赛尔原创 | EMNLP 2019 结合单词级别意图识别的stack-propagation框架进行口语理解
论文名称:A Stack-Propagation Framework with Token-Level Intent Detection for Spoken Language Understanding
论文作者:覃立波,车万翔,李扬名,文灏洋,刘挺
原创作者:覃立波
下载链接:https://arxiv.org/abs/1909.02188
转载须注明出处:哈工大SCIR
1.任务
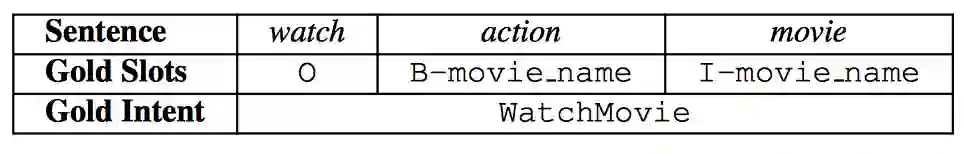
对于句子“watch action movie”,SLU任务识别该句子意图为“WatchMovie”,填充句子中每一个单词的槽位。
2.动机
槽位填充和意图识别两个任务不是相互独立的,槽位填充任务也高度依赖于意图识别的结果[1], 例如,对于句子“watch action movie”,如果预测了该句子的意图为“WatchMovie”,那么每一个单词的槽位更容易识别为电影(movie)相关,而不是音乐(music)相关。很多前人工作将两个任务联合起来建模来充分利用两个任务共有的知识。Zhang [2], Liu [3] 等人采用multi-task框架来联合建模两者之间共享的知识并取得了很好的效果。但是他们的工作没有为槽位填充任务显式的建模意图的信息。近年来Goo [1]和Li [4] 等人采用门控机制来显示给槽位填充任务利用意图信息,尽管他们取得了很好的效果,仍然具有以下不足:(1)他们都是采用门控机制来控制意图信息,在本文中我们表明门控机制不能充分的总结和记住意图信息,并且由于他们框架中槽位填充和意图识别的交互是通过隐藏向量来交互,造成了整个框架的可解释性低。(2)他们都是利用句子级别的意图信息作用给槽位填充任务,可能会导致错误级联问题,一当句子意图识别错误,则会融入错误意图信息,误导所有单词的槽位预测。
为了解决这两个问题,在我们的工作中,我们提出了一个结合单词级别的意图识别机制的Stack-Propagation 框架来解决自然语言理解问题 (SLU)。对于第一个缺点,我们采用stack-propagation框架,直接将意图识别的输出作为槽位填充任务的输入,不仅直接利用了意图的信息来指导槽位填充任务,并在最后实验阶段设计oracle 意图信息的实验来直观的说明意图对于槽位填充的作用,提高了模型可解释性。