谷歌「模型汤」靠微调屠了ImageNet的榜!方法竟然只有半页纸

极市导读
ImageNet排行榜又双叒叕被刷新啦!不过这回,新霸主谷歌没有提出新模型,只靠微调「几个」模型就做到了第一,论文通篇都是实验分析,这也引起了网友的争议:全靠财大气粗!>>加入极市CV技术交流群,走在计算机视觉的最前沿
最近,谷歌又靠着强大的计算资源豪横了一把,而且还顺手捎上了一位Meta AI的朋友。
不得不说,这两个「冤家」的合作可不多见。

论文链接:https://arxiv.org/abs/2203.05482
研究团队提出了一种称为「模型汤」的概念,通过在大型预训练模型下使用不同的超参数配置进行微调,然后再把权重取平均。
实验结果证明了,这种简单的方法通常都能够提升模型的准确率和稳健性。

一般来说,想获得一个性能最佳的模型需要两步:
-
使用不同的超参数训练多个模型 -
选择在验证集上效果最好的模型
但这种方法产生的单个模型有一个致命缺陷:运气成分很大,非常容易陷入局部最优点,导致性能并非全局最优。
所以另一个常用策略是模型集成(ensemble),但集成后的模型还是本质上还是多个模型,所以同一个输入需要推理多次,推理成本更高。
而模型汤通过对模型权重进行平均,最后得到的是一个模型,则可以在不产生任何额外推理或内存成本的情况下提升性能。
当然了,你可能在想,模型方法这么简单,怎么Google就敢把论文发出来?

Method部分只占了半页,文章的通篇基本全是实验,也就是说Google做了一件别人都没做到的事:用大量的计算资源,做大量的实验,来证明这个简单的方法就是有效的。
并且模型还刷新了ImageNet 1K的新纪录:90.94%。

所以对高校的研究人员来说,这篇文章可能没有太大的学术价值,完全就是实验科学。但对于有钱、有资源的大公司来说,性能强就够了!
模型汤(Model Soup)名字的灵感来源可能来自「斐波那契例汤」,具体做法是把昨天的和前天剩下的汤加热后混合,得到就是今天新鲜的「斐波那契例汤」。
模型汤把昨天的多个模型加热一下,就成了今天新鲜的SOTA模型了。
新瓶装旧酒
CV模型的常见开发模式就是:有计算资源的大公司把模型预训练好,其他研究人员在这基础上,针对自己特定的下游任务进行微调。
在单个模型的情况下,性能可能并非最优,所以另一个常用的提升性能方法就是集成(ensemble):使用不同的超参数,训练多个模型,然后将这些模型的输出结果组合起来,比如用投票的方式,选出多个模型预测一致的结果作为最终输出。
集成模型虽说可以提升模型的性能,但缺点也显而易见:同一个输入需要预测多次,推理性能显著下降,必须得增大显存、增加显卡或者等待更长的推理时间。
Google提出将多个微调后的模型进行权重平均化,而非选择在验证集上达到最高精度的单个模型,最终产生的新模型就称为模型汤。
因为正常训练的时候也需要训练多个模型,所以模型汤并没有增加训练成本。并且模型汤也是单模型,所以也没有增加推理成本。
其实之前就有研究结果表明,沿着单一训练轨迹(single training trajectory)的权重平均化能够提高随机初始化训练模型的性能。
模型汤则是将权重平均化的有效性扩展到了微调的背景下。
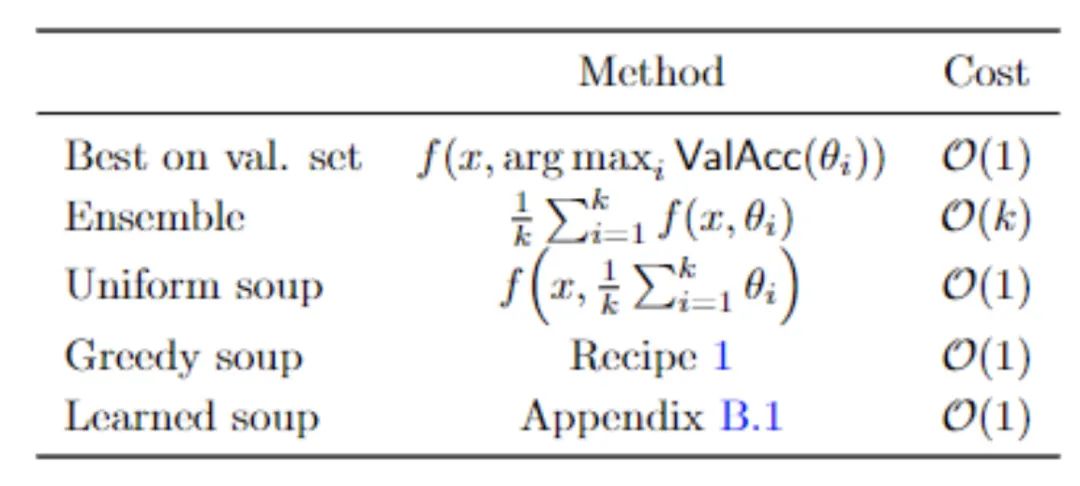
权重平均化的策略也有很多,论文中给了3种常用的方法 :均匀汤、贪婪汤、学习汤。
均匀汤(Uniform soup)最简单,不同模型权重直接求平均即可。
贪婪汤则是通过依次添加模型作为汤中的潜在成分(potential ingredient)来构建的,只有当模型在预留的验证集上的性能提高时,才将其留在模型汤中。
在运行算法之前,先按照验证集准确性的递减顺序对模型进行排序,所以贪婪汤模型不会比验证集上最好的单个模型差。

