赛尔原创@IJCAI 2021 | 会议摘要有难度?快来引入对话篇章结构信息
论文名称:Dialogue Discourse-Aware Graph Model and Data Augmentation for Meeting 论文作者:冯夏冲、冯骁骋、秦兵、耿昕伟 原创作者:冯夏冲 论文链接:https://arxiv.org/abs/2012.03502 (arXiv preprint) 代码链接:https://github.com/xcfcode/DDAMS 转载须标注出处:哈工大SCIR
摘要
会议参与者的动态交互性和大规模训练数据的缺乏使得会议摘要成为一项具有挑战性的任务。现有的工作一方面将会议视为顺序句子序列进行建模,忽略了句子之间丰富的交互结构;另一方面,训练数据的缺乏限制了摘要模型的性能。在本文中,我们提出引入对话篇章结构来缓解上述问题。首先,我们提出DDAMS会议摘要模型来显式地建模句子之间的交互关系,其核心模块图编码器可以有效地以图交互的方式建模会议句子和多种篇章结构关系。除此以外,我们还设计了一种可以从现有会议摘要数据集中构建伪摘要数据集的DDADA数据增强策略。通过DDADA构建的伪摘要数据集是原数据集大小的20倍,可以有效地用于预训练DDAMS会议摘要模型。实验结果显示我们的方法可以在AMI和ICSI两个会议摘要数据集上取得SOTA效果。
1. 简介
1.1 研究背景
会议摘要(Meeting Summarization)旨在从一段多人会议中提取关键信息,形成一段文字概述。由于新冠肺炎疫情的影响,人与人之间的交流频繁地采用在线会议形式,会议摘要可以有效地的帮助用户快速回顾会议内容,整理诸如任务、决策、问题等核心内容,是一项极具实用价值的任务,得到了Microsoft等公司的关注[1][2]。
1.2 研究动机
现有会议摘要工作存在以下两个问题:
1. 会议文本建模不充分。 由于会议参与者的动态交互性,会议句子之间天然地存在着丰富的交互结构,然而现有工作仅仅将会议句子视为顺序句子序列,忽略了这种丰富的交互结构,使得会议文本建模不够充分。
2. 大规模训练数据集缺乏。 基于神经网络的方法很大程度上依赖于训练数据的规模,然而,现有会议摘要数据集AMI和ICSI规模只有CNNDM数据集的千分之一,极大地限制了摘要模型的性能。
为了缓解上述两个问题,我们提出引入一种对话特定的结构信息:对话篇章结构,该结构指示了两个句子之间的语义关系,如图1所示
现有对话篇章结构一共包含16种关系类型:comment, clarification-question, elaboration, acknowledgment, continuation, explanation, conditional, QA, alternation, question-elaboration, result, background, narration, correction, parallel, contrast。

图1 对话篇章结构
对话篇章结构显式地指示了句子之间的交互关系和会议的信息流。引入该结构可以帮助模型更好地理解会议内容,从而生成更好的会议摘要,如图2所示。为了更好地建模会议文本与对话篇章结构信息,我们提出了会议摘要模型DDAMS。

