震惊!三个万引大佬嘴仗,原来是为了他……?

文|白鹡鸰想把小轶挂到三作
编|小轶已把白鹡鸰挂到三作
这本应是白鹡鸰在小轶追杀下游刃有余拖稿的一天,结果小轶再次把一篇新论文喂到了我的嘴边。象征性地打开论文,草草扫过去,嗯,迁移学习,嗯,新SOTA,嗯,计算需要的储存资源是fine-tuning的1%。哇哦,厉害,厉害,但这不影响我不想写呀?下拉,看看附件部分图表漂不漂亮,然而,首先看到的却是:

作者贡献:
……
Mike (四作):参与每周例会;由于对文献不够熟悉,把事态搞得更为复杂;坚持认为本文的核心想法不可能行得通;为研究的框架作出贡献;在写作方面提供了相当的帮助。
鉴于这是 Google Brain 的文章,四个作者全是实习生乱编故事的概率不大。白鹡鸰随手一搜,哇,不得了啊,这 Vincent,Hugo,Mike 都是万引大佬,就连“萌新”一作,也是2017年至今快700被引了的“大佬宝宝”啊!所以,这篇文章到底在干什么,居然会让大佬们发生争论,最终导致 Mike 受到如此待遇呢?

论文题目:
Head2Toe: Utilizing Intermediate Representations for Better Transfer Learning
论文链接:
https://arxiv.org/abs/2201.03529
代码链接:
https://github.com/google-research/head2toe
大胆推测
在迁移学习里,有着两种常见的做法:linear probe和fine-tune。linear probe不对训练好的模型做变动,只是用它从下游数据集提取特征,然后利用逻辑回归拟合标签;相对的,fine-tune则是利用下游数据再次微调预模型中的所有参数。在目前大多数的实践中,哪怕下游数据集体量很小,fine-tuning的迁移效果都会比linear probing要好。但是由于fine-tuning在处理每个下游任务时,都需要重新运算,然后存储一组新的参数,成本极高,缺乏实用性。换言之,迁移学习现在面临着性能和成本难以兼得的问题。
而这篇论文的灵感,正是来自作者对fine-tune和linear probe的观察。为什么即使下游数据集很小,fine-tune的迁移效果还能这么好?这个过程中,模型到底学到了什么?它真的在学吗?或者……有没有这样的可能:预训练的时候模型已经学会了下游数据集需要的特征,fine-tune过程中,有很多操作其实是多余的?

为了进一步地挖掘fine-tune和linear probe之间原理的差异性,作者们做了这样一个实验:首先,针对一系列的下游数据集,分别从零开始训练一个新模型(learning from scratch, 简称SCRATCH);然后,利用linear probe和fine-tune将在ImageNet-2012上预训练的模型迁移到各个数据集上;图1展示的是三种方式获得的模型的精度对比情况。在这里,因为linear probe没有改变预训练模型提取特征的方式,只是针对下游数据集调整了不同特征分布对应的分类,linear probe和SCRATCH的精度差异可以用来衡量预训练用的数据集和下游数据集中特征的分布差异情况,即