学习汤则是通过将各个模型在模型汤中的权重作为可学习的参数。
性能强就是王道
虽说模型汤的想法很简单,但这篇论文的重点并非是方法,而是实验。

在实验部分,研究人员探索了在对各种模型进行微调时对模型汤的应用。微调的主要模型是CLIP和ALIGN模型,用图像-文本对的对比监督进行预训练,在JFT-3B上预训练的ViT-G/14模型,以及文本分类的Transformer模型。实验主要使用的是CLIP ViT-B/32模型。
微调是端到端的,也就是所有的参数都可修改,这种方式往往比只训练最后的线性层有更高的准确性。
在微调之前,实验采用两种不同的方法来初始化最后的线性层。第一种方法是从线性探针(linear probe, LP)初始化模型。第二种方法使用zero-shot初始化,例如,使用CLIP或ALIGN的文本塔产生的分类器作为初始化。
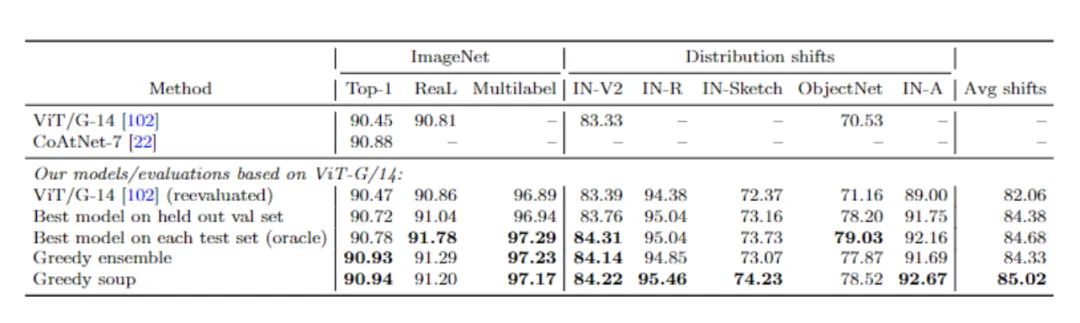
微调使用的数据集为ImageNet。实验中还对五个自然分布shift进行评估:ImageNetV2,ImageNet-R, ImageNet-Sketch, ObjectNet, 和ImageNet-A。
由于官方的ImageNet验证集被用作测试集,因此实验中使用大约2%的ImageNet训练集作为构建贪婪的汤的保留验证集。
实验结果对比了汤的策略,可以看到贪婪汤需要更少的模型就能达到与在保留的验证集上选择最佳个体模型相同的精度。X轴为超参数随机搜索中所考虑的模型数量,Y轴为各种模型选择方法的准确率。所有的方法在推理过程中都需要相同数量的训练和计算成本。
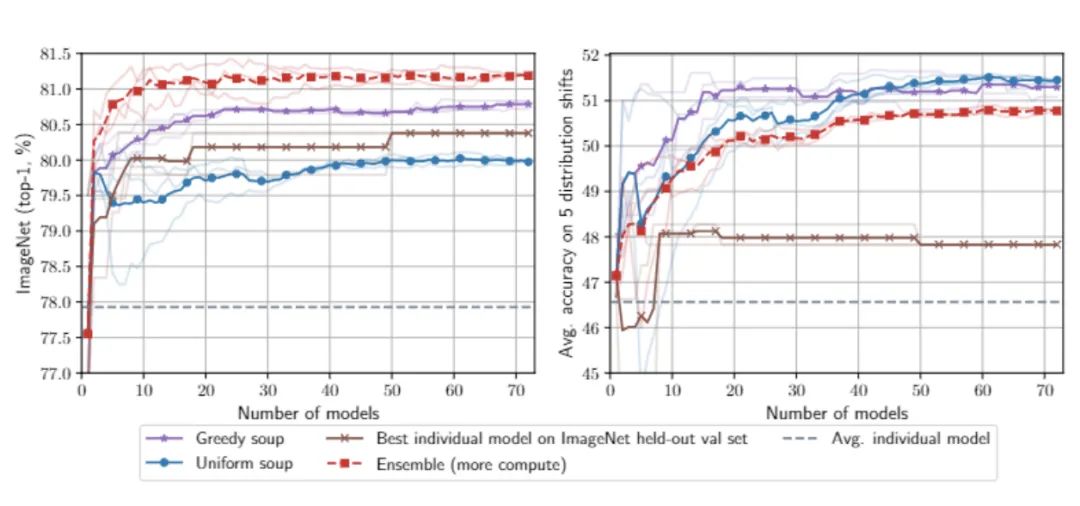
对于任何数量的模型,贪婪汤在ImageNet和分布外测试集上都优于最佳单一模型;贪婪汤在ImageNet上优于均匀汤,在分布外则与之相当。Logit集成在ImageNet上比贪婪汤好,但在分布外更差。
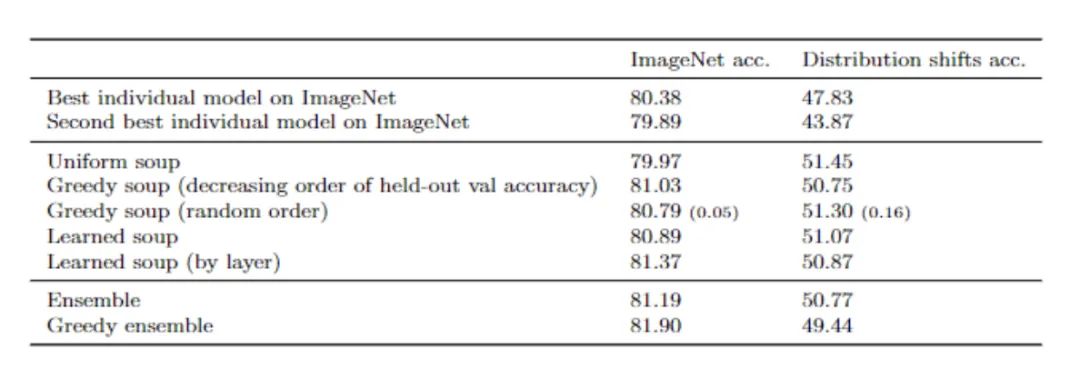
贪婪汤比ViT-G/14在JFT-3B上预训练并在ImageNet上微调后得到的最好的单个模型在分布内和分布外的情况下的性能都有所提升。
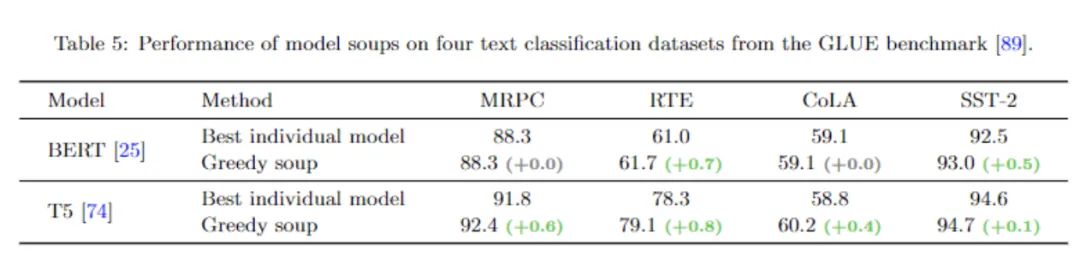
为了测试通过模型汤获得的模型性能提升是否可以扩展到图像分类以外的领域,研究人员还对NLP任务进行了实验。研究人员在四个文本分类任务上对BERT和T5模型进行了微调,这些任务来自于GLUE基准:MRPC,RTE,CoLA和SST-2。实验结果虽然改进没有图像分类中那么明显,但贪婪汤在许多情况下可以比最好的单模型性能更好。
有意义吗?
大部分从事AI模型的研究人员看完论文的内心应该都是:就这?

