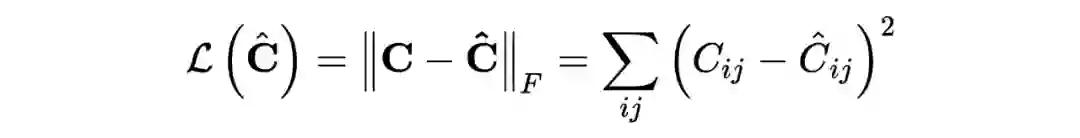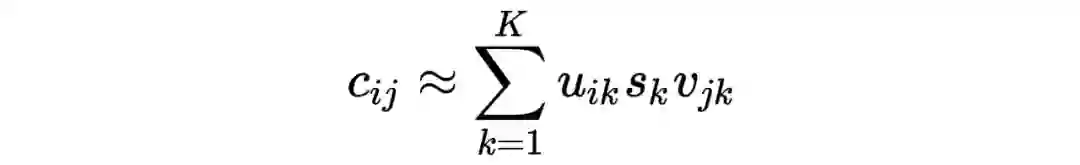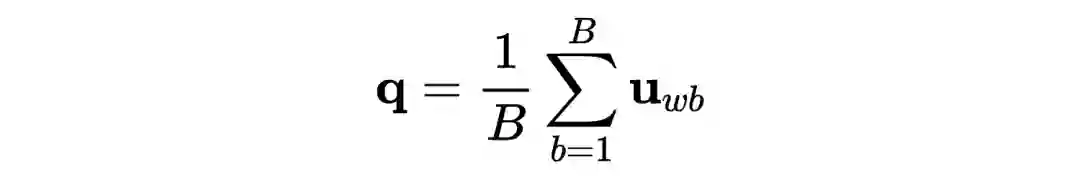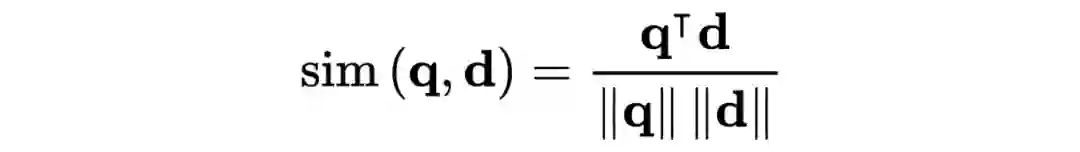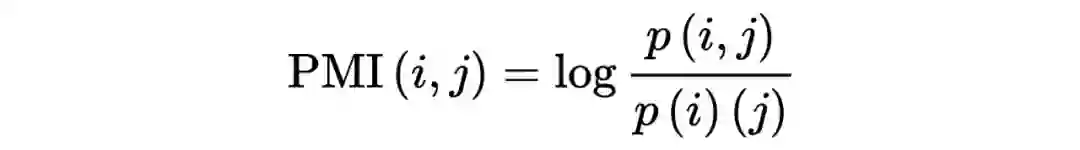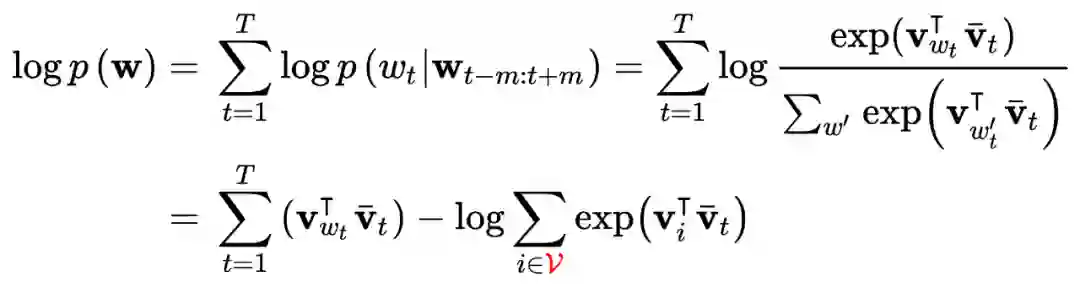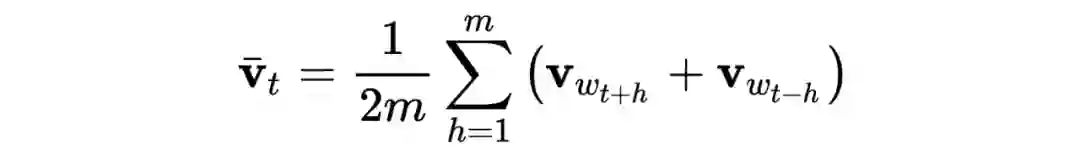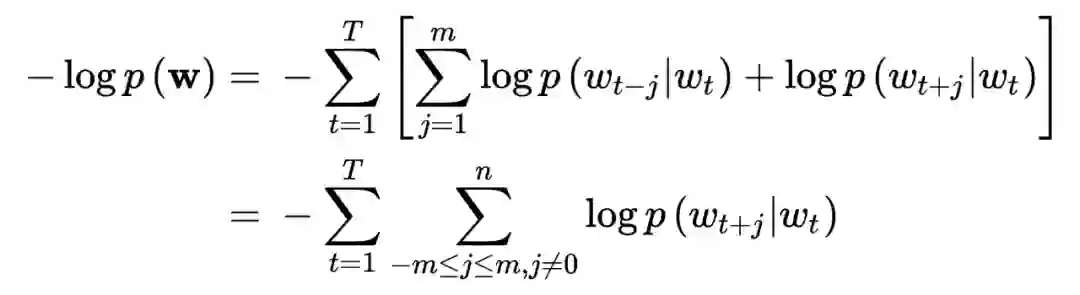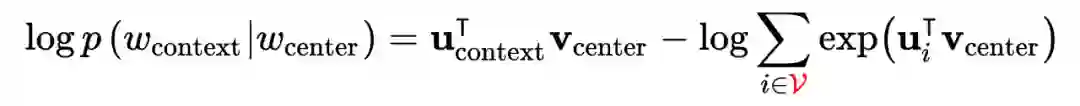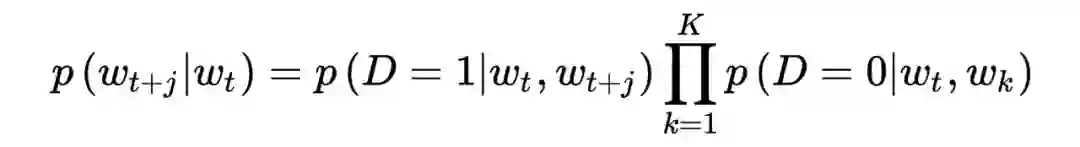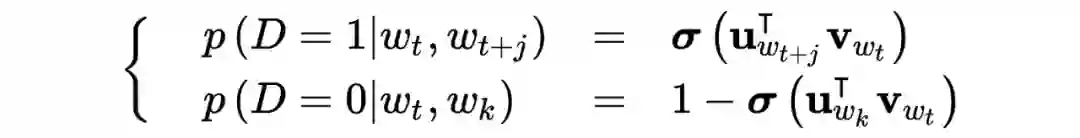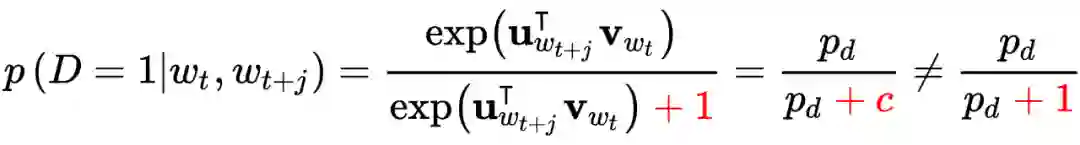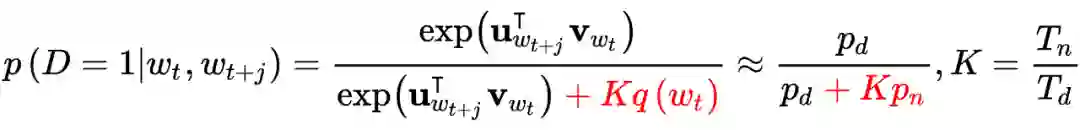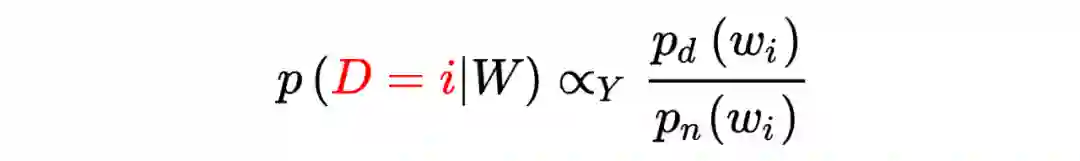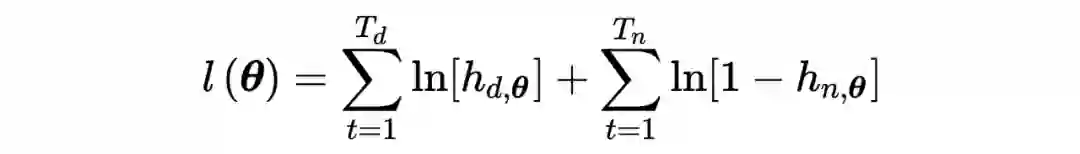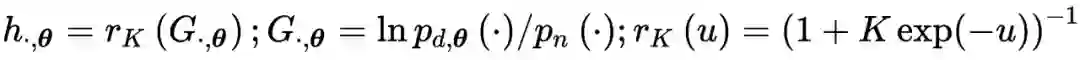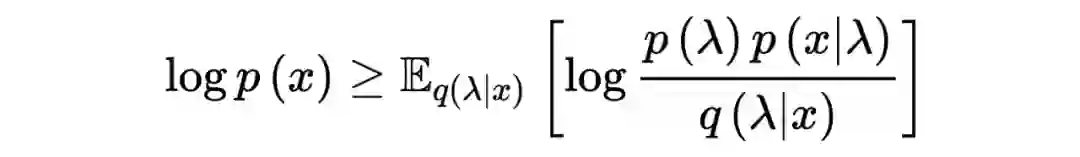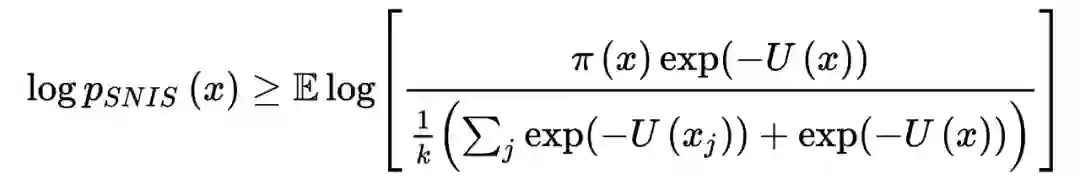![]()
负采样
(Negative Sampling, NEG)/噪声对比估计(Noise Contrastive Estimation, NCE)/生成对抗网络(Generative adversarial networks, GAN)/自监督学习(Self-supervised learning, SSL)是自然语言处理、推荐系统中常见的技术,它们各有特点而又联系密切。
本文将从自然语言处理的背景切入,按照以下逻辑,层层递进,介绍这些方法的实现区别与内在联系:
词嵌入(Word embedding)