图2 会议-摘要对示例
进一步,我们发现,在一段会议中,一个“问题”往往会引发一段“讨论”,这段“讨论”往往围绕“问题”展开。如图2所示,问题句包含了关键词语“battery charger”,讨论中的“design”和“cost”均围绕该词语展开。因此我们认为“问题”包含了关键的词语和信息,可以被视为“讨论”的“伪摘要”。基于该假设,我们设计了一种数据增强策略DDADA,从原始数据集中构建伪摘要数据集用于预训练会议摘要模型DDAMS。
1.3 任务定义
给定会议 ,会议摘要旨在生成摘要 ,其中会议 包括了 个句子 ,摘要 包括了 个词语 。第 个句子为 , 代表第 个句子的第 个词语。每一个句子 都对应一个说话人 , 是说话人集合。
2. Dialogue Discourse-Aware Meeting Summarizer (DDAMS)
2.1 整体框架
我们的摘要模型DDAMS包括了四个部分:(1)会议图构建;(2)节点表示;(3)图编码器;(4)解码器。整体如图3所示。
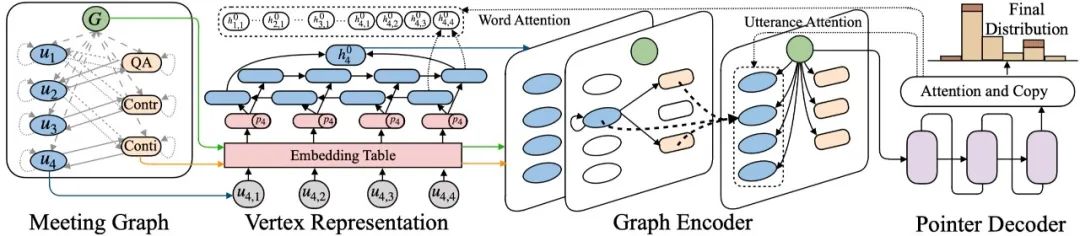
图3 摘要模型DDAMS
2.2 会议图构建
会议图(Meeting Graph)构建包括以下几个步骤:
-
使用对话篇章结构解析器获得对话篇章结构关系; -
Levi图转换,将边关系转换为节点,并添加正向与反向边; -
添加全局节点、全局边和自连接边; -
添加反向边(Reverse Edges)。
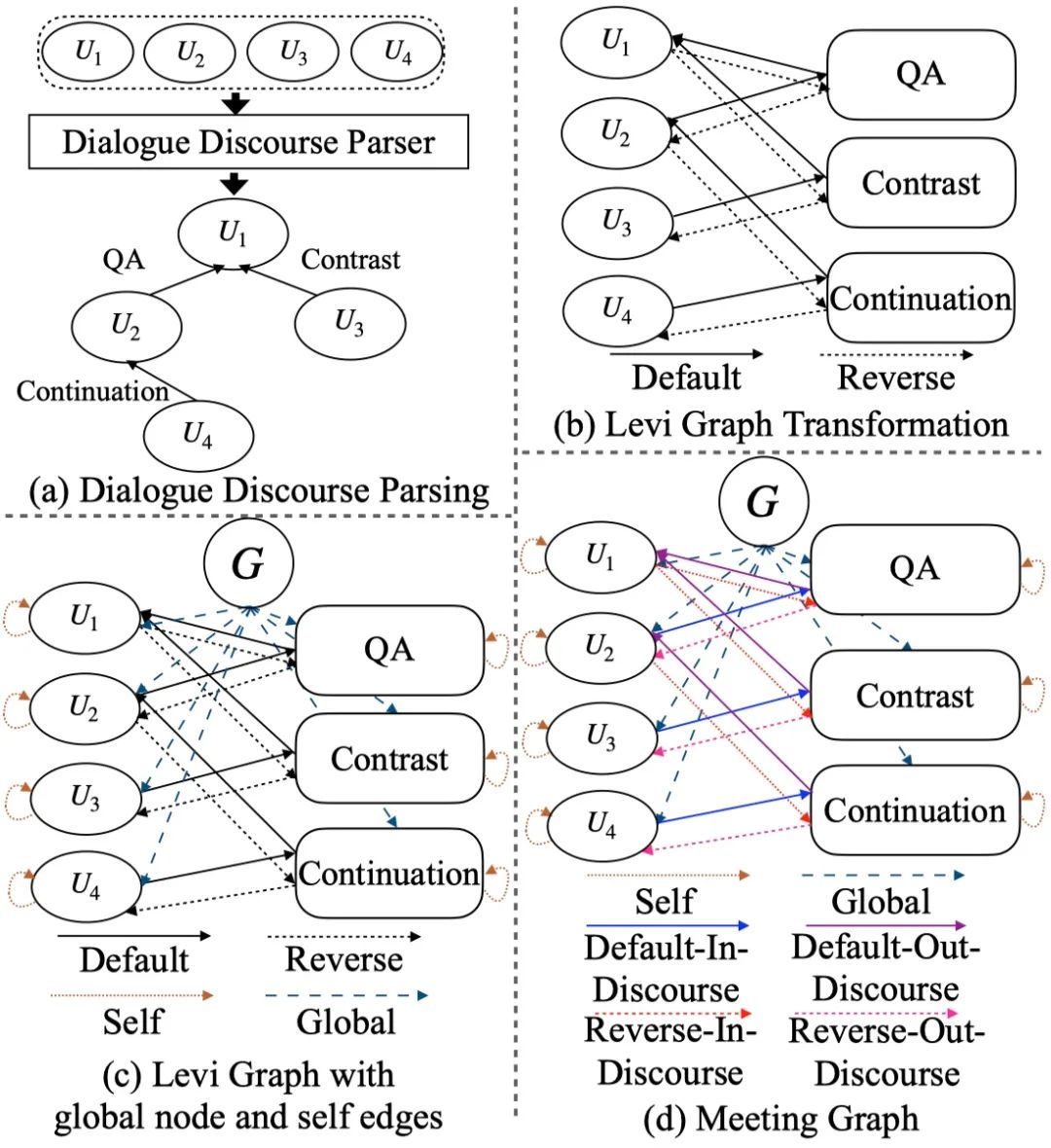
图4 会议图构建流程
2.3 节点表示
-
关系节点:从一个可学习的关系编码矩阵中初始化。 -
全局节点:初始化为0向量。 -
句子节点:利用双向LSTM进行初始化。
2.4 图编码器
在得到每一个节点的初始表示 之后,我们使用Relational Graph Convolutional Networks [3] 更新节点表示,该网络可以充分考虑不同类型的边,从而学习到更加有效的表示:

