向人类幼儿学习小样本学习?
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文转载自知乎专栏:神经科学和人工智能
来源:https://zhuanlan.zhihu.com/p/71780427?utm_source=wechat_session&utm_medium=social&utm_oi=31885698793472
已获作者授权,请勿二次转载
本文对《A Developmental Approach to Machine Learning》这篇文章进行了介绍,并且阐述了作者对于机器学习如何借鉴人类视觉学习的设计与思考。
前言:
很久之前就看到这篇文章了,十分喜欢,断断续续思考了小半年了,一直想写点东西,做点东西,一直以来事情也都比较多,上个周末去参加了一个量子位的线下活动,才最终让我下笔,写了这篇文章,分享一下我在这方面的一些思考,希望大家多多指教。
今天的文章主要是围绕 A Developmental Approach to Machine Learning 这篇文章来写一下我自己对这篇文章的理解和一些想法。文章主要分为两部分,第一部分简单介绍下文章里我认为比较有趣的部分。第二部分就是结合自己之前看过的其他文章,聊一下自己的一些思考和设计。
第一部分:
我们从一个问题开始,目前世界上最好的计算机视觉模型,大约等于几岁的人类?作者给的答案是,一岁到两岁之间。这个期间的儿童在视觉目标识别任务中可能比最好的计算机视觉算法差一些,在一些场景下会没法准确的识别。但在两岁的时候,人类幼儿开始具有了计算机视觉算法尚不具备的一个能力,给两岁的小孩看一个物体的实例,他可以从中推断出整个类别。比如说遇到了一个拖拉机,他会从这个实例认识所有的拖拉机。这个现象在心理学中被称为 object bias, 翻译成形状偏向,换成我们理解的语言,大概就是 one-shot learning。
由此,作者和我都好奇一个问题,两岁的孩子,他们的训练样本是什么样的?
不到两岁的儿童,受限于他们的体积和运动能力,视角会比较受限,如下图1
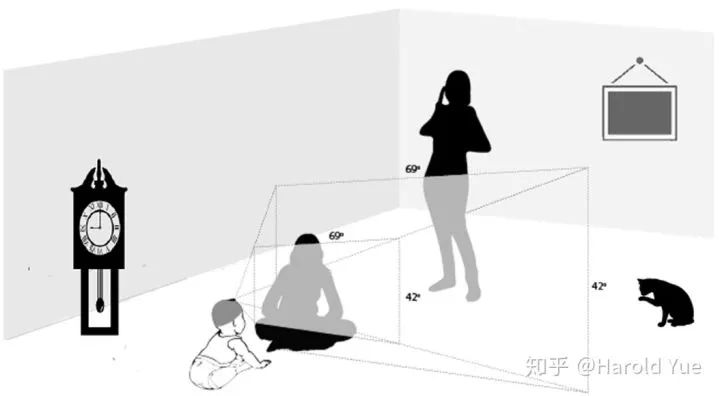
好在我们有一些可以给幼儿使用的头戴式摄像机,定期拍摄一些图片,我们能看到的是人类幼儿在不同成长时间段中看到的东西的差异,如下图2

在婴儿成长初期,会有很多的脸出现,自然,大人不会把婴儿一个人独自放在那。但在之后,画面中心是脸的比例开始下降,画面中心是物体或是带物体的手的画面比例开始上升。
作者在这里提出了一个自己的观点,认为人类幼儿先看脸,再看物体这个顺序,对于形成物体识别能力有比较重要的作用。
如果人类幼儿没有这一段的经历会如何呢?