论文一出,在知乎上也有论文的相关讨论。

有网友表示,这种论文没有意义,全靠资源堆砌,验证了一个小idea罢了。之前的模型也有相似的idea,并且论文也缺乏对神经网络的理论分析。
不过凡事都有两面性,网友@昭昭不糟糟 则表示,sota只是论文的性能体现,文章大量的实验产生的结论还是比较具有启发性的,简单有效即是好idea!
网友@战斗系牧师 称这是个极具谷歌风格的工作,思路不难想到,但Google胜在推理速度不变、且对问题的解释也很到位,实验充足(对于穷研究人员来说可能没办法复现)。确实有很多值得学习的地方。并且模型汤也更加环保,没有把训练后的模型直接扔掉,而是利用起来,不至于浪费电。
网友@西红柿牛腩分析称:「现在ImageNet刷榜的模型,10亿参数不嫌少,100亿参数不嫌多。而且Google、Facebook这些有钱的主,动不动就是1000块显卡起步,不但用Conv+Transformer,还用JFT-3B作弊。然而,要是用1000层的ResNet达到了91%的Top 1,那就是时代的进步了。」
最后还调侃说:「假如让我刷到92% Top 1,半夜都会笑醒,一年的KPI都达到了。」

参考资料:
https://arxiv.org/abs/2203.05482
https://www.zhihu.com/question/521497951

公众号后台回复“数据集”获取小目标检测数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