由于不同的对话篇章结构关系有着不同程度的重要性,因此我们引入门控机制 [4] 来控制信息:
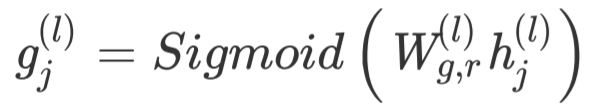
最终得到引入门控机制的图网络更新方式为:

2.5 解码器
解码器我们采用引入copy机制的解码器,并同时考虑词语级别注意力机制和句子级别的注意力机制。
3. Dialogue Discourse-Aware Data Augmentation (DDADA)
3.1 伪摘要数据集构建

图5 伪摘要数据集构造示例
给定一段会议文本及其对话篇章结构,我们发现一个“问题”往往引发一段针对这个问题的“讨论”。如图5所示,A提问“What’s the standard colour?”,其他人开始围绕颜色这个主题进行讨论。我们认为“问题”一定程度可以包含关键的信息和短语,因此本文将“问题”视为伪造的摘要,“讨论”视为伪造的会议,从原始训练数据集中构建伪摘要数据集,数据统计如表1所示。
表1 伪摘要数据集统计

3.2 预训练会议摘要模型
在得到伪摘要数据集之后,我们使用该数据集预训练我们的会议摘要模型DDAMS。一方面,通过我们的数据增强方法DDADA,我们可以隐式地增广数据;另一方面,我们从原始训练集中进行增广,可以保证增广数据和训练数据领域一致,因此可以给模型提供一个热启动参数。
4. 实验
4.1 数据集
-
AMI:产品设计领域会议摘要数据集,数据集划分Train/Valid/Test: 97/20/20 -
ICSI:学术讨论领域会议摘要数据集,数据集划分Train/Valid/Test: 53/25/6
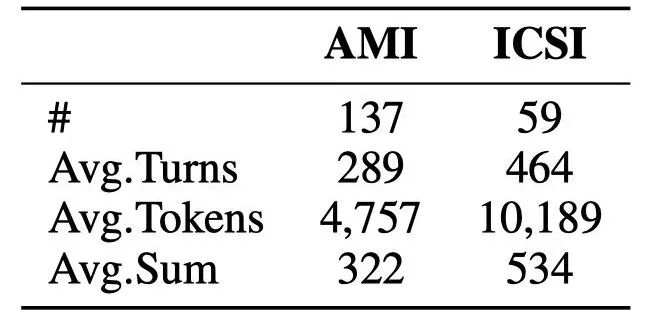
数据集统计如表2。
表2 AMI和ICSI数据集统计
4.2 主实验
表3 主实验结果

表3为主实验结果:
-
引入对话篇章结构,我们的模型DDAMS可以有效地超过诸多基线模型。 -
结合数据增强方法DDADA,我们的模型可以取得世界最优的效果。 -
直接使用伪摘要数据预训练好的模型在测试集上进行测试,也可以取得一定的效果,说明了我们伪摘要数据集构建的合理性。
4.3 分析实验