有一种眼部疾病叫做先天性白内障,它可能会导致人类婴儿在2-6个月时丧失早期视力输入。虽然这些患病婴儿在白内障摘除手术后可以在一些常规的视觉指标,如视锐度,敏感度上和同龄人保持一致。但随着年龄增长,在5-7岁时,对面部的处理能力会表现部分缺失。所以有学者假设,早期的视觉经验保存或者建立了对未来脸部处理能力有帮助的神经基质。作者在此推测,先天性白内障幼儿主要缺失了密集,近距离,全视角的人脸,而这些密集的人脸经验可能对于建立或者维持皮层回路是重要的,同时也为后续出现的专门处理人脸的脑区的出现提供了支持(FFA)。
我想,转化为我们能理解的语言,大概可以理解为,大脑前期做了很多有针对性的无监督训练,专门处理未来可能会大量处理的物体,如人脸。整个网络获得了很好的初始化,后期可以更快,更有针对性的收敛到一些点附近,让人类这个大神经网络具备一些特定物体类别的识别能力。
常规的观点会认为,面部体验只对面部处理很重要,但是作者提出,不止如此,早期密集的人脸接触,不止会帮助日后对人脸的识别,也会帮助其他物体类别的识别。因为所有的视觉输入处理都是由相同的底层和不同的较高表示层来完成的。
相信大家对这块的理解没啥问题。作者的观点是,人类幼儿现在密集人脸上训练的一个网络,之后其他的任务可以重用底层的权重。感觉和迁移学习有异曲同工之妙。
接下来我们问,幼儿可能是怎么做到的呢?
首先是一个统计结果。关于幼儿头戴式摄像机中采集到的图像中物体的分布。如下图3
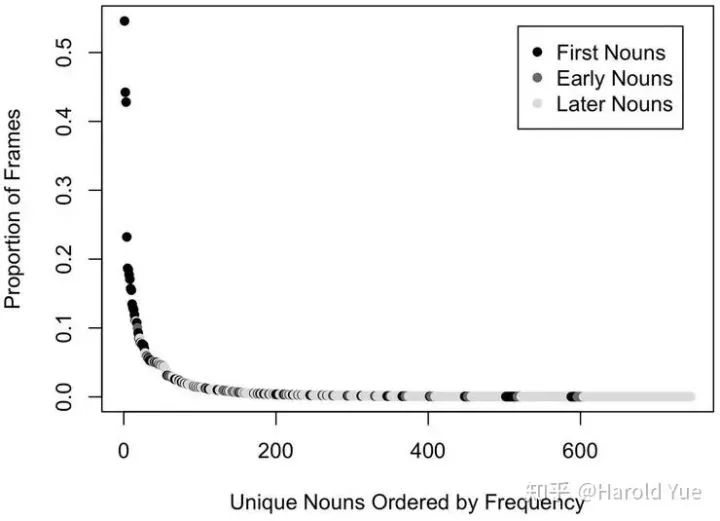
首先是婴儿对人脸的体验,婴儿出生后一年中,看到的人脸主要主要集中在几个人身上,出现最多的三个人的人脸大概占所有人脸的80%。与此相对,在物体的体验也体现出了类似的规律,大致服从一个幂律分布,大部分物体出现的频率很低,少数几种物体出现的频率很高。
作者认为,这样的分布对人类幼儿带来的一个优势是,少数的个体类别,能够让人类幼儿有一个学习的初始目标集,同时可以学习到物体的不变性,如在同一个物体在不同光照下的不变性和在不同角度下的不变性。而这些识别理解不变性的能力,是通用的,可以泛化到其他的物体上。
作者在这提到了一个饲养鸡的实验,佐证了上文提出的观点。
物体的缓慢变化对于雏鸡对于物体形状识别的泛化能力提供了足够的输入。
emm,我也觉得比较难以理解,原文放在下面,欢迎指正。
Research with controlled-reared chicks (Wood, 2013; Wood and Wood, 2016) provides a demonstration proof of this idea: slow-changing transformations of objects provide sufficient input for generalized learning by chicks about object shape.
