
卷积神经网络(cnn)在计算机视觉任务中表现出了出色的性能,尤其是分类任务。为了在真实场景中增加鲁棒性或赢得Kaggle竞赛,cnn通常会采用两种实用策略:数据增强 和模型集成 。
数据增强可以减少过拟合并提升模型的泛化性。传统的图像增强是保留标签的:例如翻转、裁剪等。然而,最近的混合样本数据增强(MSDA)改变了这种方式:多个输入和它们的标签按比例混合来创建人工样本,代表工作有MixUp,CutMix等等。
模型集成证明了聚合来自多个神经网络的不同预测能够显著提高了泛化能力,尤其是不确定性估计。从经验上讲,几个小网络的集成通常比一个大网络性能更好。然而,在训练和推理方面,集成在时间和显存消耗方面都是昂贵的:这往往限制了模型集成的适用性。
在本文,作者提出了多输入多输出框架MixMo。为了解决传统集成中出现的这些开销,作者将M个独立子网放入一个单一的base网络中。这也是合理的,因为在模型集成时,“最终采纳的网络”其实就和整体的网络表现差不多。
所以,现在最大的问题是如何在没有结构差异的情况下加强subnet之间的多样性。
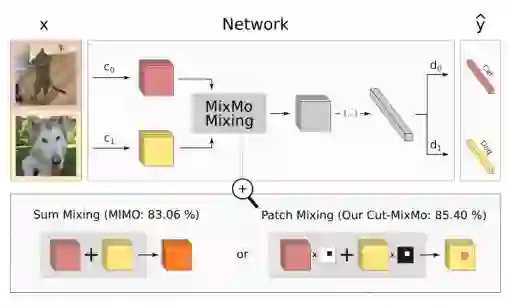
如上图,作者在训练过程中同时考虑了M个输入,M个输入被M个参数不共享的Encoder编码到共享空间中,然后将特征送到核心网络,核心网络最终分成M个分支;这个M个分支用来预测不同输入信息的label。在inference的时候,同一图像重复M次:通过平均M个预测获得“免费”的集成效果。
与现有的MSDA相比,MixMo最大的不同就是multi-input mixing block。如果合并是一个基本的求和,MixMo将变成到MIMO[1]。作者对比了大量的MSDA的工作,设计了更合适的混合块,因此作者采用binary masking的方法来确保子网络的多样性。(如上图所示,作者对不同样本采用了一个binary masking方法,这一点就类似CutMix,而不是像MIMO那样直接相加 )。
这种不对称的混合也会造成网络特征中的信息不平衡的新问题,因此作者通过一个新的加权函数来解决多个分类训练任务之间的不平衡问题。