图1中,从左到右展示了域偏移程度从最大到最小的情况。当下游数据的域分布基本被预训练数据的域分布包含时(最右),linear probe和fine-tune都可以取得不错的效果。但当域偏移程度严重时(最左),linear probe的效果会出现显著下降,相比之下,fine-tune却依然稳坐钓鱼台,甚至在一些数据集上的精度超越了SCRATCH。这样的情况引出了更为具体的猜测:fine-tune在out-of-distribution情况下,表现突出的关键既不是调整特征分布与其对应分类的参数,也不是在学习新的特征,而重点是调整已存在的中间特征。
接着,作者用公式进一步描述了这个猜测:将 记作输入, 记作权重,网络的输出则是 ,那么我们经典的神经元输入和输出可以写作 和 ,接着,对于fine-tune的神经网络,由于只是权重发生变化,我们可以记作 ,做一个泰勒一级展开:
基于链式规则,这个式子可以进一步写成
此处 通过linear probe的同款操作就可以获得。
以上推导意味着,可能在fine-tune当中效果最大的部分是中间特征的线性组合。而这个猜测是有一定依据的,近两年的研究中[1,2],有观察到在fine-tune过程中,预训练模型的参数变化确实不大,而fine-tune模型的线性逼近版本,也能在迁移学习中取得不错的效果。
但是,如果这就是真相,岂不是显得大家这么多年来执行整个fine-tuning流程的操作很憨吗?如果这就是兼得性能和成本的方法,真的这么久没有人发现吗?白鹡鸰揣测,Mike可能就是在这个时候提出了质疑,以从业多年专家的角度,觉得这个理论不会成功。他的质疑也不是毫无道理,毕竟公式展示的只是理论近似,数据上能不能实现完全两说。总之,打再多的嘴仗也没有用,实践才是检验真理的唯一标准,那么接下来压力给到实验环节~
小心求证
实验的第一步,相信大家都能想到:把fine-tune的中间特征想个办法抠出来,套到一个naive的方法上,然后对比一波现有方法。行的话就发paper,不行的话就当无事发生过,或者是在未来其他工作中轻描淡写提上一段🌚。
具体来说,论文中将预训练的ResNet-50主干网络中倒数第二层的特征和额外的一层中间特征拼接在一起,再用linear probe的方法在下游数据集上进行训练。为了能够找到这种方法的表现上限,这额外的一层选用的是能让模型精度提升最显著的一层(不愧是有资源的google,这得试多少个模型啊),最终,在不同的下游任务上,平均下来精度提升为3.5%。
为了证明这个提升是因为加入了中间特征,而不是拼接不同层,靠矩阵变大带来的效果,作者们加入了控制组,把倒数第二层的特征和另一个预训练的ResNet-50的中间层特征拼在一起,在维数和前者一致的情况下,对模型精度的提升并不如前者。由此证明了,模型的中间特征确实能提升模型迁移学习的效果。严谨一点说,当下游数据集和预训练数据间域偏移越大,中间特征在迁移学习中起的作用也就越大。这是基于截止现在观察到的现象和推理过程能够得到的结论。
Head2Toe
验证了这个想法之后,大佬们并没有停下脚步,而是一鼓作气,基于这个观点设计了新的迁移算法Head2Toe。一般的神经元,输入输出是
到了Head2Toe当中,就变得暴力起来:
当然,直接这么做了,运算成本显然会变得非常离谱,所以不能一股脑地加权所有中间层,而是要对中间特征筛选一下。因此,论文中采用了group-lasso regularization对特征的重要性进行排序和过滤,过滤的比例 由下游任务的训练效果决定。
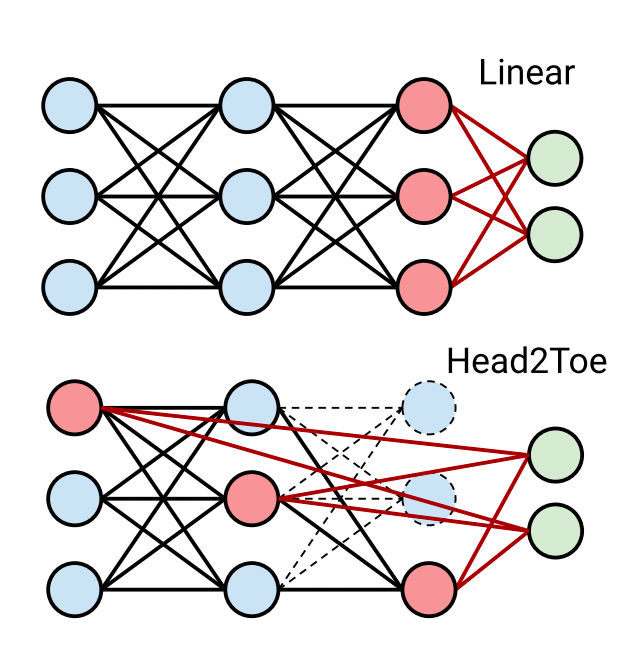
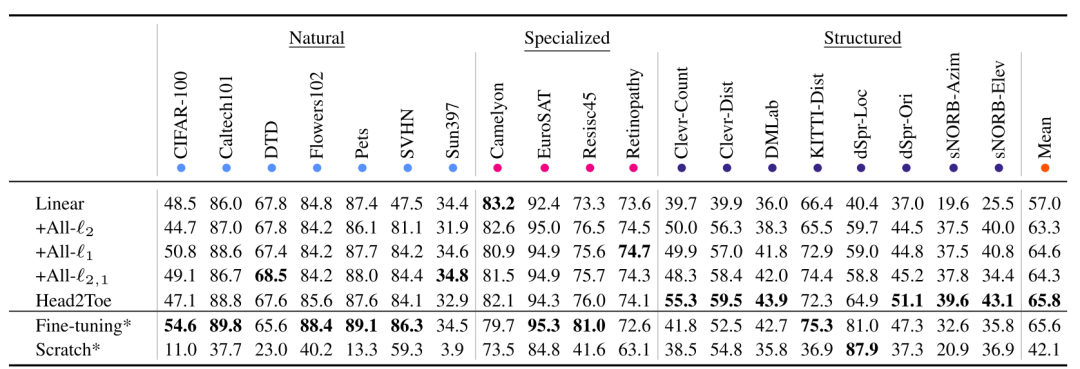
