CVPR 2020 | 实时场景文本检测与识别新网络:ABCNet
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:吴建明wujianning
https://zhuanlan.zhihu.com/p/115991987
本文已由原作者授权,不得擅自二次转载
ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗

论文链接:https://arxiv.org/abs/2002.10200
摘要
场景文本的检测与识别越来越受到人们的关注。现有的方法大致可以分为两类:基于字符的方法和基于分割的方法。这些方法要么代价高昂,要么需要维护复杂的管道,这通常不适合实时应用。在这里,我们提出了自适应贝塞尔曲线网络(ABCNet)来解决这个问题。我们的贡献有三点:
1) 第一次,我们通过参数化的贝塞尔曲线自适应地处理任意形状的文本。
2) 我们设计了一个新的bezierallign层,用于提取任意形状文本实例的精确卷积特征,与以前的方法相比,显著提高了精度。
3) 与标准包围盒检测方法相比,我们的Bezier曲线检测方法的计算开销可以忽略不计,从而使我们的方法在效率和精度上都具有优势。在任意形状的基准数据集total Text和CTW1500上的实验表明,ABCNet达到了最新的精度,同时显著提高了速度。特别是,在全文本上,我们的实时版本比最新的状态识别方法快10倍以上,具有竞争性的识别精度。
1. Introduction
我们的主要贡献总结如下。
•为了精确定位图像中的定向和弯曲场景文本,我们首次引入了一种新的使用贝塞尔曲线的弯曲场景文本的简明参数化表示。与标准的边界框表示相比,它引入了可忽略的计算开销。
•我们提出了一种采样方法,即a.k.a.Bezier对齐,用于精确的特征对齐,因此识别分支可以自然地连接到整个结构。通过共享主干特征,识别分支可以设计成轻量级结构。
•我们方法的简单性允许它实时进行推理。ABCNet在Total Text和CTW1500这两个具有挑战性的数据集上实现了最先进的性能,展示了在效率和效率方面的优势。

1.1. Related Work
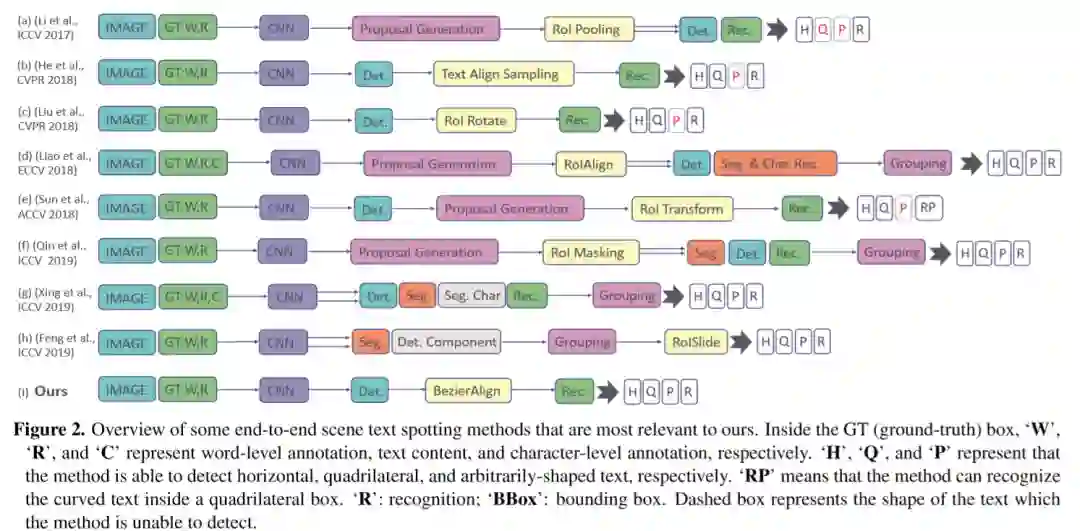
我们将几种具有代表性的基于深度学习的场景文本识别方法归纳为以下两类。图2显示了典型作品的概述。
Regular End-to-end Scene Text Spotting
Arbitrarily-shaped End-to-end Scene Text Spotting
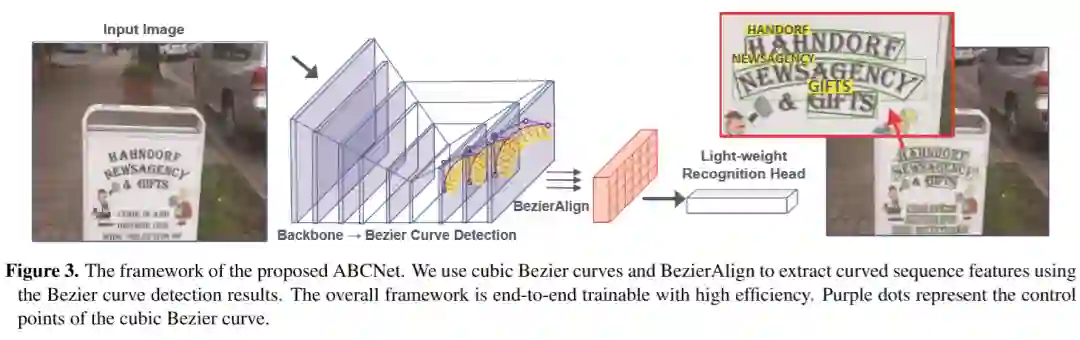
