【EMNLP2020】基于动态图交互网络的多意图口语语言理解框架
论文名称:AGIF: An AdaptiveGraph-Interactive Framework for Joint Multiple Intent Detection and SlotFillin g 论文作者:覃立波,徐啸,车万翔,刘挺
原创作者:覃立 波 论文链接:https://www.aclweb.org/anthology/2020.findings-emnlp.16 3.pdf 代码链接:https://github.com/LooperXX/A GIF 转载须标注出处:哈工大 SCIR
1. 任务简介

图1 每句话属于一个意图,每个单词属于一个槽位
2. 背景和动机

图2 (a)前人方法将多个意图信息看做一个整体的意图向量进行指导和我们提出的细粒度多意图信息指导方法 (b)
3. 框架
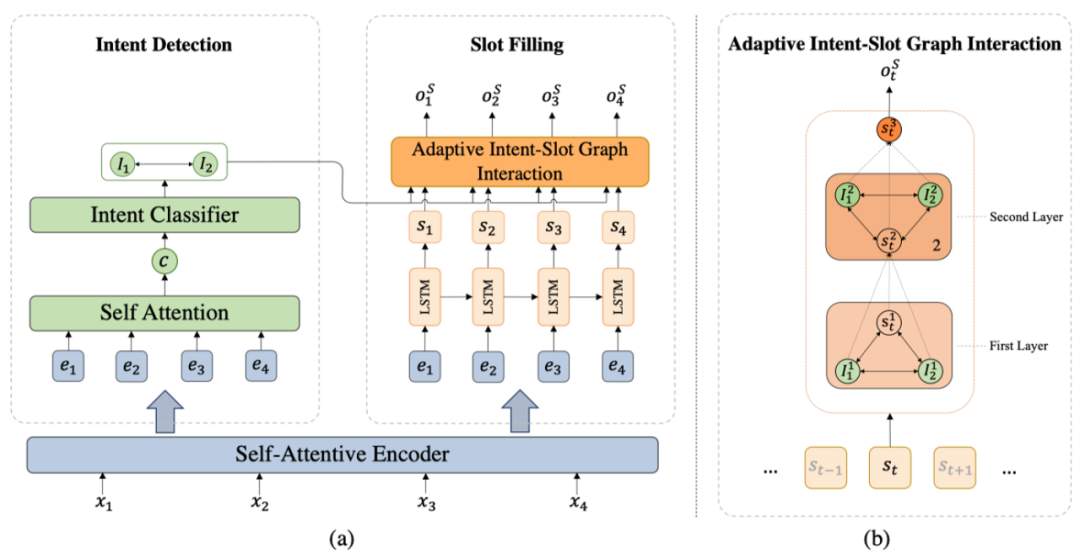
图3 主模型框架
3.1 自我注意力机制的编码器
对于输入序列 首先通过BiLSTM [7] 得到隐层表示 。为了捕获单词之间的上下文信息,我们对于输入序列采用自我注意力机制获得相关表示C,公式如下:
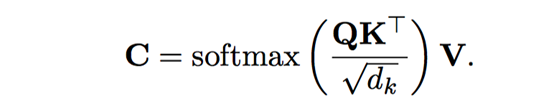
最后我们将H和C进行连接,得到我们最后的编码表示E。
3.2 意图分类
在本文中,我们将意图分类建模为一种多标签分类问题,对于句子编码表示 ,首先利用自我注意机制该句话的句子表示c,公式如下:
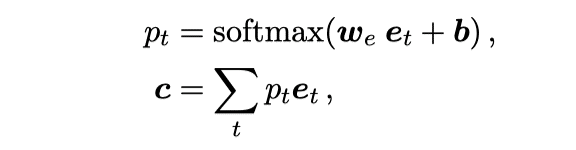
其中 是可学习参数。最终对c进行多标签分类得到结果 (n代表预测的意图个数)。例如,预测的多标签结果为 (0.9, 0.3, 0.6, 0.7, 0.2),阈值为0.5,则最终的意图预测结果为I = (1,3,4)。
3.3 动态交互网络指导的槽位填充
对于槽位填充任务,我们使用一个单向LSTM网络来进行建模,每个位置的状态表示为:
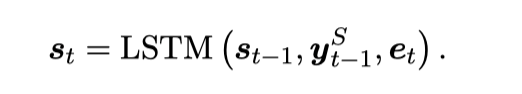
而不是简单的使用 进行槽位预测,我们建立了一个意图-槽位图交互网络去建模当前槽位与多个意图之间的交互,来捕获相关的意图信息,具体而言,我们使用图注意力网络(图中包含当期时刻的槽位状态向量和预测出的多个意图向量结点)去进行建模,最终进行L层交互后的表示 代表已经融入了相关意图的信息,用来进行槽位填充:
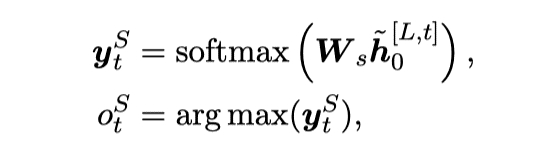
对于意图识别和槽位填充任务,我们采用了联合建模方法来进行建模。
4. 实验
4.1 数据集
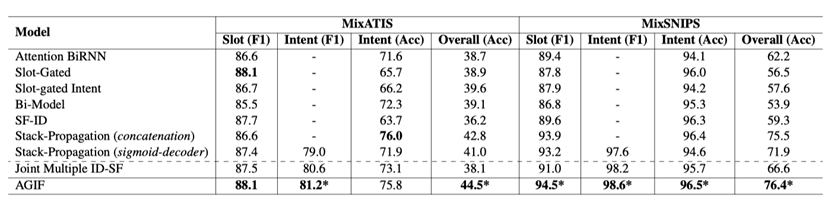
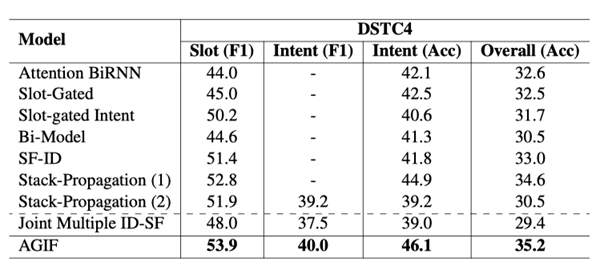
我们在DSCT4 [8]和利用启发式规则构造的MixATIS和MixSNIPS进行了实验。
4.2 主实验结果
我们对比了SLU上的SOTA模型,我们的模型(AGIF)基本上在所有指标超过了其他模型,达到新的SOTA结果,验证了我们模型的有效性。
表1 主实验结果
4.3 消融实验
表2 消融实验结果
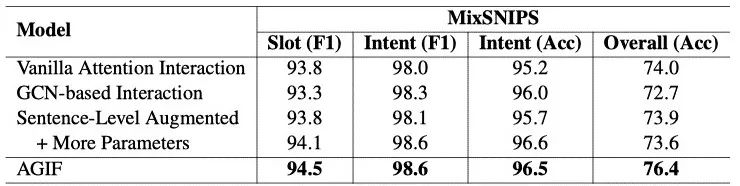
1. Vanilla Attention Interaction代表利用vanilla attention机制进行意图和槽位交互。
2. GCN-based Interaction代表使用GCN而不是GAT进行图交互。
3. Sentence-Level Augmented 代表首先整合多个意图信息到一个向量,然后对每个单词进行相同意图向量的指导。