对于第二个问题,我们创新性的提出单词级别的意图识别机制,对于每一个单词,我们进行意图识别,最终整个句子的意图,通过每个单词的意图结果进行投票决定。进行单词级别的意图识别,然后指导给对应单词的槽位预测可以缓解一定的错误级联问题,因为即使有一些单词的意图预测错误,其它预测正确的单词仍然可以给对应的单词的槽位进行正确的指导。最后,我们在框架中探索了分析了目前比较强的预训练模型BERT [5]。
3.模型
3.1 背景介绍
• 任务介绍
意图识别可以看做是句子的分类任务,识别一个句子的意图
槽填充任务可以看做是序列标注任务,将句子输入序列
转化为对应槽值序列
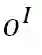
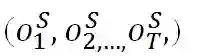
• Stack-Propagation框架与多任务框架比较(如图2)
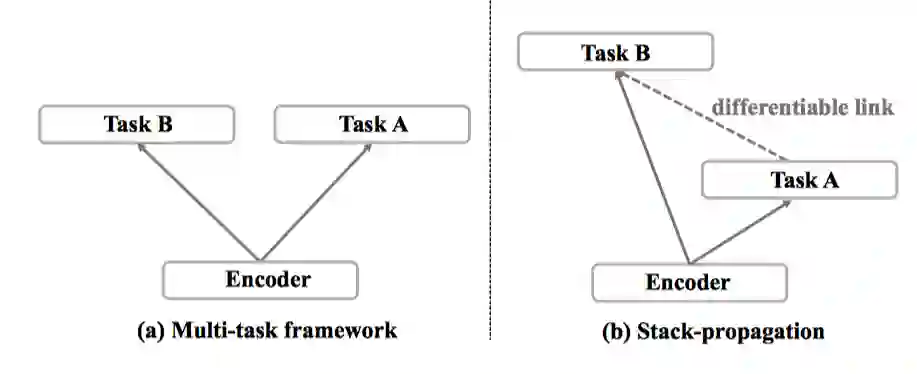
图2 multi-task框架和stack-propagation框架对比图
对于两个相关的任务A和任务B来说,多任务框架(Figure1 (a))可以通过共享的编码器Encoder来学习到两个任务的相关性,但是该框架无法显式将任务A的有用信息传给任务B。对于Stack-propagation框架(Figure (b))来说,则可以弥补这个缺点,任务B可以直接利用任务A的信息,并仍能保证端到端训练,不断微分。
3.2 整体框架
整体框架图如图3:
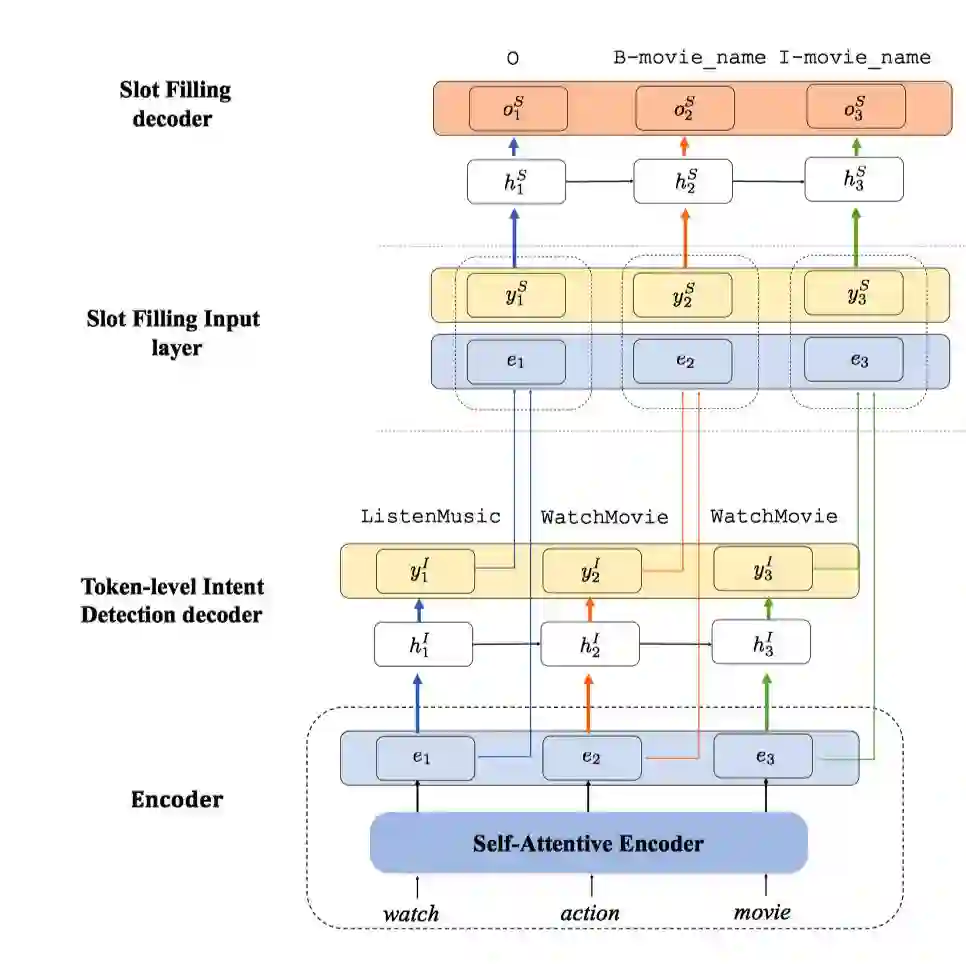
图3 整体模型框架图
3.3 自我注意力机制的编码器
对于输入序列 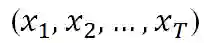
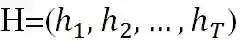
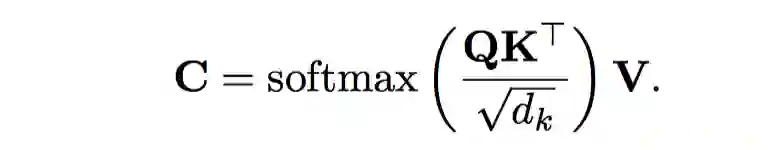
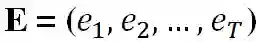 。
。
3.4 意图分类
在本文中,我们将意图分类转化为单词级别的分类任务,对于每一个单词,我们都进行分类。在训练过程,我们将一句话的意图打给每个单词上作为该单词正确的意图标签进行分类。在给定句子的编码表示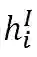
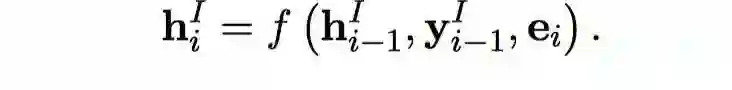