2. Adaptive Bezier Curve Network (ABCNet)
ABCNet是一个端到端的可训练框架,用于识别任意形状的场景文本。直观的管道如图3所示。受[47,37,12]的启发,我们采用了单点无锚卷积神经网络作为检测框架。移除锚定箱可以简化我们任务的检测。该算法在检测头输出特征图上进行密集预测,检测头由4个步长为1、填充为1、3×3核的叠层卷积层构成。接下来,我们分两部分介绍拟议的ABCNet的关键组成部分:
1) 贝塞尔曲线检测
2) bezierralign和识别分支。
2.1. Bezier Curve Detection
Bezier曲线表示参数曲线c(t),它使用Bernstein多项式[29]作为其基础。定义如等式(1)所示。
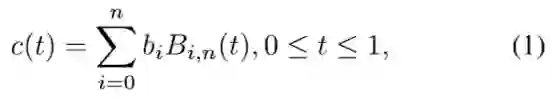
式中,n表示度数,bi表示第i个控制点,
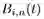
表示伯恩斯坦基多项式,如式(2)所示:
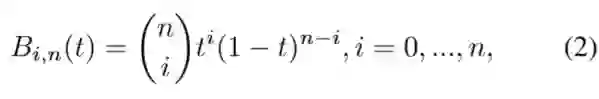
其中

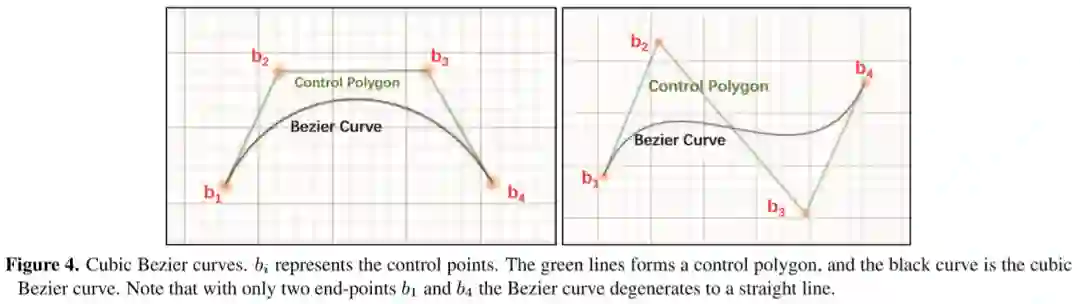
是二项式系数。为了用贝塞尔曲线确定文本的任意形状,我们从现有的数据集中全面地观察任意形状的场景文本。在现实世界中,我们通过经验证明,三次贝塞尔曲线(即n为3)在实践中对不同类型的任意形状的场景文本是足够的。三次贝塞尔曲线如图4所示。
2.1.1 Bezier Ground Truth Generation
在本节中,我们将简要介绍如何基于原始注释生成贝塞尔曲线地面真值。任意形状的数据集,例如Total text[5]和CTW1500[26],对文本区域使用多边形注释。给定曲线边界上的注记点
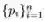
,其中pi表示第i个注记点,主要目标是获得方程(1)中三次Bezier曲线sc(t)的最佳参数。为此,我们可以简单地应用标准最小二乘法,如等式(4)所示:
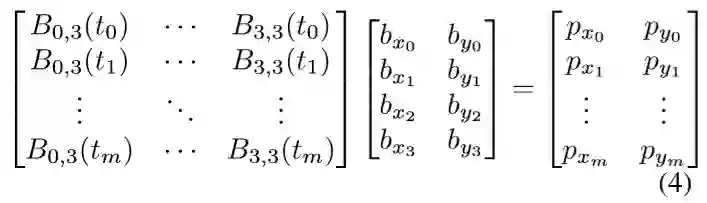
这里m表示曲线边界的注释点数量。对于total-text和ctw1500,m分别为5和7。t是通过使用累积长度与多段线周长的比率来计算的。根据方程(1)和方程(4),我们将原始的多段线注释转换为参数化的贝塞尔曲线。注意,我们直接使用第一个和最后一个注释点分别作为第一个(b0)和最后一个(b4)控制点。可视化比较如图5所示,其结果表明,生成的结果在视觉上甚至比原始地面真实性更好。此外,基于结构化的Bezier曲线边界框,我们可以很容易地使用第2.2节中描述的Bezier对齐将曲线文本扭曲成水平格式,而不会产生明显的变形。贝塞尔曲线生成结果的更多示例如图6所示。我们方法的简单性允许它在实践中推广到不同类型的文本。