对于单词或者商品这样的随机变量空间,通常它们的 one-hot 表达都是高度稀疏的。标准的处理方法是使用词嵌入(word embedding)技术。负采样最初是针对词嵌入学习中存在的困难,所发展出的一种构造样本的方法。词嵌入的目标,是学习得到这样一个语义空间:
具体地,需要将第
个文档中的第
个单词,表示为高维、稀疏的 one-hot 向量
。将其映射到一个低维、稠密的
空间上去。
所谓语义,是由分布假设(distributional hypothesis)所定义的。这个假设是指:具有相似上下文 (context) 的单词,往往具有相似的含义;两个单词的差异程度,大致上对应于在它们环境的差异程度。
![]()
隐语义索引(LSI)/ 隐语义分析(LSA)/ 点间互信息(PMI)
隐语义索引
(Latent semantic indexing, LSI)是最直接的利用统计特征,建立词嵌入空间的方法。
首先建立矩阵
,其中矩阵元素
表示第
种「条目(term)」出现在第
种「上下文(context)」的统计次数。条目和上下文的定义都可以按照实际需要,自由定制。如果以「单词」作为「条目」,以「文章」作为「上下文」,则这样的矩阵又叫做词条-文档频率矩阵(term-document frequency matrix)。
词与词直接必然存在千丝万缕的联系,这也意味着词条-文档频率矩阵一定是一个低秩矩阵,通过与推荐系统中完全一样的方法:
https://zhuanlan.zhihu.com/p/408838233
![]()
![]()
其中
为第
个单词的嵌入,而
表示第
个文档的嵌入。利用这些嵌入,可以实现文档检索(document retrieval)。例如每一次查询内容为:
![]()
可以直接通过欧式距离,或者余弦相似度来实现对文档的排序:
![]()
隐语义分析
(Latent semantic analysis, LSA)是隐语义索引的推广。将作为上下文的文档,替换成单词附近的滑窗
,其余的计算与隐语义索引中的完全相同。
点间互信息
(pointwise mutual information, PMI)将隐语义分析中的单纯计数
替换成互信息的形式:
![]()
将 PMI 矩阵中的负值全部置零,就得到 positive PMI (PPMI)模型。然而 PPMI 也具有偏置的问题:对于罕见词的评分非常高。使用拉普拉斯平滑(Laplace smoothing)可以一定程度上缓解这个问题。