得到,其中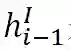
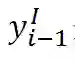

最终整句话的意图结果采用所有单词的投票结果进行决定:
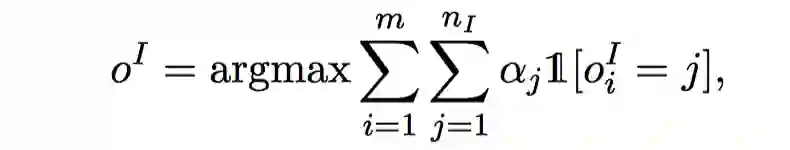
其中m是句子的单词个数,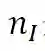
进行单词级别意图分类,主要有以下两个优点:
1.执行单词级别的意图检测可以在我们的框架中为槽填充提供每个单词意图的信息,可以缓解错误传播并保留更多有用的意图信息。与句子级别的意图检测相比,如果整个句子的意图被错误地预测,那么错误的意图可能会对所有单词的槽位预测产生负面影响。但是在单词级别的意图检测中,如果句子中的某些单词被错误地预测,其他正确的单词的意图信息仍可以正确的指导槽位的预测。
3.5 槽填充
对于槽填充任务,类似于意图识别,仍采用单向LSTM作为解码器。对于第i时刻的隐层状态表示如下:
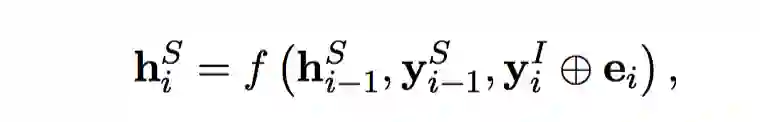
与意图分类不同的是,在槽填充任务中,我们通过stack-propagation框架直接将第i个时刻的意图分类结果

3.6 联合训练
对于意图分类任务,损失函数如下:
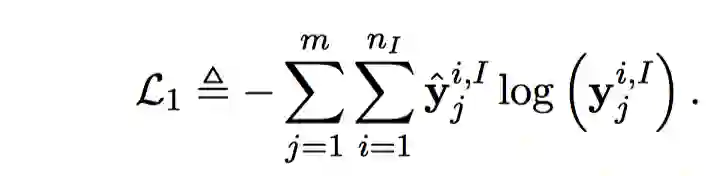
同理,槽填充的损失函数如下:
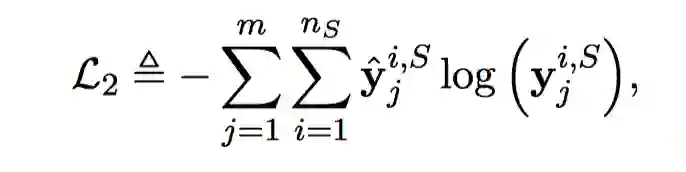
我们将两个loss联合起来更新:
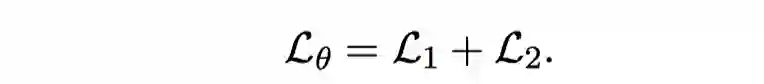
4.实验
4.1 数据集
我们采用公开的ATIS和SNIPS数据集进行试验,训练集,开发集和测试集划分采用[1]的公开标准划分。
4.2 评价指标
对于意图识别,我们采用准确率(Acc)来评价。
对于语义槽填充,我们采用F值来评价。
我们也采用句准确率(Overall Acc)来衡量一句话领域分类、意图识别和语义槽填充的综合能力,即以上三项结果全部正确时候才算正确,其余均算错误。
表1 整体model性能对比表
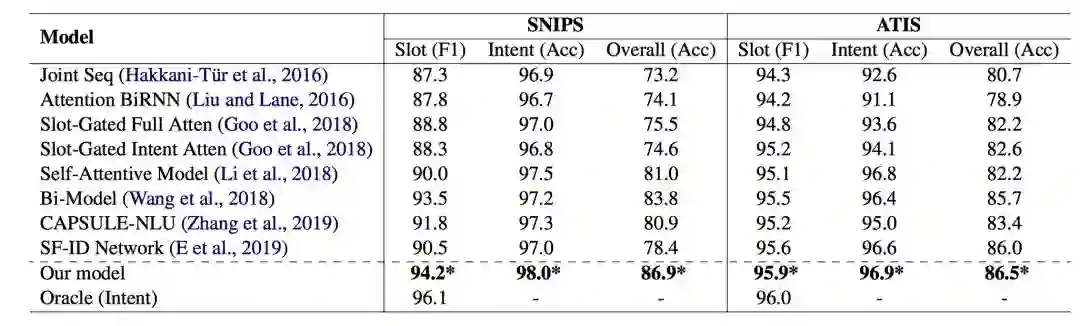
通过表1结果,我们可以看出:
1) 我们的框架达到了state-of-the-art的性能,相比于上一个sota的模型Bi-Model,我们在SNIPS数据集上的overall (acc) 超过了3.1%,在ATIS数据集上超过了0.8%。
