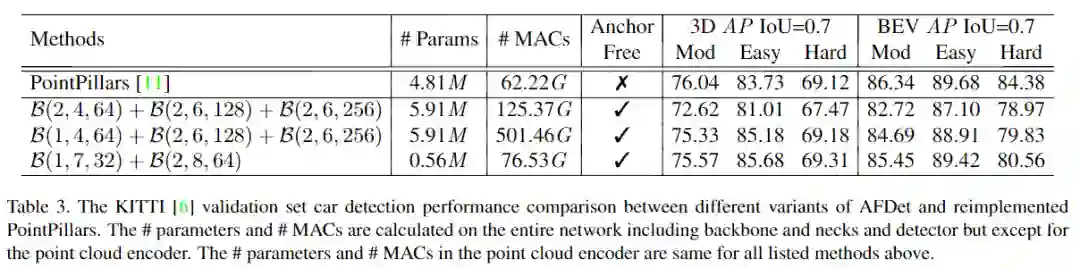
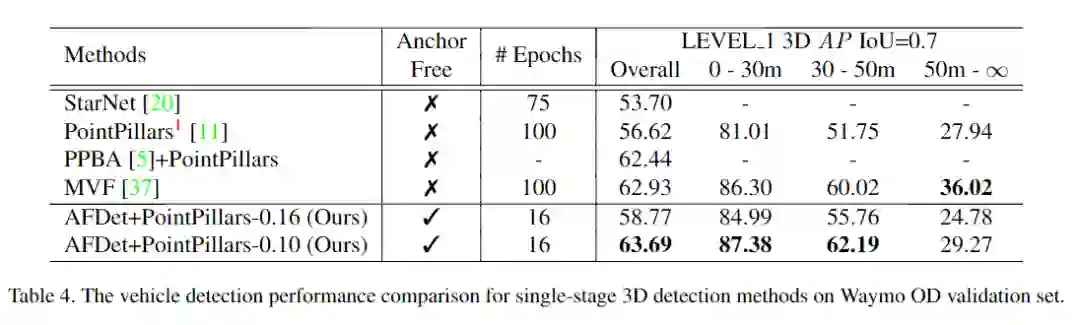
更多实验细节,可以参考原文。
参考:
https://blog.csdn.net/u011507206/article/details/89381872
论文下载
在CVer公众号后台回复:PyConv,即可下载本论文
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer一个在看!