图6 在测试阶段,引入对话篇章结构关系的数量与平均ROUGE值的对应关系
在测试阶段,我们按照一定的比例随机提供对话篇章结构关系。如图6所示,引入的对话篇章结构信息越多,模型的ROUGE得分越高,显示了引入对话篇章结构的有效性。
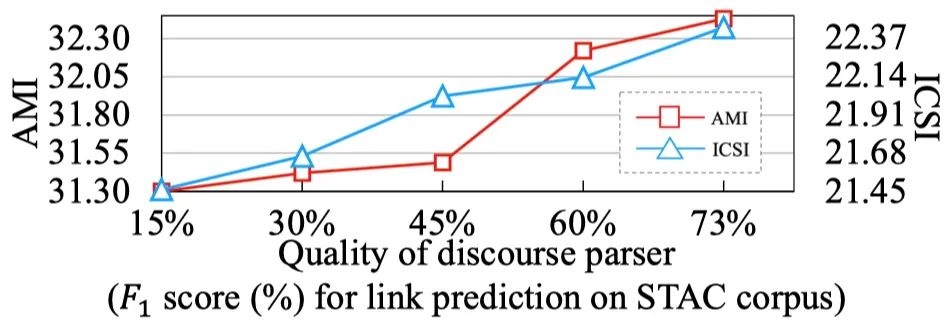
图7 在测试阶段,对话篇章结构关系的质量与平均ROUGE值的对应关系
在测试阶段,我们引入不同质量的对话篇章解析器得到的对话篇章结构信息。如图7所示,对话篇章解析器的质量越好,对话篇章结构关系质量越高,模型的的ROUGE得分越高。
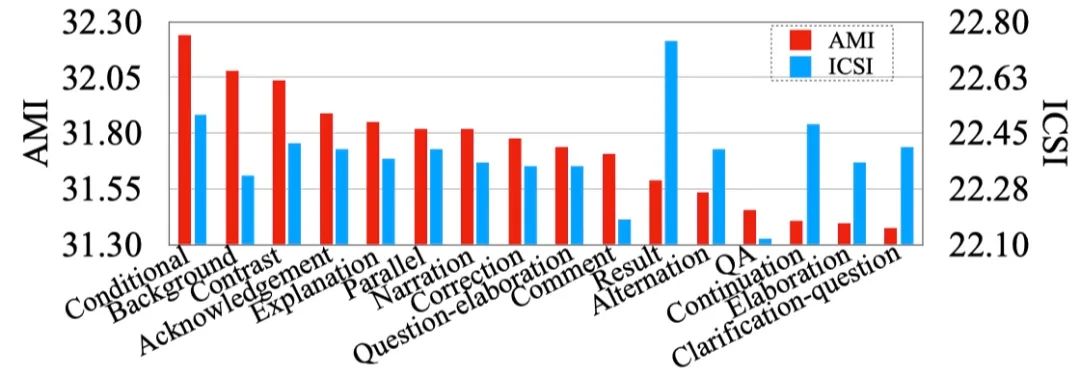
图8 在测试阶段,提供不同类型的对话篇章结构关系与平均ROUGE值的对应关系
在测试阶段,我们单独提供一种特定类型的对话篇章结构关系。如图8所示,在AMI数据集上,Conditional 和Background两类关系比较重要。在ICSI数据集上,Result关系比较重要。
表4 基于会议图(Meeting Graph)和Levi图的实验结果
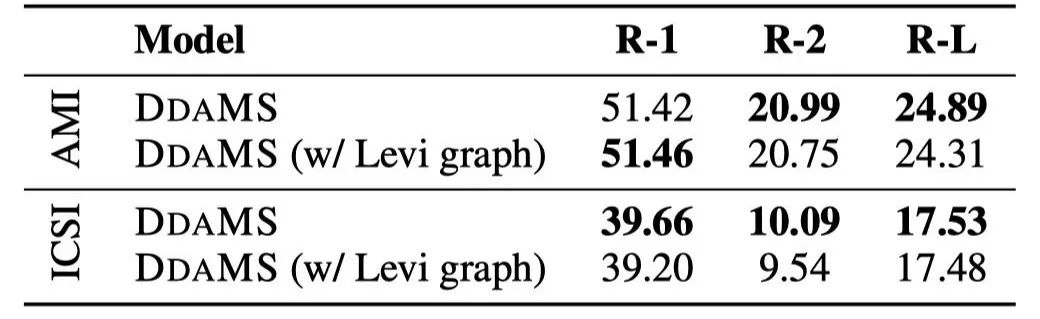
基于我们构建的会议图和Levi图分别进行实验(区别在于Levi图没有反向边),我们发现我们的会议图可以取得更好的效果。
4.4 样例分析

图9 生成样例
图9展示了我们模型生成的会议摘要,可以发现,通过引入对话篇章结构关系,句子1和句子3成为中心句,从而定位了更加关键的内容,最终生成与标准摘要更加相近的摘要。
5. 结论
在这篇文章中,我们的贡献如下:
-
我们首次将对话篇章结构应用于会议摘要任务,并设计了一种会议摘要模型DDAMS有效地建模句子之间的交互关系。 -
我们设计了一种数据增强策略DDADA可以成功缓解训练数据不充足的问题。 -
我们的方法DDAMS+DDADA在两个会议摘要数据集上取得了世界最优的效果。
参考文献
[1] Zhu C, Xu R, Zeng M, et al. A Hierarchical Network for Abstractive Meeting Summarization with Cross-Domain Pretraining. Findings of EMNLP 2020.
[2] Zhong M, Yin D, Yu T, et al. QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization. arXiv preprint arXiv:2104.05938, 2021.
[3] Schlichtkrull M, Kipf T N, Bloem P, et al. Modeling relational data with graph convolutional networks. European semantic web conference 2018.
[4] Marcheggiani D, Titov I. Encoding Sentences with Graph Convolutional Networks for Semantic Role Labeling. EMNLP 2017.
长按下图即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号『哈工大SCIR』。




