赛尔笔记 | 对比学习简述
作者:哈工大SCIR 侯鹏钰
1. 摘要
基于自监督学习的Bert[1]预训练模型在NLP领域大放光彩,在多项下游任务中均取得很好的效果。Bert在无标注的语料中充分地学到了通用的知识,那么很容易引出一个问题,CV领域是否也可以“复现”Bert的成功呢?近年比较火热的对比学习或许是这个问题的一个答案。
对比学习(Contrastive Learning)是自监督学习的一种,需要从无标注的图像数据中学习特征表示,并用于下游任务中。其指导原则是:通过自动构造相似实例和不相似实例,学习一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。本文将介绍对比学习的基本思路以及经典的MoCo系列[2][3][4]、SimCLR系列模型[5][6],了解对比学习的方法和特性。
2.研究动机
首先自监督学习的定义为:自监督学习属于无监督学习范式的一种,特点是不需要人工标注的类别标签信息,直接利用数据本身作为监督信息,来学习样本数据的特征表示,并用于下游任务。在特征的表示学习中,自监督优势主要体现在以下两点:
无需大量的标注数据,在很多任务例如强化学习中,获取标签所带来的边际成本更高
更关注数据本身的信息,数据本身可以提供比稀疏的标签更多的信息,有监督学习的算法通常需要采用大量样本来学习,并收敛到可能是“脆弱”的结果
可以学习到更通用的知识,相比于特定任务的模型所学到的表示,自监督学习得到的表示通常可以更好的迁移到下游任务中
自监督学习主要分为两大类:生成式(预测式)方法和对比式方法,如下图[7]所示:
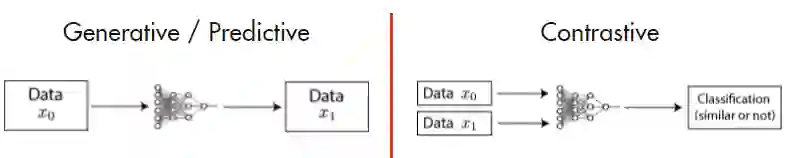
其中生成式方法在NLP领域可以参考Bert的掩码语言模型(MLM,Masked Language Modeling),MLM随机mask掉输入中的部分tokens,目标是通过这些tokens的上下文信息来预测出这些tokens,在CV领域可以参考变分自编码器[8](VAE,Variational Auto-Encoder)和生成式对抗网络[9](GAN,Generative Adversarial Networks),他们通过模型对图像进行编码再解码重构的方式完成训练。而对比式的方法则是将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示。在CV领域,生成式方法更注重于像素级别的重构,这也导致模型所学习的编码更注重于像素的细节,但是通过人的直觉可以认识到,我们记忆和区分事物并不是通过像素级别的特征来区分的,而是通过一些更高级的特征。因此,如何提取更高级的特征并使用其进行区分,成为了对比学习研究的主要目的。
3.对比学习基本思路
其中 被称为锚点数据, 是和 相似的正样本, 是和 不相似的负样本, 是一个度量函数来衡量正负样本的相似度。 函数经常采用欧氏距离、余弦相似度等。
为了优化编码器 ,对比学习一般构造softmax分类器对正样本和负样本进行分类,损失函数此处介绍Info NCELoss,公式如下:
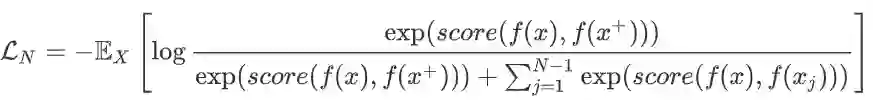
4.模型介绍
4.1 MoCo v1[2]
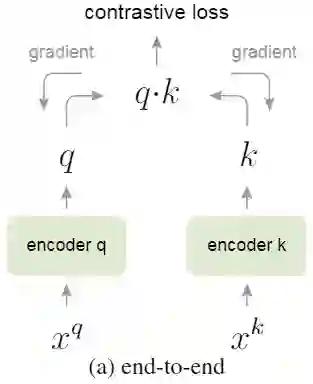
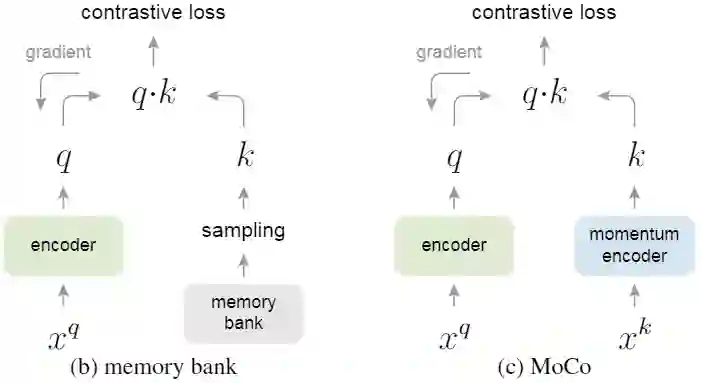
MoCo是由Kaiming He的团队发表在CVPR2020的工作,MoCo通过对比学习的方法,将无监督学习在ImageNet的分类的效果超过有监督学习的性能。MoCo关注的重点是样本数量对学习到的质量的影响。MoCo使用的正负样例生成方法中,正样本生成方法:随机裁剪,生成两个区域,同一张图片的两个区域是正样本,不同图片的两个区域是负样本,即判断两个区域是否为同一张图片。首先介绍简单的end-to-end模型结构,如下图:
4.2 SimCLR v1[5]
SimCLR是由Ting Chen等人发表在ICML2020的工作,与MoCo相比,SimCLR关注的重点是正负样例的构建方式,同时SimCLR还探究了非线性层在对比学习中的作用,并分析了batch_size大小、训练轮数等超参数对对比学习的影响。SimCLR模型结构图如下所示:


4.3 MoCo v2[3]
在SimCLR发表一个月后,Kaiming He等人发表了MoCo v2,主要借鉴了SimCLR中的改动:
改进了数据增强的方法,增加使用blur augmentation来进行增强
在encoder得到表示后添加非线性层等
最终在以更小的batch_size和训练轮数,在ImageNet分类任务上提升超过SimCLR。
4.4 SimCLR v2[6]
SimCLR由Hinton组的Ting Chen在NIPS2020对SimCLR的模型部分做出了如下改进:
相较于SimCLR v1使用的ResNet50(4x),SimCLR v2采用了带有SK的ResNet152(3x),该模型在使用1%的有标签数据进行微调后,性能比ResNet50提高了29%
-
增大了非线性层 的深度,采用了三层的MLP,并且在进行下游任务的迁移时保留了第一层,在SimCLR v1中非线性层仅采用了一层MLP,并且在下游任务中会舍弃掉这一层,该改进在使用1%的有标签数据进行微调后,性能提升14% -
借鉴MoCo中的记忆机制,性能提升1%
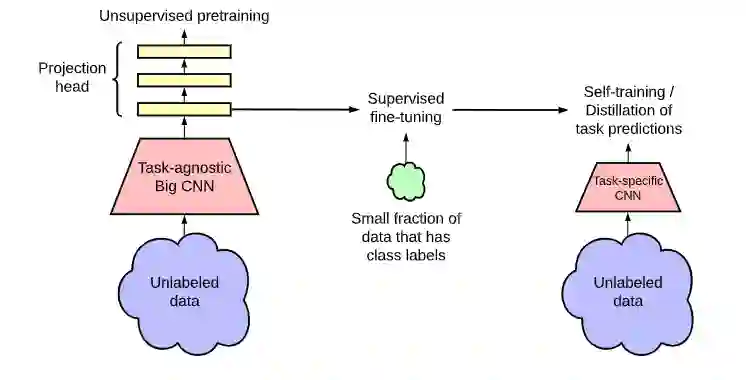
上图的半监督模型展示流程如下:
采用了相较于SimCLR v1更大的并且带有SK的ResNet152(3x)在ImageNet进行对比学习预训练
在小规模有标签的数据进行fine-tuning
通过蒸馏方式在无标签数据进行知识的迁移
最终,作者根据实验结果提出以下结论:
半监督学习的性能受有标签数据规模的影响为:有标签数据规模越少,参数量更大的模型fine-tuning后性能的提升相比参数规模小的模型fine-tuning后的效果大
尽管大模型对于广义特征表达非常重要,但是额外的模型容量对于特征任务而言可能并非必需的
根据调整encoder模型后非线性层的数量,证明了非线性层的重要性,深的非线性层可以提高模型性能
4.5 MoCo v3[4]
终于,在2021年,Kaiming He及其团队在CVPR发布了MoCo v3,尝试使用Visual Transformer(ViT)作为encoder,但是MoCo v3中并不是使用之前改进的memory queue,而是使用SimCLR的large batch。在MoCo v3中,作者的研究回归基础问题,主要解决了对比学习在ViT训练过程中表现出的不稳定性。
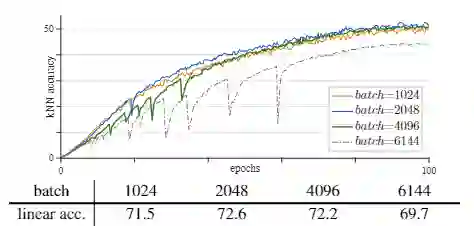
在分析各层梯度变化后,猜测出现这种情况的原因可能是模型中第一层的梯度会出现骤增,作者给出的解决方法是固定模型的patch projection层,并认为该方法并非解决此问题的根本方法,但是使用该“trick”可以一定程度解决训练中出现的不稳定性(在学习率较高时仍会出现这种情况)。
5.总结