![]()
词向量(Word2vec)
词向量模型大致分为两种类型:CBOW(continuous bag of words)与 skipgram。Word2vec 有一个很强(但有效)的假设:
![]()
CBOW 模型
![]()
其中
是整个词库,
是滑窗尺寸,
是中心词,
是上下文:
![]()
![]()
Skip-gram 模型
![]()
则与 CBOW 类似,可以将给定中心词,对应上下文的条件概率为:
![]()
![]()
负采样(Negative sampling, NEG)
不论是对于 CBOW 还是 Skip-gram 模型,都需要遍历整个词库
,这种计算代价在实际中是不可承受的。为了节省运算量,加速训练,需要使用负采样方法。结合负采样之后的 Skip-gram 模型称为 SGNS 模型(skip-gram with negative sampling)。
具体来说,对于每个中心词
,将其上下文的单词中选择 1 个作为正样本;负样本又被称为噪声词(noise words),以
,
的概率从词库中抽取
作为个负样本,这样构造负样本是为了让更多的罕见词获得训练的机会。由此待求条件概率为:
![]()
由此只需要用随机梯度下降法,训练一个二分类模型即可:
![]()
可以看到,在每一组样本的计算过程中,已经不需要遍历整个词库
。
![]()
负采样(NEG) 是对噪声对比估计(NCE)的近似
负采样引入了噪声词,通过训练二分类模型,来避免对整个词库
的反复遍历。然而需要注意的是,当且仅当
,且噪声词为均一分布时,使用负采样才能得到中心词的似然函数。而按照 SGNS 的设计,负样本窗口必然是远远小于词库尺寸的,这将导致一个严重的缺陷:
由负采样得到的模型只能用于生成词嵌入,而不能生成语言模型
![]()
噪声对比估计(NCE)是重要性采样(IS)的特例
同样是将概率估计问题转化为二分类问题,唯一的不同是 NCE 利用了已知的噪声概率分布,来估计未知的经验概率分布。这种思想与重要性采样(Importance Sampling, IS)异曲同工,唯一的不同是 NEG / NCE 是通过逻辑回归(logistic regression)对数据与噪声进行二分类;IS 是通过交叉熵(cross entropy)进行多分类。三者的区别与联系一目了然:
![]()
在 NCE 中(约等号是因为配分函数