2) 通过Oracle的实验,我们给槽填充任务加入了正确的意图one-hot向量信息,可以发现在SNIPS上的Slot信息有1.9%大幅度的提升,在ATIS上也有0.1%的提升,在ATIS上较小的提升结果,我们猜测是ATIS数据集已经达到了很好的性能,所以意图信息的帮助并没有很显著。
4.4 辅助实验
表2 消融实验结果对比表
我们首先验证了单词级别的意图识别效果,单独做了意图识别任务,lstm+token-level代表采用单词级别的意图识别,lstm+last-hidden代表采用lstm的最后一个隐层状态进行分类,通过结果可以发现,单词级别的意图分类要优于句子级别的意图分类结果。对于其他框架机制,我们也进行的消融实验,通过表2可以发现各个模块对最终的性能都有一定的提升效果。
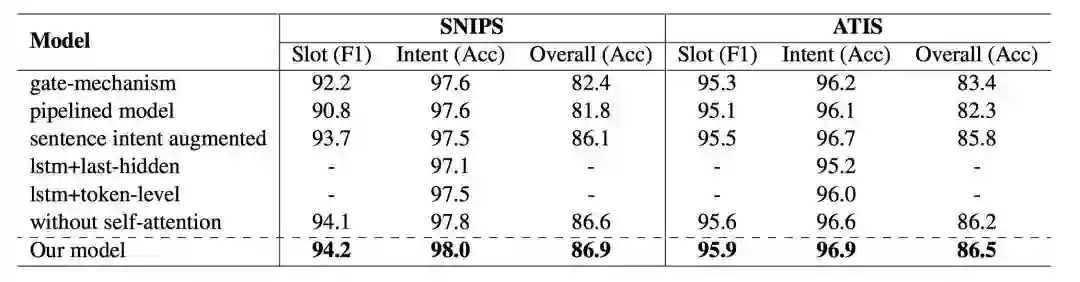
表3 BERT相关实验分析表
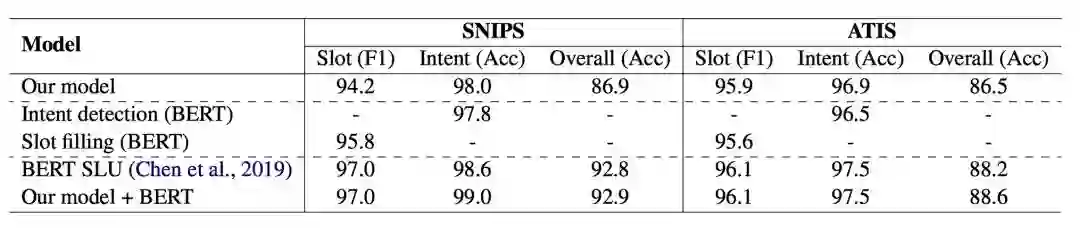
其中Intent detection (BERT), Slot filling (BERT)代表用BERT单独进行两个任务的实验,并没有联合建模。BERT SLU 是chen [7]等人直接将BERT出来的表示进行简单联合建模,没有显式的交互模块。
根据表3可以得到:
1) 在BERT基础上,联合建模意图识别和槽填充任务仍然能够促进两个任务的性能。
2) 显式给槽填充任务利用意图信息能够促进两个任务的表现,并且我们的框架和BERT的作用是相互垂直的,即使在BERT基础上,我们的框架仍然能够超过共享编码层表示的模型。
5.结论
在本文中,我们提出了一种使用Stack-Propagation框架来更好地结合意图信息以进行时槽填充的联合模型,不仅简单有效并且能够直观的体现意图信息是如何作用于槽位预测,提高了模型的可解释性。此外,我们创新性执行单词级别的意图检测,以提高意图检测性能并进一步缓解错误传播。我们在两个公开数据集上进行的实验验证了所提出模型的有效性,并达到了最好的性能。此外,我们探索并分析了的预训练BERT模型纳入SLU任务的效果。在使用BERT的基础上,结果达到了新的最高性能。
参考文献