2.1.2 Bezier Curve Synthetic Dataset
对于端到端的场景文本识别方法,总是需要大量的自由合成数据,如表2所示。然而,现有的800k SynText数据集[7]只为大多数直文本提供四边形边界框。为了丰富和丰富任意形状的场景文本,我们尝试用VGG合成方法合成了150k个合成数据集(94723个图像包含大部分直线文本,54327个图像包含大部分曲线文本)。特别地,我们从COCO文本[39]中过滤出40k个无文本背景图像,然后用[32]和[17]准备每个背景图像的分割遮罩和场景深度,用于以下文本渲染。为了扩大合成文本的形状多样性,我们对VGG合成方法进行了改进,将场景文本与各种艺术字体和语料库合成,并对所有文本实例生成多边形标注。然后使用注释通过第2.1.1节中描述的生成方法生成贝塞尔曲线地面真值。综合数据的示例如图8所示。
2.2. Bezier Align
形式化地给出输入特征映射和Bezier曲线控制点,同时处理hout×wout大小的矩形输出特征映射的所有输出像素。以具有位置(giw,gih)的像素gi(来自输出的特征图)为例,通过公式(5)计算t:

然后用t和方程(1)计算上Bezier曲线的边界点tp和下Bezier曲线的边界点bp。利用tp和bp,我们可以通过方程(6)对采样点op进行线性索引:
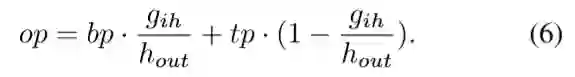
利用op的位置,我们可以很容易地应用双线性插值来计算结果。以前的采样方法和Bezier Align之间的比较如图7所示。
3. Experiments
我们对最近引入的两个任意形状的场景文本基准Total text[3]和CTW1500[26]进行了评估,这两个基准还包含大量的纯文本。我们还对全文进行了消融研究,以验证我们提出的方法的有效性。
消融研究:Bezierralign。
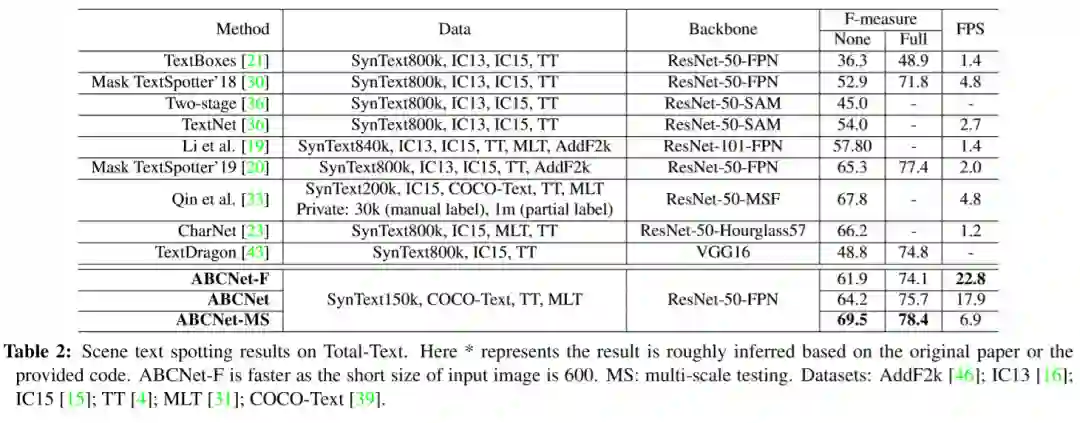
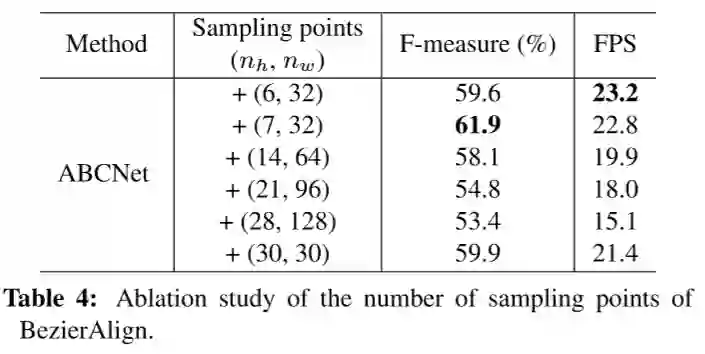
为了评价所提出的成分的有效性,我们对这个数据集进行了消融研究。我们首先对取样点的数量如何影响端到端结果进行敏感性分析,如表4所示。从结果中我们可以看出,采样点的数量可以显著影响最终的性能和效率。我们发现(7,32)在F-measure和FPS之间实现了最佳的权衡,这在下面的实验中用作最终设置。通过与图7所示的先前采样方法进行比较,我们进一步评估了Bezierralign。表3所示的结果表明,bezierallign可以显著改善端到端的结果。定性示例如图9所示。



消融研究:贝塞尔曲线检测。