本文介绍了对比学习的基本思路和经典模型,并通过介绍MoCo系列和SimCLR系列模型展示了目前对比学习研究的重点。除文章中所介绍的模型外,近年来提出的SwAV[10]模型将聚类方法引入训练过程、只采用正例进行对比学习的BYOL[11]及SimSiam[12]、以及在NLP领域使用对比学习的SimCSE[13]等,都值得深入学习和讨论,篇幅原因此处不详细展开,期待更多创新性的工作来提升对比学习的性能。
参考资料
Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[2]He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[3]Chen, Xinlei, et al. "Improved baselines with momentum contrastive learning." arXiv preprint arXiv:2003.04297 (2020).
[4]Chen, Xinlei, Saining Xie, and Kaiming He. "An empirical study of training self-supervised visual transformers." arXiv preprint arXiv:2104.02057 (2021).
[5]Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." International conference on machine learning. PMLR, 2020.
[6]Chen, Ting, et al. "Big self-supervised models are strong semi-supervised learners." arXiv preprint arXiv:2006.10029 (2020).
[7]Contrastive Self-Supervised Learning https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html
[8]Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).
[9]Goodfellow, Ian J., et al. "Generative adversarial networks." arXiv preprint arXiv:1406.2661 (2014).
[10]Caron, Mathilde, et al. "Unsupervised learning of visual features by contrasting cluster assignments." arXiv preprint arXiv:2006.09882 (2020).
[11]Grill, Jean-Bastien, et al. "Bootstrap your own latent: A new approach to self-supervised learning." arXiv preprint arXiv:2006.07733 (2020).
[12]Chen, Xinlei, and Kaiming He. "Exploring Simple Siamese Representation Learning." arXiv preprint arXiv:2011.10566 (2020).
[13]Gao, Tianyu, Xingcheng Yao, and Danqi Chen. "SimCSE: Simple Contrastive Learning of Sentence Embeddings." arXiv preprint arXiv:2104.08821 (2021).