直接置 1):
![]()
![]()
![]()
![]()
从而可以构造出相应的损失函数,最终估计出经验概率密度函数
。
![]()
噪声对比估计(NCE)是对极大似然估计(MLE)的近似
与 MLE 一样,可以证明 NCE 满足渐近正态性(asymptotic normality):
![]()
而 MLE 还同时满足渐近有效性(asymptotic efficiency):
![]()
并以及在此基础上还满足一致性(consistency):
![]()
从可以证明当
,NCE 的 Cramér–Rao bound(CRB)同样收敛至
,
为费雪信息(Fisher information),因此实际应用中
也应选取得尽量大。
上述事实说明,在考虑配分函数(partition function)的情况下,NCE 的方差渐近收敛于 MLE,因而同样满足渐近有效性以及一致性,这也是 NCE 方法之所以成立的重要理论保证。由于配分函数实际上无法计算,在 NCE 公式中直接置为 1,因此是 MLE 的近似结果,这种方法称之为自归一化(self-normalisation)。
对于未知分布的估计问题,是典型的无监督学习(unsupervised learning)任务,而通过 NCE / NEG,用有监督学习(supervised learning)方法实现了这样的目的,从而建立了无监督学习与有监督学习的桥梁,这就是自监督学习(Self-supervised learning, SSL)。
![]()
噪声对比估计(NCE)是生成器(generator)固定的生成对抗网络(GAN)
在 NCE 中噪声样本
越接近
,似然函数越大。当完全相等时,取得最大值。直观上也很容易理解:分布越接近,对于模型的分辨难度越大,从而越能够更好学习到经验分布。
在 TensorFlow 代码中,噪声分布默认使用 Zipfian 分布。因此使用时要按词频进行排序,来获得最佳性能。
到目前为止,噪声分布都由事先指定,而正如前文指出的,由于 NCE 是 MLE 的近似,样本规模的扩大,可以减弱噪声分布偏离带来的不利影响。而近年来风靡一时的生成对抗网络(Generative adversarial networks, GAN),实质上是进一步放松了对噪声分布的限制,而由生成器(generator)来直接生成噪声样本。
![]()