另一个重要的组件是Bezier曲线检测,它支持任意形状的场景文本检测。因此,我们也进行了实验来评估贝塞尔曲线检测的时间消耗。表5的结果表明,与标准包围盒检测相比,贝塞尔曲线检测不会引入额外的计算。
与最新技术的比较。我们进一步比较了我们的方法和以前的方法。从表2可以看出,我们的单尺度结果(短尺度为800)可以在达到实时推理速度的同时达到竞争性的性能,从而在速度和单词准确性之间取得更好的权衡。通过多尺度推理,ABCNet达到了最先进的性能,显著优于所有以前的方法,特别是在运行时间方面。值得一提的是,我们的快速版本可以比以前的最佳方法[20]快11倍以上,精度相当。
定性结果。ABCNet的一些定性结果如图10所示。结果表明,该方法能够准确地检测和识别大部分任意形状的文本。此外,我们的方法还可以很好地处理直文本,具有近似四边形的紧凑包围盒和正确的识别结果。图中还显示了一些错误,这些错误主要是由于错误识别其中一个字符造成的。
由于该数据集中的中文文本所占的比例很小,在训练过程中我们直接将所有的中文文本视为“看不见的”类,即96级。注意,最后一个类,即第97个类在我们的实现中是“EOF”。我们遵循与[43]相同的评估标准。实验结果如表6所示,这表明在端到端的场景文本识别方面,ABCNet可以显著地超过现有的技术方法。这个数据集的示例结果如图11所示。从图中,我们可以看到一些长文本行实例包含许多单词,这使得完全匹配单词的准确性极为困难。
4. Conclusion
我们提出了一种基于Bezier曲线的实时端到端的场景文本识别方法ABCNet。ABCNet利用参数化的Bezier曲线重新构造任意形状的场景文本,可以用Bezier曲线检测任意形状的场景文本,与标准的包围盒检测相比,计算量可以忽略不计。有了这样规则的Bezier曲线包围盒,我们自然可以通过一个新的bezierralign层连接一个轻量级的识别分支。此外,通过使用我们的Bezier曲线合成数据集和公开可用的数据,在两个任意形状的场景文本基准(Total text和CTW1500)上的实验表明,我们的ABCNet可以达到最先进的性能,这也比以前的方法快得多。
重磅!CVer-场景文本检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-场景文本检测 微信交流群,目前已汇集400人!涵盖OCR、场景文本检测与识别等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、TensorFlow和PyTorch等群。
一定要备注:研究方向+地点+学校/公司+昵称(如场景文本检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!