由于Head2Toe只是对特征进行筛选,特征本身不会发生变化。与fine-tune相比,在每次迭代过程中,不会对特征进行频繁的改写。在计算成本上,Head2Toe和linear probe是一个数量级的,比fine-tune小了很多。==在这种情况下,Head2Toe的效果却能和fine-tune不相上下,甚至常有超越==。图三展示了linear probe加上不同的中间特征配置、Head2Toe、fine-tuning三类迁移学习方法,以及从头训练(SCRATCH)的模型的精度对比。行标题中Natural,Specialized,Structured是指图片数据的分布情况:真实图像,针对特定品种的真实图像,经过处理的人工合成图像。列标题中,+All- 版本的Head2Toe,虽然也通过group lasso排序了所有中间特征,但没有执行筛选操作,而是照单全用, 是指group lasso中选择的范数版本。可以看出,Head2Toe的总体表现不错。
总结
通过一系列的推导、实验,论文成功证明中间特征在迁移学习的过程中起了关键性的作用,并提出了新的迁移学习方法Head2Toe,在下游任务数据分布与预训练集相差大的情境中,精度能与fine-tune不相上下甚至有所超越,成本上仅需fine-tune模型0.6%的FLOPs和1%的存储空间。除此之外,论文还对fine-tune情况下的Head2Toe性能进行了分析,调查了不同下游数据集选择特征的偏好情况,以及等等。限于篇幅此处不多加展开,感兴趣的朋友可以自行翻阅正文、附件和代码。
碎碎念
最后又到了惯例的夸奖论文结构的环节。每次看Google的论文,我都会忍不住写上一段来夸他们的论文结构,这一次特别想强调善用论文的Appendix章节。最近白鹡鸰在审稿的时候,发现有些论文的中心放在实验部分,公式十几二十个,图表很多很多,把结果和讨论抠出来,还摆不满一页。结果读者不一定能完全跟上作者的思路,阅读不断被图表打断,理解过程简直是跨越崇山峻岭。这种行为本质上是作者偷懒:“数据摆出来了,你自己分析原理、总结结论吧”。论文中最重要的内容应当是:问题声明、问题意义、贡献声明、方法(简要)说明、创新点阐述、原理分析,公式和图表都只是辅助手段。非原创性的公式、和核心结论没有直接关联的图表,是应当放到Appendix作为辅助材料的。而且现在互联网如此发达,开个网页/传个视频堆demo很香啊。
咳咳,最近被论文折磨多了,忍不住多说几句。接下去就是新年了,祝大家新年快乐,也祝我自己能成功摸鱼,下次拖稿的时候不被小轶干掉。
萌屋作者:白鹡鸰
白鹡鸰(jí líng)是一种候鸟,浪形的飞翔轨迹使白鹡鸰在卖萌屋中时隐时现。已在上海交大栖息四年,进入了名为博士的换毛期。目前蹲在了驾驶决策的窝里一动不动,争取早日孵出几篇能对领域有贡献的论文~
知乎ID也是白鹡鸰,欢迎造访。
作品推荐:
 萌屋作者:白鹡鸰
萌屋作者:白鹡鸰
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Maddox, Wesley, et al. "Fast Adaptation with Linearized Neural Networks." International Conference on Artificial Intelligence and Statistics. PMLR, 2021.
[2] Mu, Fangzhou, Yingyu Liang, and Yin Li. "Gradients as features for deep representation learning." arXiv preprint arXiv:2004.05529 (2020).
 后台回复关键词【
后台回复关键词【