4.4 可视化分析
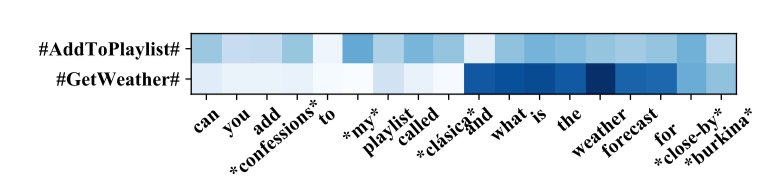
图4 可视化分析
从可视化结果可以看出,模型在不同单词成功捕获到了该单词相关的意图信息。比如播放列表单词clasica在意图AddToPlaylist的颜色比GetWeather深,说明模型在单词clasica正确学到更多的关注AddToPlaylist意图。
5. 结论
在本文中,我们提出了一个单词级自适应图交互网络来建模每个单词与多个意图交互,从而为槽位预测提供细粒度的意图信息。在三个数据集上的实验表明了所提出模型的有效性,并达到了SOTA的性能。
参考文献
[1] Xiaodong Zhang and Houfeng Wang. 2016. A joint model of intent determination and slot filling for spoken language understanding. IJCAI2016.
[2] Chih-Wen Goo, Guang Gao, Yun-Kai Hsu, Chih-Li Huo, Tsung-Chieh Chen, Keng-Wei Hsu, and Yun-Nung Chen. 2018. Slot-gated modeling for joint slot filling and intent prediction. NAACL 2018.
[3] Bing Liu and Ian Lane. 2016. Attention-based recur-rent neural network models for joint intent detection and slot filling. arXiv preprint arXiv:1609.01454.
[4] Changliang Li, Liang Li, and Ji Qi. 2018. A self-attentive model with gate mechanism for spoken lan-guage understanding. EMNLP2018.
[5] Libo Qin, Wanxiang Che, Yangming li, Haoyang Wen and Ting Liu. A Stack-Propagation Framework with Token-Level Intent Detection for Spoken Language Understanding EMNLP2019.
[6] Rashmi Gangadharaiah and Balakrishnan Narayanaswamy. Joint Multiple Intent Detection and Slot Labeling for Goal-Oriented Dialog NAACL2019.
[7] Sepp Hochreiter and J¨urgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8).
[8] Byeongchang Kim, Seonghan Ryu, and Gary Geunbae Lee. 2017a. Two-stage multi-intent detection for spoken language understanding. Multimedia Tools and Applications, 76(9):11377–11390.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MIDS” 就可以获取《【EMNLP2020】基于动态图交互网络的多意图口语语言理解框架》专知下载链接