InfoNCE 的是多分类版本的噪声对比估计(NCE)
在 NCE 方法中,引入噪声分布,对噪声和正样本通过逻辑回归进行了二分类学习,从而最终得到经验分布。容易想到,可以将 NCE 的考察对象从二分类扩展到多分类;将计算方式由逻辑回归推广到交叉熵:
![]()
这种损失函数被称之为 InfoNCE 或 ranking NCE。
当下流行的对比学习(contrastive learning)是自监督学习(Self-supervised learning, SSL)的一种。InfoNCE 及其变体被广泛用于各种对比学习的损失函数中,其中比较著名的模型有如 SimCLR / MoCo / SimCSE 等。
![]()
基于能量模型(EBM)与能量启发模型(EIM)
基于能量模型(Energy-based model, EBM)是一种统一的学习框架,用于图模型及其他结构化模型的训练。常见的 EBM 模型有玻尔兹曼机(Boltzmann machines)、条件随机场(conditional random fields)、马尔科夫随机场(Markov random fields)等等。EBM 由于配分函数的计算,使得采样和估计都比较困难。
能量启发模型
(Energy-Inspired Models, EIM)则另辟蹊径,通过采样方法,提供容易计算的似然函数的下界(lower bounds),来进行近似。
![]()
InfoNCE 实质上是在做自归一重要性采样(SNIS)
![]()
其中
为先验分布,
为难以计算的配分函数。通过引入隐变量
和变分分布
,可以得到:
![]()
KL 散度的一项可以放缩丢弃,以
为采样不确定性,则有:
![]()
重要性采样
(importance sampling, IS)是通过引⼊⼀个辅助的概率密度函数,来减少蒙特卡洛⽅法的⽅差。配分函数未知的情况下,采用自归一重要性采样(Self-Normalized Importance Sampling, SNIS):
![]()
![]()
![]()
将 SNIS 作为变分分布,带入上式,可以得到这样的观点:
InfoNCE 是通过自归一重要性采样,来优化互信息的下界
至此,从能量观点,建立了对从负采样到对比学习的统一认识。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()