在这些研究中, 刚出生的雏鸡在严格受控的环境中成长,同时让他们观看运动和旋转的单个物体。实验表明,对于雏鸡来说,对一个单个物体的体验已经足以让雏鸡发展出健壮的物体识别能力并且可以泛化到当前物体没见过的角度以及不同的物体上。
当然,作者也提到了,鸡和人类的大脑还是有很大的差异。但是这个结果仍然很有趣。
具体是如何做的我也不是很清楚,我还没看这篇的原文。
人类幼儿的视觉系统生成的画面有几个特性可能对幼儿能做到小样本学习有帮助。
首先是幼儿创造的视觉场景要更整洁,相比于年龄更小的婴儿甚至成人。因为幼儿胳膊短,身体会前倾去仔细观察物体,这使得他们的视野会被单一物体充满,解决了很多基本的问题,如物体的分隔,物体之间的竞争等。让幼儿和成年人用头戴式摄像机记录同一个事件,用在这过程中拍摄到的图片作为训练集分别训练两个卷积神经网络。实验表明,来自幼儿的训练集训练的卷积神经网络会有更强的识别能力和泛化能力。在物体识别领域,也会用一些标注框来指定要学习的对象。人类的幼儿,用自身的生理条件,直接就获得了这个优势。
第二个是幼儿会生产单一物体的高度可变性的图像。如下图4

大家也能想得到,小孩子遇到一个新物体,会想在手里翻来覆去把玩,而大人就不会有这样的操作。实验表明,孩子玩玩具过程中这个物体的变化程度,可以预测这个孩子6个月后,即21 个月时幼儿掌握的词汇量。换句话说,更好的学习能力来自于更大的差异性。
也有一个计算方面的研究。在孩子和父母一起玩玩具的过程中,使用他们头上戴的头戴式摄像机采集玩耍过程中的图片,并用来训练卷积神经网络。相对于来自父母的图像,来自孩子的图像有更多变化的物体,这导致了更强的泛化能力和学习能力。
作者说,这会改变我们对于one-shot-learning 的认知,幼儿关于一个物体的视觉体验,并不是只是一个单一的视觉体验,而是针对同一个物体一系列不同视角的体验。这会对one-shot-learning 有帮助吗?
第二部分:
前面介绍完了这篇文章主要讲了啥。接下来讲下自己关于这篇文章的一些思考。
我对这篇文章的想法,主要围绕以下几点。
视频流会有帮助,尤其是对于单一物体缓慢变化的视频。人类能无监督或弱监督(知道画面中心的物体一直是同一个)的从里面学到一些不变性,怎么能让能让模型也具备这样的能力。
很少的类别,大量的样本可能会帮助模型构建一个合适的初始化权重或基本网络。这个网络对于后续执行其他任务会很有帮助。
个人的想法,人类的小样本学习可能可以分为两个阶段。第一个阶段是学到足够的底层特征,第二个阶段是看到了新的物体,记录的是组合模式,并在后续的命名阶段把名字和组合模式绑定在一起。
如下图5。定义长方形为0, 三角形为1. 人类在大量的视觉体验中学到了长方形和三角形的表征分别为0和1. 当遇到新的样本,左图时,人类知道这是一个01样本,当后续继续出现这样的样本时,人类知道这是01,和之前的01从属一类。而遇到新样本,右图,知道这是一个10样本,其他同理。
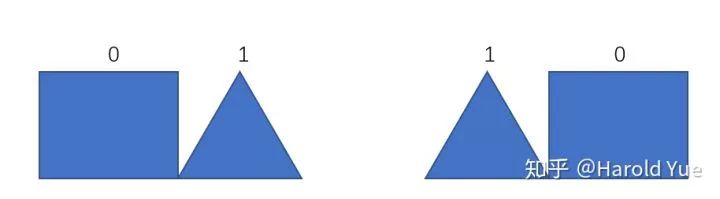
那接下来的问题是,如果要设计实验,如何利用这些知识和假设?