[1] Chih-Wen Goo, Guang Gao, Yun-Kai Hsu, Chih-Li Huo, Tsung-Chieh Chen, Keng-Wei Hsu, and Yun-Nung Chen. 2018. Slot-gated modeling for joint slot filling and intent prediction. In Proc. of NAACL.
[2] Xiaodong Zhang and Houfeng Wang. 2016. A joint model of intent determination and slot filling for spoken language understanding. In Proc. of IJCAI.
[3] Bing Liu and Ian Lane. 2016. Attention-based recur-rent neural network models for joint intent detection and slot filling. arXiv preprint arXiv:1609.01454.
[4] Changliang Li, Liang Li, and Ji Qi. 2018. A self-attentive model with gate mechanism for spoken lan-guage understanding. In Proc. of EMNLP.
[5] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[6] Sepp Hochreiter and J¨urgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8).
[7] Qian Chen, Zhu Zhuo, and Wen Wang. 2019. Bert for joint intent classification and slot filling. arXiv preprint arXiv:1902.10909.
延伸阅读
赛尔原创 | EMNLP 2019 基于上下文感知的变分自编码器建模事件背景知识进行If-Then类型常识推理
本期责任编辑:丁 效
本期编辑:冯梓娴
“哈工大SCIR”公众号
主编:车万翔
副主编:张伟男,丁效
执行编辑:李家琦
责任编辑:张伟男,丁效,崔一鸣,李忠阳
编辑:赖勇魁,李照鹏,冯梓娴,王若珂,顾宇轩
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号:”哈工大SCIR” 。