我想到的方案是两个网络的一个组合。
其中一个网络主要学习底层的特征以及不变性,另一个网络做组合来识别物体。我想到的比较合适的结构是PredNet 和 Capsule Net。
接下来我简单来介绍下这个设计
PredNet, 网络结构是这样的。
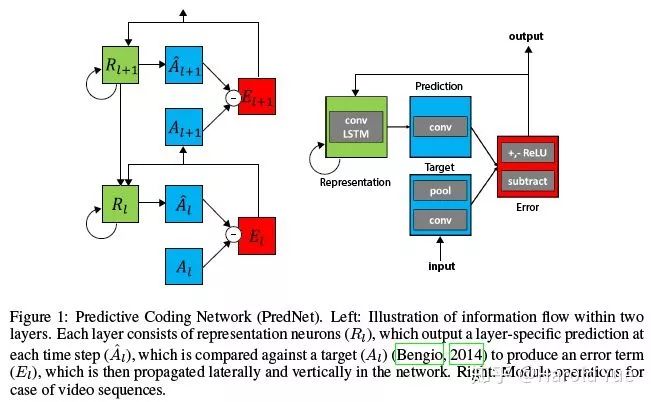
网络不断的从之前的信号中预测下一帧,并将误差反向传播回去,不断修正模型,是一种无监督学习的方式。
其实,人类的大脑也有类似的机制,我们会在脑子里面不断的模拟和预测下一步会发生什么,如果没有发生预期的事情,才会感觉到惊讶并调动主要的逻辑思维系统。这是一个比较高效的系统,面对危机的时候快速反应。也是因为有这样的机制,所以我也会猜测,是不是在小样本学习的训练过程中也会有类似的机制,所以用这个网络来做骨架。
这个网络另外一个优点是,
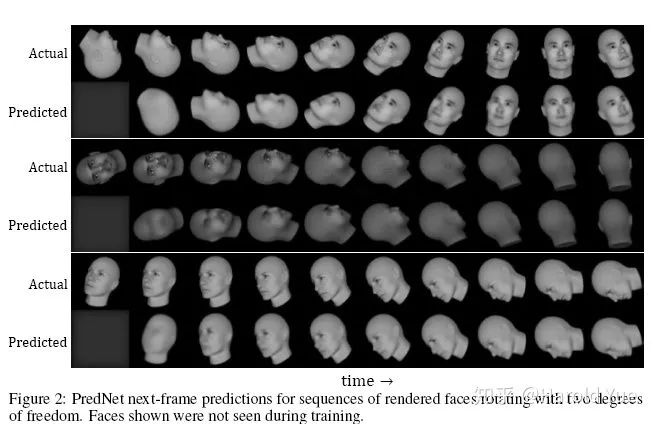
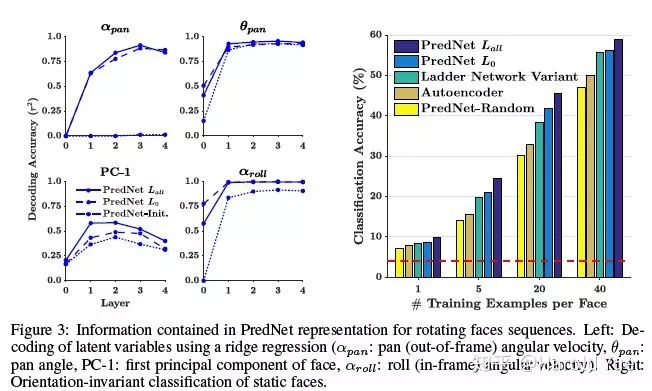
学到的隐藏层表征确实是有意义的,可以拿出来做其他的任务, 如下图7。所以猜测,这样的网络架构,可以学到物体在一些情况下的不变性,如在不同的光照条件下的物体不变性。
第二部分是寻找网络,这个网络可以空间不变的组合特征来对物体进行表示。就想到了之前看到的CapsuleNet,他就有这样的能力。
所以最后的网络结构,应该是,用PredNet 做骨架,而其中卷积的部分用CapsuleNet 代替。
后记:
2019年7月1日 11:28, 终于写完了初稿,看到草稿箱提示我一共8300多字震惊我了。也算是对这半年看的一点东西做了一个小总结。其实感觉这个东西如果真的有效在一些领域会有帮助,比如说零售,尤其是商品识别这块,相比于之前的策略,需要成百上千张同样的商品在不同环境下的照片,现在需要的就是对着商品在不同光照下转几圈,从不同角度采集几段视频可能就可以做到一个还可以的识别准确率。听起来还是挺有吸引力的。
在量子位活动的时候,现场有同学提出了一个比较有趣的点,他提到了Meta-GAN, 原文还没看,大意是一种可以学习物体在不同环境下形态的一种GAN,就觉得十分的赞。因为人脑,可能也是这样的工作的,有一些视错觉的证据或许可以从侧面证明这一点。
抛砖引玉,希望大家多多指教。
Reference:
[1] A Developmental Approach to Machine Learning?
中文译文:机器学习如何借鉴人类的视觉识别学习?让我们从婴幼儿的视觉学习说起
[2] Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning
https://arxiv.org/abs/1605.08104
[3] Capsule Network
[4] MetaGAN: An Adversarial Approach to Few-Shot Learning
http://papers.nips.cc/paper/7504-metagan-an-adversarial-approach-to-few-shot-learning
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~





